
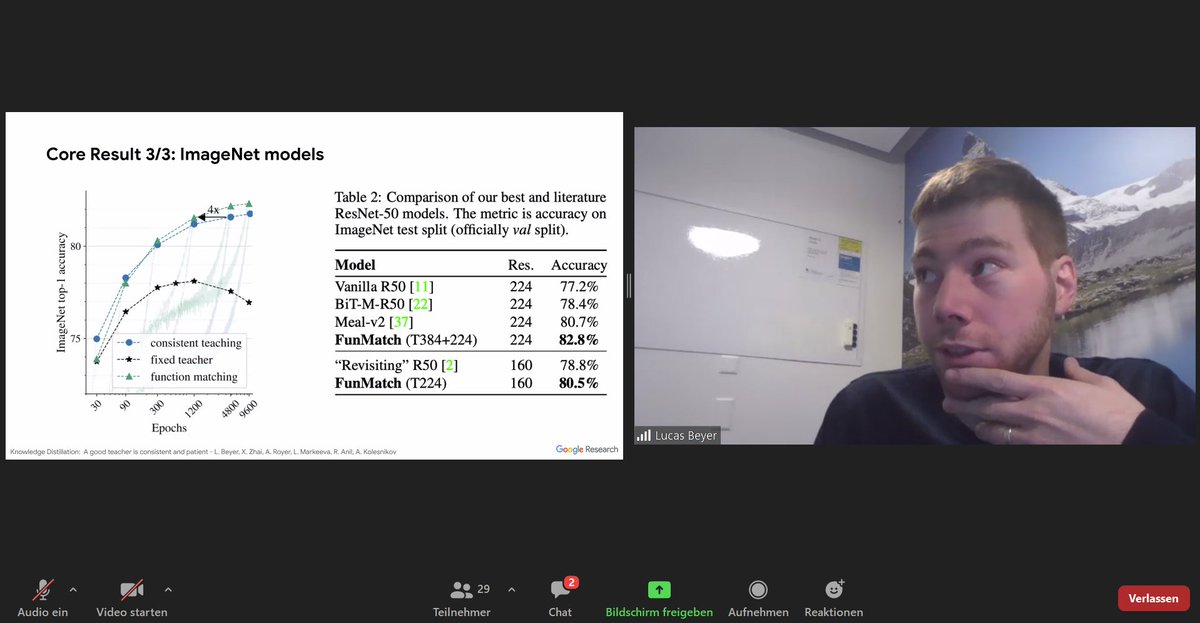
#Distillation: Show student and teacher the same images = recipe for accuracy. Consistent input is the only setting that works. Heavy data augmentations help. Patience: part of the recipe. "No overfitting with 1k images. Actually, we underfit" @giffmana #NittyGritty #AlephAlpha
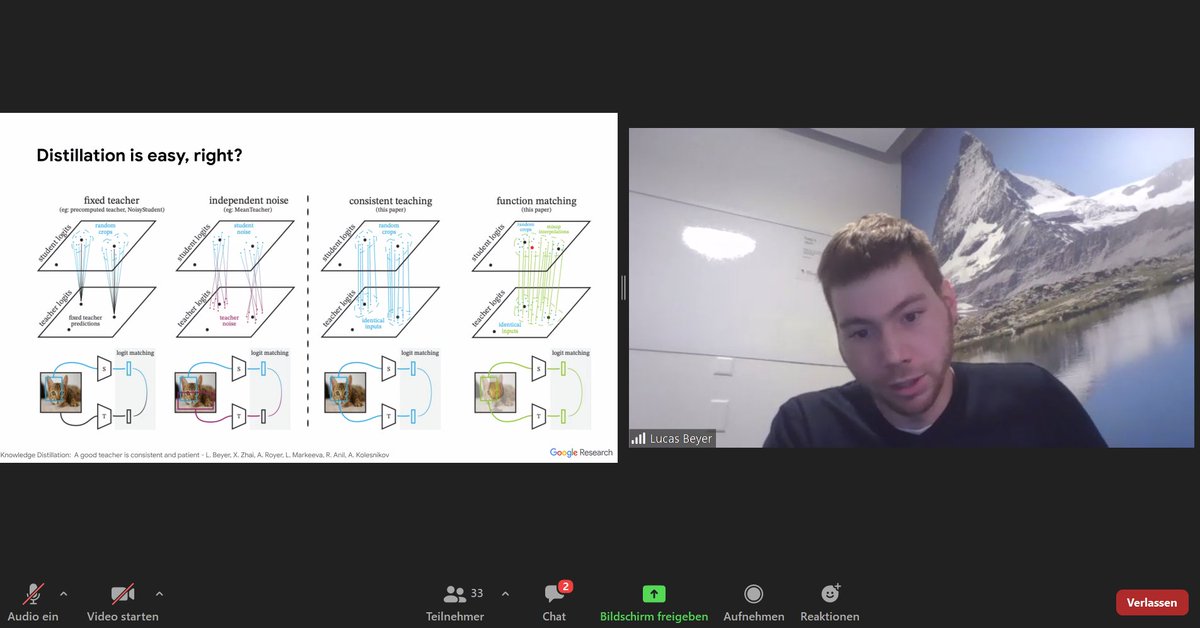
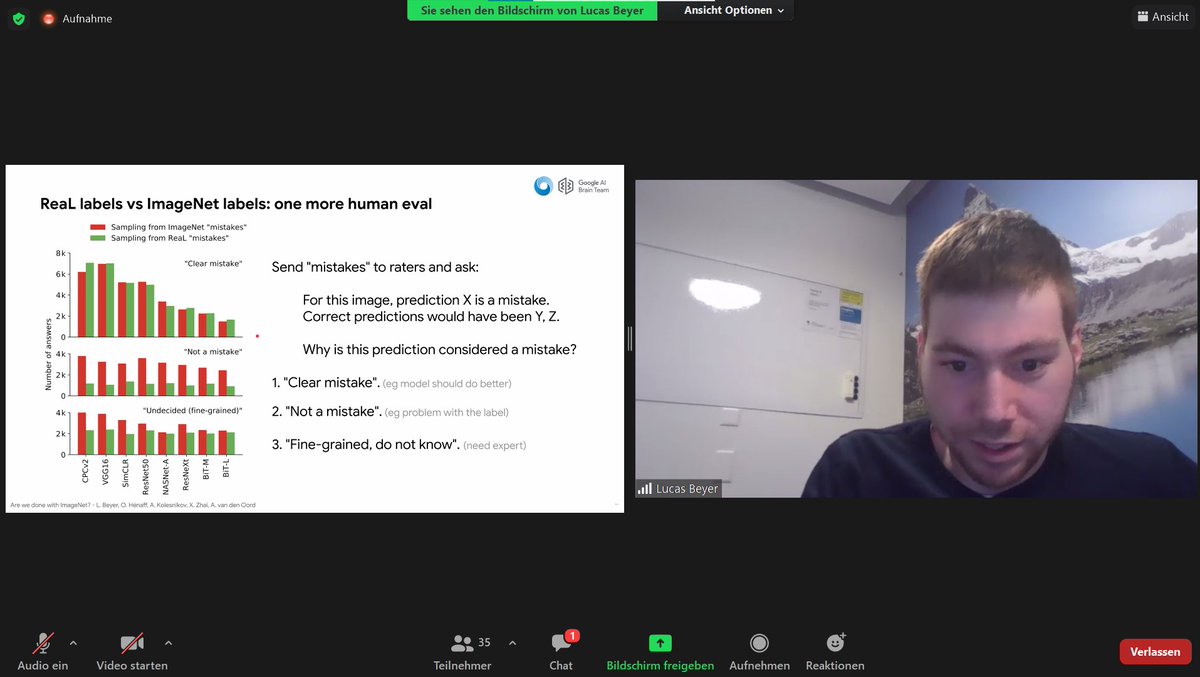
It's not the end of #ImageNet. Labels have shortcomings, but distillation (through consistent, patient teaching) yields improvements. Paper: arxiv.org/abs/2106.05237 Key observations by @giffmana at the #NittyGritty public seminar at #AlephAlpha. Thanks for the insights! 🤓

Setting/intuition: Multilinguality. No direct translations or paired languages needed in LiT-tuning data. The pre-trained image model serves as a bridge across languages, anchoring concepts. Single text model sees all languages 👉Similar to how multilingual kids learn @giffmana

