
Justin Johnson @jcjohnss
Assistant Professor @UMich CSE; Previously Research Scientist @MetaAI; CS PhD @Stanford. Deep Learning + Computer Vision. Joined January 2014-
Tweets261
-
Followers17K
-
Following552
-
Likes2K

We'll present Text2Room as an oral tomorrow at #ICCV2023 - talk at 9am in "Paris Sud" - poster 10:30am-12:30pm in "room Nord" Come say hi and have a chat if you're interested in our work! :)
We'll present Text2Room as an oral tomorrow at #ICCV2023 - talk at 9am in "Paris Sud" - poster 10:30am-12:30pm in "room Nord" Come say hi and have a chat if you're interested in our work! :)

How could we generate large-scale 3d scenes with text inputs? Our #ICCV2023 oral paper "Text2room" shows we can directly generate meshes of 3D scenes by combining pretrained 2D diffusion model and depth estimators. Check out our paper on tomorrow morning's oral&poster session!
We are releasing code (training + inference) and models for our ICML 2023 paper that uses hyperbolic geometry to improve CLIP-style image/text feature learning

We are releasing code (training + inference) and models for our ICML 2023 paper that uses hyperbolic geometry to improve CLIP-style image/text feature learning
(1/4) Excited to share our #ICCV2023 paper Text2Room! We generate scene-scale textured 3D meshes from a given text prompt leveraging 2D text-to-image models such as StableDiffusion. Project: lukashoel.github.io/text-to-room/ Code: github.com/lukasHoel/text… Video: youtu.be/fjRnFL91EZc
This week at #ICML I will present “Hyperbolic Image-Text Representations” — we bring hyperbolic geometry to CLIP and learn interpretable models that also match/outperform CLIP on standard vision tasks. 📜 arxiv.org/abs/2304.09172 📅 Jul 27, 10:30. Say hi! With @metaai @michigan_AI
Our new paper led by @_nileshk shows how to generate animations of people interacting with objects by guiding a diffusion model with a learned object interaction field. Diffusion models can be used to generate all kinds of data, not just images and videos!

Our new paper led by @_nileshk shows how to generate animations of people interacting with objects by guiding a diffusion model with a learned object interaction field. Diffusion models can be used to generate all kinds of data, not just images and videos! https://t.co/6TRKS8G8Kw


It was amazing presenting Omni3D: A Large Benchmark and Model for Monocular 3D Detection in the Wild @CVPR . Project+Code: garrickbrazil.com/omni3d/ Work with amazing Garrick @jstraub6 @nikhilaravi @jcjohnss @georgiagkioxari A long 🧵 1/n
CVPR ATTENDEES, REAL AND VIRTUAL: Voting for all motions has now begun, and voting closes in just under 25 hours! I will be enthusiastically voting "yes" on all motions, including Motion 3 to repeal the social media ban. Here's how to vote:

⛳️ Come chat with me, @georgiagkioxari @jcjohnss, Garrick, Abhinav & Julian about Omni3D at @CVPR today! 📌 Poster #76 ⏲️ Wednesday 4:30-6:30pm #CVPR2023

⛳️ Come chat with me, @georgiagkioxari @jcjohnss, Garrick, Abhinav & Julian about Omni3D at @CVPR today! 📌 Poster #76 ⏲️ Wednesday 4:30-6:30pm #CVPR2023
JPEG decoding converts DCT coefficients into RGB patches; a ViT converts RGB patches back into vectors. Feeding DCT coefficients directly to a ViT can give significant speedups, and satisfyingly lets the model learn from a more "raw" form of the input data.
JPEG decoding converts DCT coefficients into RGB patches; a ViT converts RGB patches back into vectors. Feeding DCT coefficients directly to a ViT can give significant speedups, and satisfyingly lets the model learn from a more "raw" form of the input data.
Our @CVPR paper introduces HexPlane: a simple, efficient representation for dynamic 3D scenes that enables us to train dynamic NeRFs more than 100x faster than prior work
Our @CVPR paper introduces HexPlane: a simple, efficient representation for dynamic 3D scenes that enables us to train dynamic NeRFs more than 100x faster than prior work
Predicting 3D scene structure from a single image is hard. Much prior work essentially distills from classical multiview reconstruction methods, treating their outputs as ground-truth. In this @CVPR paper we instead train from raw (posed) RGB-D data
Predicting 3D scene structure from a single image is hard. Much prior work essentially distills from classical multiview reconstruction methods, treating their outputs as ground-truth. In this @CVPR paper we instead train from raw (posed) RGB-D data

Check out our new work on 3D object auto-captioning with BLIP2, CLIP, and GPT4. Through human evaluations, we found our framework, Cap3D, is better, cheaper, and faster than crowdsourced annotation. Access descriptive captions, point clouds, and shap-E latent codes for…
Check out our new work on 3D object auto-captioning with BLIP2, CLIP, and GPT4. Through human evaluations, we found our framework, Cap3D, is better, cheaper, and faster than crowdsourced annotation. Access descriptive captions, point clouds, and shap-E latent codes for…

Large (text, image) datasets led to breakthroughs in text-to-image synthesis. 3D is the next frontier, but large (text, 3D) data doesn't exist. We show that BLIP-2 + GPT-4 can caption meshes with quality comparable to people, and release 660k captions for Objaverse meshes.

Large (text, image) datasets led to breakthroughs in text-to-image synthesis. 3D is the next frontier, but large (text, 3D) data doesn't exist. We show that BLIP-2 + GPT-4 can caption meshes with quality comparable to people, and release 660k captions for Objaverse meshes.

I am 💯 with the original goal behind the ban, but here's our reasoning for the repeal: Unfortunately the current effect is that well-known authors receive promotion anyway, while smaller labs receive no promotion at all and cannot even speak up when they have a similar work.

I am 💯 with the original goal behind the ban, but here's our reasoning for the repeal: Unfortunately the current effect is that well-known authors receive promotion anyway, while smaller labs receive no promotion at all and cannot even speak up when they have a similar work. https://t.co/KLY4ytLC3y
The CVPR/ICCV social media ban was well-intentioned but ineffective. Well-known authors still have their unpublished work promoted by influencers, but authors can't discuss their own work for months. This is absurd. We hope to change this. Please vote if you are attending CVPR!
The CVPR/ICCV social media ban was well-intentioned but ineffective. Well-known authors still have their unpublished work promoted by influencers, but authors can't discuss their own work for months. This is absurd. We hope to change this. Please vote if you are attending CVPR!

Check out Neural Shape Compiler: a unified framework facilitating Text<->PointCloud<->Program transformations for 3D shapes. Extendable for more modalities and conversions. Joint work with @honglaklee @jcjohnss. