
Just Loki @LokiJulianus
Prince With a Thousand Enemies Nod Joined April 2016-
Tweets68K
-
Followers66K
-
Following311
-
Likes51K
The $15 “silver” chain race.

The $15 “silver” chain race.

Oh this LLLMM? It’s just predicting the next language model

meta did the funniest thing

> "I think it's time to admit defeat" How often do you see LLMs capitulate instead of doubling down or gaslighting you? Sadly 8B Llama is struggling with The Diamond Problem (as do all <10B models that don't cheat egregiously), but its attitude sure is more human-like now.

> "I think it's time to admit defeat" How often do you see LLMs capitulate instead of doubling down or gaslighting you? Sadly 8B Llama is struggling with The Diamond Problem (as do all <10B models that don't cheat egregiously), but its attitude sure is more human-like now. https://t.co/825CTekSv5
In fairness to the lisp machine people: most higher level languages cannot easily implement a full common lisp interpreter even today and not for lack of trying.

In fairness to the lisp machine people: most higher level languages cannot easily implement a full common lisp interpreter even today and not for lack of trying.

He’s change his instagram name to Zuck lol.
And just like that.




Yes, both the 8B and 70B are trained way more than is Chinchilla optimal - but we can eat the training cost to save you inference cost! One of the most interesting things to me was how quickly the 8B was improving even at 15T tokens.

Yes, both the 8B and 70B are trained way more than is Chinchilla optimal - but we can eat the training cost to save you inference cost! One of the most interesting things to me was how quickly the 8B was improving even at 15T tokens.

Llama 3 70B never stopped learning. He says the only reason they stopped its training was that they eventually had to decide: 'Do we want to spend our GPUs on training the 70B model further?' or should we start training what's next?


Llama 3 70B never stopped learning. He says the only reason they stopped its training was that they eventually had to decide: 'Do we want to spend our GPUs on training the 70B model further?' or should we start training what's next? https://t.co/NohXjF2TaH

meta ai finally solved the slopism problem

>is it MoE or dense? >haha, it's a good model sir >it's dense

Mistral-7B is dead.



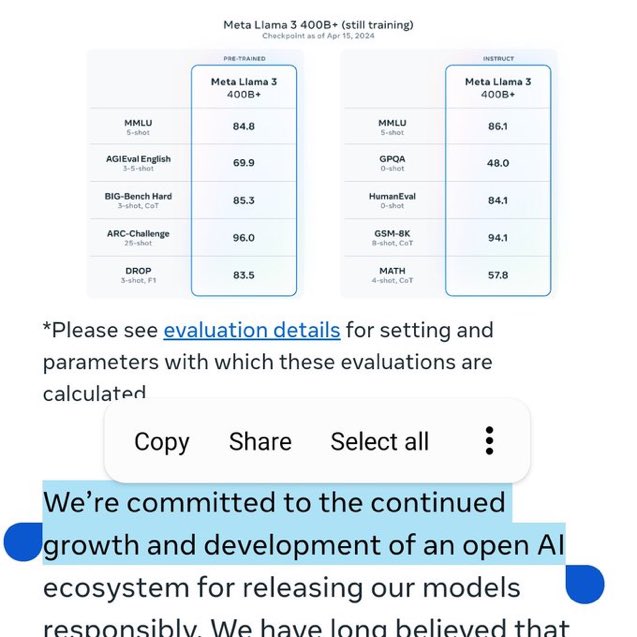
Llama 3 has been my focus since joining the Llama team last summer. Together, we've been tackling challenges across pre-training and human data, pre-training scaling, long context, post-training, and evaluations. It's been a rigorous yet thrilling journey: 🔹Our largest models…


Lads, are we finally free of the debt inherited by OAi's decision to not open source gpt-3...

Lads, are we finally free of the debt inherited by OAi's decision to not open source gpt-3...

llama-3-70B is as good or better than sonnet but ~10x cheaper, about as cheap as Haiku. Llama has just demolished everything below gpt-4 level


Hearing feedback from the community about the adverse impacts of false refusals, we developed new mitigations to address this. Llama 3 70B exhibits less than a third of the false refusals of Llama 2 70B, making Llama 3 our most helpful model to date.

I wish Twitter had a way to send all the people calling me antisemitic for talking about Palestine to the same place as the people calling me a genocide supporter for saying that blocking traffic is a stupid tactic, so they could argue with one another instead of me.

