Excited to present our work with @ashvinair and @svlevine, Offline RL with Implicit Q-Learning (IQL), a simple method that achieves SOTA performance on D4RL arxiv.org/abs/2110.06169 and works 4x faster than prior SOTA github.com/ikostrikov/imp… Thread below
Actor-Critic algorithms can fail for offline RL when the actor outputs out-of-dataset actions for TD backups. What if we just do TD learning with the dataset actions? That is very stable, but it learns the behavior policy value function while we want the optimal value function.
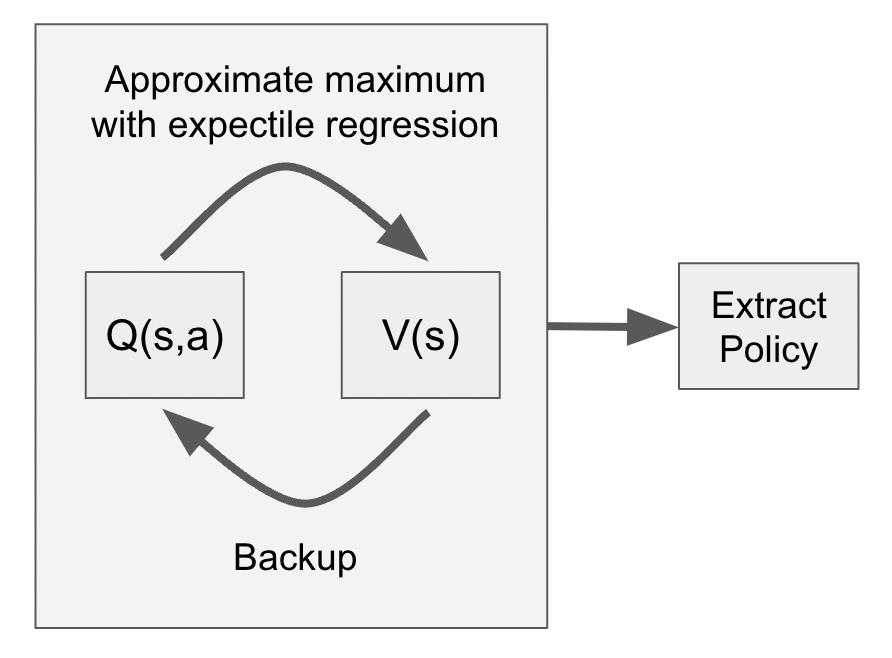
Instead, to approximate a maximum of a Q-function instead of training an actor, IQL performs expectile regression, which does not require sampling out-of-dataset actions:

Expectile regression can be implemented with a simple asymmetric MSE. Then use these estimates of V(s) in TD-backups. Finally, we extract an optimal policy with advantage-weighted behavioral cloning.

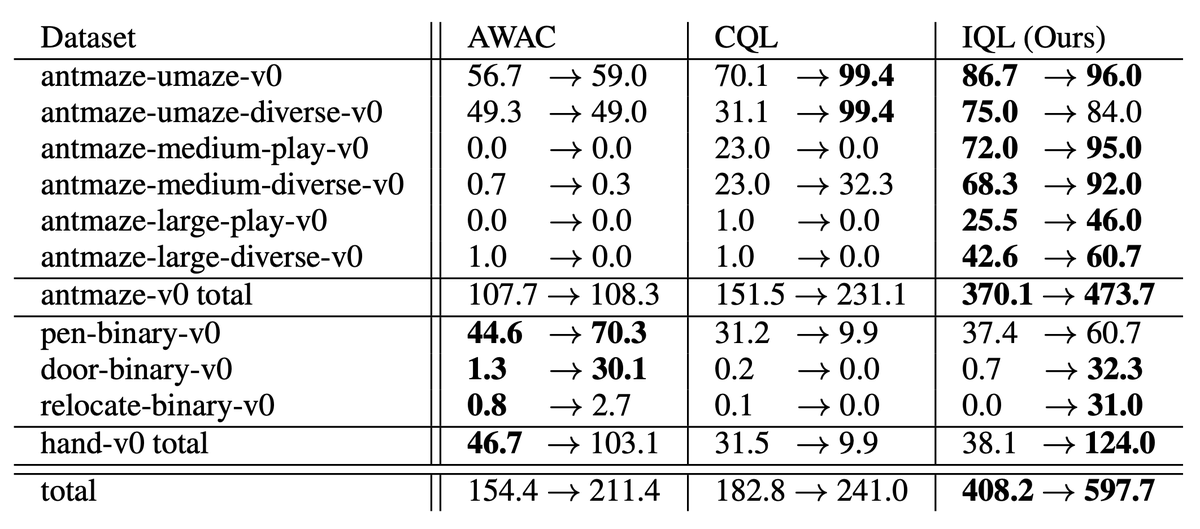
While being extremely simple and fast, IQL outperforms prior work on D4RL:

IQL works especially well on Ant Maze tasks that require ‘stitching’ (dynamical programming)
Finally, IQL performs extremely well for finetuning: initializing from offline data, and continuing to train online. In challenging Ant Maze tasks, it performs best offline, then gets even better online.