
Excited to present our work with @ashvinair and @svlevine, Offline RL with Implicit Q-Learning (IQL), a simple method that achieves SOTA performance on D4RL arxiv.org/abs/2110.06169 and works 4x faster than prior SOTA github.com/ikostrikov/imp… Thread below
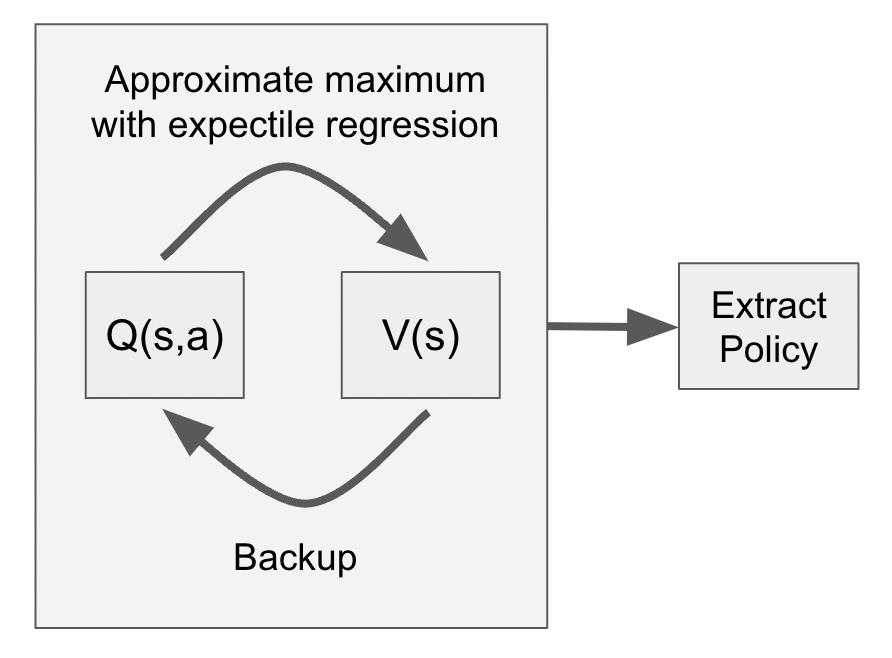
Actor-Critic algorithms can fail for offline RL when the actor outputs out-of-dataset actions for TD backups. What if we just do TD learning with the dataset actions? That is very stable, but it learns the behavior policy value function while we want the optimal value function.

@ikostrikov @ashvinair @svlevine Congrats, looks really simple to implement and effective! Any plans to benchmark it on RLUnplugged? Would love to see a comparison to offline MuZero (arxiv.org/abs/2104.06294)

@ikostrikov @svlevine @ashvinair Looks really smart! I will for sure look at your repository and try to replicate the approach in my field.