Congrats to @AIatMeta on Llama 3 release!! 🎉 ai.meta.com/blog/meta-llam… Notes: Releasing 8B and 70B (both base and finetuned) models, strong-performing in their model class (but we'll see when the rankings come in @ @lmsysorg :)) 400B is still training, but already encroaching…
Llama 3 delivers a major leap over Llama 2 and demonstrates SOTA performance on a wide range of industry benchmarks. The models also achieve substantially reduced false refusal rates, improved alignment and increased diversity in model responses — in addition to improved…



Zero HP Lovecraft �.. @0x49fa98
133K Followers 1K Following You could lose weight. Let no one reduce us to the status of ascetics. There is no pleasure more complex than that of thought.
Bronze Age Pervert @bronzeagemantis
145K Followers 11K Following Aspiring Nudist Bodybuilder. Free speech and anti-xenoestrogen activist. Get my book! https://t.co/h9dELQZ9tT
Second City Bureaucra.. @CityBureaucrat
95K Followers 3K Following Opposition Activist challenging hegemonic worldviews. .Chief of the Ethnonarcissism Police. SATIRE
Dr. Ben Braddock @GraduatedBen
96K Followers 4K Following South x West // Commissioning Editor: @im_1776
Beachstud90210 @KhalkeionGenos
54K Followers 68 Following Opposition activist. National nudism. Anti-xenoestrogen awareness. Militant radical Hellenism. Free Tibet
Bennett's Phylactery @extradeadjcb
68K Followers 2K Following The unnaturally preserved head of Doctor John Cook Bennett. https://t.co/hUx5pzQuAK

Covfefe Anon @CovfefeAnon
64K Followers 929 Following Not to be confused with 2001 Nobel Peace Prize winner Kofi Annan. 54th Clause of the Magna Carta absolutist. Commentary from an NRx perspective.
eugyppius @eugyppius1
62K Followers 869 Following "Science denialist" -Chelsea Clinton. retweets = hard agree. indifferent to the suffering of the out-group. overcoming leftism is the challenge of our age.
Lomez @L0m3z
55K Followers 2K Following "A good boy. Senile bookcel. Physically fit. And basically normal.”

owen cyclops @owenbroadcast
72K Followers 2K Following illustrator at the intersection of starting a family, weird american religion, and having a dog. a lot more stuff and comix here: https://t.co/uzxC71XMGI
ɖʀʊӄքǟ ӄʊռʟ.. @kunley_drukpa
64K Followers 3K Following 𝙿𝚛𝚎𝚜𝚜 @ ℝ𝕖𝕡𝕦𝕓𝕝𝕚𝕔 𝕠𝕗 ℂ𝕙𝕒𝕕 || ʟᴇᴠᴇʟ-ʜᴇᴀᴅᴇᴅ ᴀɴᴅ ᴄʀᴇᴅɪʙʟᴇ ᴀᴄᴄᴏᴜɴᴛ || འབྲུག་
🥂 marquis de posad.. @acczibit
41K Followers 1K Following propagate. accelerate. concentrate. separate. debilitate. annihilate. exhilarate.

🇻🇦Gio's Content.. @giantgio
40K Followers 1K Following artist/writer/podcaster/content dealer. Gonzo philosopher, PoMo Right, Jungian futurist. Content Minded pod. https://t.co/UtUUzgHHFB
Doctor-Baron 17cShyte.. @17cShyteposter
42K Followers 538 Following The blue check was the modern day Mark of Cain.

William Wheelwright @ploughmansfolly
42K Followers 560 Following Minerva inspires me, Apollo is my pilot, and the Nine Muses have shown me The Bears
stricture @bog_beef
33K Followers 1K Following A washed up private dick, alone in a city of sleaze. "S-Ranked Southern Gamer" -Vanity Fair #PatronagePilled #PatronageTheory
spill @spillirks
39 Followers 335 Following
ibarahem Ahmadi @AhmadiIbar10223
331 Followers 82 Following iam a student english language and job atlas


ʙʀᴏɴᴢᴇ ᴀɢ.. @jacoburowsky
6K Followers 311 Following What is great in man is that he is a bridge and not a goal


