
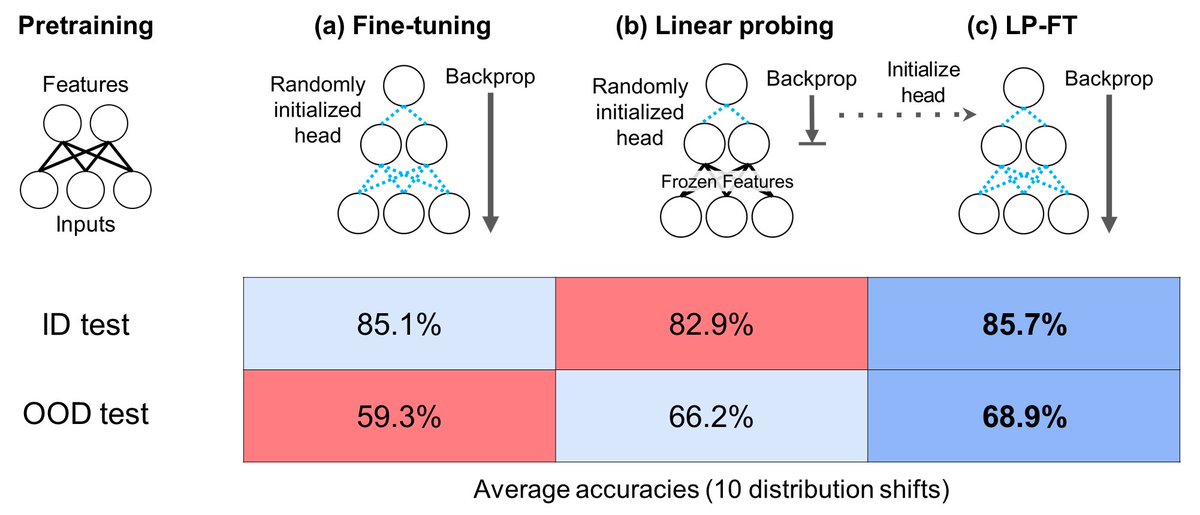
How should you fine-tune a large pretrained model (CLIP, SimCLR) robustly? We find that standard fine-tuning can do poorly out-of-distribution (test data ≠ fine-tuning data). Our analysis leads to a simple fix, higher accuracy on 10 datasets. arxiv.org/abs/2202.10054 (ICLR Oral)
6
122
644
0
247
Download Image
(2/n) Joint work with Aditi Raghunathan, @rmjones96, and my advisors @tengyuma and @percyliang

@ananyaku Do you recommend the same strategy for non-classification networks, e.g. image-to-image or volume-to-volume translation?