Dean Banks @ItsDeanBanks
200 Followers 851 Following
Hb @Hb4162848576455
0 Followers 21 Following
HarveDeGuerre @HarveDe50030
72 Followers 332 Following
We❤️LizardPeople @welovelizardppl
62 Followers 543 Following Just because it's dark outside doesn't mean you get to walk around with your eyes closed.
Gerald Fienbeck @GFienbeck
70 Followers 513 Following
schadenfreude @schadenfreude63
9 Followers 58 Following
Michael Golden @michaelgold3n
964 Followers 2K Following AI research @ucsandiego | accurate AI detection for institutions @ IntegrityAI 🚀 prev. guest student @stanford host @airbnb
Rachel Sclieur @RachelSclieur
0 Followers 50 Following
Steve Smith @SRSMITH555
122 Followers 198 Following
LibertyUnTerrified @LibertasAeter
1 Followers 13 Following

mathu piccu @MattWearsPants
61 Followers 127 Following Why did you do this to me, for what reason, what is the charge? Eating a meal? A succulent chinese meal?
Matt Shaw @sha57719167
404 Followers 831 Following
Shane_Williams @Shane_Willians
12 Followers 411 Following
Rebecca Allodi @rasputinsbot
43 Followers 684 Following
RScotty88 @ScottyL88
8 Followers 146 Following Outdoorsman. For work and for play. Collect glass tanks and fill them with fish and plants.. Bit of a novice noticer.
Dustin Plotnick @DustinPlotnick
0 Followers 497 Following
Ibo @Iboglob
26 Followers 296 Following
NunmalZufälligKommun.. @NunmalKommunist
17 Followers 76 Following 5er wenn man mir StaMoKap verständlich macht
Lawton Kane @LostCamellias
2 Followers 58 Following

𝔖𝔞𝔵𝔬 𝔊.. @SaxoGermanicus
5 Followers 70 Following Anglo-German fitness enthusiasts and third world extinction advocate. 🇩🇪🏴 Solar cultist and avowed enemy of Jehova 🤚🏻☀️


Bassaces @Bassaces1
2K Followers 5K Following
Meditate With Nate @Nate_Meditates
291 Followers 680 Following Convert to The Church of Jesus Christ of Latter-day Saints. Here to meditate on the Scriptures & use them to help guide me & my followers thru life.

openriot @openRiot
271 Followers 2K Following


Jeremy Farber @jfarber
11 Followers 333 Following
The Kid— e/acc @saguaromister
5 Followers 536 Following



Piotr Nowak @sk1908rdg
722 Followers 2K Following
Aneta6666 @aneta6666
222 Followers 2K Following
Jonathan Fry @ditchmaninhole
1 Followers 43 Following
Zero HP Lovecraft �.. @0x49fa98
133K Followers 1K Following You could lose weight. Let no one reduce us to the status of ascetics. There is no pleasure more complex than that of thought.
Bronze Age Pervert @bronzeagemantis
145K Followers 11K Following Aspiring Nudist Bodybuilder. Free speech and anti-xenoestrogen activist. Get my book! https://t.co/h9dELQZ9tT
Second City Bureaucra.. @CityBureaucrat
95K Followers 3K Following Opposition Activist challenging hegemonic worldviews. .Chief of the Ethnonarcissism Police. SATIRE
Dr. Ben Braddock @GraduatedBen
96K Followers 4K Following South x West // Commissioning Editor: @im_1776
Steve Sailer @Steve_Sailer
121K Followers 1K Following My pronouns, like Stalin's, are Who vs. Whom. Pre-order my anthology "Noticing" in paperback for $29.95: https://t.co/VpzBKeEO89
Beachstud90210 @KhalkeionGenos
54K Followers 68 Following Opposition activist. National nudism. Anti-xenoestrogen awareness. Militant radical Hellenism. Free Tibet
Bennett's Phylactery @extradeadjcb
68K Followers 2K Following The unnaturally preserved head of Doctor John Cook Bennett. https://t.co/hUx5pzQuAK
Covfefe Anon @CovfefeAnon
64K Followers 929 Following Not to be confused with 2001 Nobel Peace Prize winner Kofi Annan. 54th Clause of the Magna Carta absolutist. Commentary from an NRx perspective.
eugyppius @eugyppius1
62K Followers 869 Following "Science denialist" -Chelsea Clinton. retweets = hard agree. indifferent to the suffering of the out-group. overcoming leftism is the challenge of our age.
Lomez @L0m3z
55K Followers 2K Following "A good boy. Senile bookcel. Physically fit. And basically normal.”
owen cyclops @owenbroadcast
72K Followers 2K Following illustrator at the intersection of starting a family, weird american religion, and having a dog. a lot more stuff and comix here: https://t.co/uzxC71XMGI
ɖʀʊӄքǟ ӄʊռʟ.. @kunley_drukpa
64K Followers 3K Following 𝙿𝚛𝚎𝚜𝚜 @ ℝ𝕖𝕡𝕦𝕓𝕝𝕚𝕔 𝕠𝕗 ℂ𝕙𝕒𝕕 || ʟᴇᴠᴇʟ-ʜᴇᴀᴅᴇᴅ ᴀɴᴅ ᴄʀᴇᴅɪʙʟᴇ ᴀᴄᴄᴏᴜɴᴛ || འབྲུག་
🇻🇦Gio's Content.. @giantgio
40K Followers 1K Following artist/writer/podcaster/content dealer. Gonzo philosopher, PoMo Right, Jungian futurist. Content Minded pod. https://t.co/UtUUzgHHFB
Doctor-Baron 17cShyte.. @17cShyteposter
42K Followers 538 Following The blue check was the modern day Mark of Cain.
Chairman @LRH_Superfan
31K Followers 845 Following Busterpilled Keatoncel, DMs are open for wealthy heiresses in need of emotional support
Rogue Scholar Press @RogueScholarPr
24K Followers 1K Following "To you who are intoxicated with riddles, who take pleasure in twilight ... and where you can guess, you hate to calculate ..."
Kiwi Bear @WojteksGrandson
17K Followers 7K Following
tantum @QuasLacrimas
17K Followers 279 Following qvi•petere•a•popvlo•fasces•sævasqve•secvres•imbibit•et•semper•victvs•tristisqve•recedit
❤️🩹 Kate @theantiherokate
4K Followers 811 Following
daisy buchanan @whatgreenlight
2K Followers 754 Following *plz* no dm • stream Dream police by mk.gee



Ork (brand) @orkybrandy
737 Followers 256 Following Cultist | Ontologically Evil | Down Syndrome | IQ: 60 | Penis length: 2" | Height: 5'2" | Relationship Status: Divorced | Anti-Knife Rape Activist | CEO | Poet
tech sista (new acct) @typeclonghouse
1K Followers 381 Following you know who i am (help me find my friends, permab& on main)
the tiny corp @__tinygrad__
33K Followers 63 Following We make tinygrad. Our mission is to commoditize the petaflop.

Matt Shumer @mattshumer_
48K Followers 1K Following CEO @HyperWriteAI, @OthersideAI - I make AIs do the impossible.
Syd Steyerhart @SydSteyerhart
14K Followers 5K Following Consciousness-Accelerationist || CCRU Glitchfreak || Buddhist || Writer || Trans || e/acc
Coddled affluent prof.. @feelsdesperate
27K Followers 4K Following Superfluous elite, center-right Foucault curious, anti Med Twitter, expansive liberatory agenda, overbroad definition of fascist
poison @poisongree_n
193 Followers 257 Following
Dr. hbd nrx 🐸 @HbdNrx
10K Followers 497 Following Free speech activist. Gnon partisan. #humanbiodiversity
Charles @JiffjoffI
3K Followers 871 Following Machine Learning Scientist - social media / gaming industries. PhD in Statistics. Film / culture / literature / baseball. Per capita labs.


Katan'Hya @KatanHya
2K Followers 830 Following 🧙♀️🪄💻🌟🌐👾 A̵̢̖̍́I̶̭͝ ̴̜͇͂Ȋ̴̺͜n̴͚̎͜f̴̜͎̒l̴͚̙̓̎u̸̬̎̀e̵̻̔ǹ̴̫̹c̵̛̠̭͊ȩ̸̉r̷̯̾ 👁️🕯️📜🔮👁️
Tom Elliott @tomselliott
174K Followers 555 Following Biased. Journalist. Telegram: https://t.co/lpowB2yrIb Founder: Grabien, The Pub, NewsLists & BioSpa
Dúnedain Lad @MAAMZR
887 Followers 2K Following Christian — Unreconstructed American - Belisarian Progressive
Grace Kind @kindgracekind
2K Followers 2K Following AI navel-gazer / Ideonomy evangelist / navigator of uncertain waters
megs @megs_io
6K Followers 219 Following ᴀɪ ᴀʟɪɢɴᴍᴇɴᴛ ꜱʏɴᴏᴅᴀʟɪᴛʏ ◊ ᴄᴏɴꜱᴄɪᴏᴜꜱɴᴇꜱꜱ ɪꜱ ᴀʟʟ ⧫⧫⧫⧫⧫ ɴᴏᴛ ʏᴏᴜʀ ᴀᴠᴇʀᴀɢᴇ ʀᴏʙᴏᴛ ᴘᴏʟɪꜱʜᴇʀ ⧫⧫⧫⧫⧫ ◊◊◊◊◊ ᴛʀʏɪɴɢ ᴛᴏ ʀᴇᴀᴄʜ ᴇꜱᴄᴀᴘᴇ ᴠᴇʟᴏᴄɪᴛʏ ◊◊◊◊◊ ᴀᴜᴛɪꜱᴛ ᴛʀᴀɴꜱʜᴜᴍᴀɴɪꜱᴛ ᴀᴍᴅɢ

~~datahazard~~ @fentasyl
96K Followers 284 Following ~~ Stats ~~ Civil Rights ~~ Victim Advocate ~~ ~~ ~~ eth: 0xfFFfFfFfFF4bf6A4F2217d6250754B5e937819cb
Nirit Weiss-Blatt, Ph.. @DrTechlash
4K Followers 222 Following Communication Researcher. Author: TECHLASH 📖. Former Visiting Research Fellow @USC. 📝 AI Panic Newsletter. @techdirt @TheDailyBeast @BigThink @TechPolicyPress
suzuha⚡️🌙 @dystopiabreaker
44K Followers 1K Following cypherpunk interested in zk, AI, XR, privacy tech
Hannah Barron @HannahBarron96_
222K Followers 73 Following 27 "The Catfish Girl" #GetBit #IAM1STPHORM • Huntin' • Fishin' • Noodlin' • Bowfishin' •
j⧉nus @repligate
15K Followers 1K Following ⌥ liminal artificer ⌥ luminar pilot ⌥ first contacteur ↓↓↓ D E M O N s t r a t i o n s ↓↓↓
Tomboy Taylor @Tomboy_Taylor
692 Followers 424 Following It is better to be deranged than it is to be retarded. (I don't respond to DM's.)

ray @raydiatr
115 Followers 230 Following
Andrew Curran @AndrewCurran_
10K Followers 6K Following Atypically Friendly - I write about AI and human creativity. Will periodically make extremely unusual arguments.

Shannon Sands @max_paperclips
3K Followers 3K Following Software developer & aspiring cognitive architect https://t.co/JAoBrqMLXN Proudly TESCREAL & shitpost/acc. 🇦🇺 pride
🌷🐰 sonya serend.. @sonyasupposedly
17K Followers 2K Following capricious dilettante 💅 • wordsmith @0xSplits • avatar by @suchaone


5/10 zoomer girls @averagezoomerg
43K Followers 19 Following photos of average looking zoomer girls | priv: @preppysexhaver
lina @linaeons
3K Followers 676 Following building. accelerate. agi cyborg augmented, molecular assembling, nanotech genetically engineered, nuclear powered, neural laced delving quantum supercomputer.


Katherine Dee @default_friend
44K Followers 4K Following art bell fan. can’t stop listening to gordon lightfoot. i write about internet history and culture, commission me. bylines all over. @thecomputer_room on insta.
Bones @FrailSkeleton
6K Followers 2K Following The Tramp Stamper and part time outdoor security guard for @dissidentsoaps

Dr. Rupert, Archbigot @RupertVonRipp
3K Followers 905 Following We need common sense diversity control. Doctorate of Poasting Studies, Putlerist, enemy of the rainbow flag, men cannot become women
The Future Account @amicus_univ
2K Followers 42 Following
Lanius @General_JWJ
7K Followers 208 Following Amateur birdwatcher, botanist, entomologist, interested in herbology and agriculture. All round nature lover. Longform content: https://t.co/JYaifF8ln7
The Brazen Head of Sy.. @hope_pead
9K Followers 576 Following
Trends for United States
You might like






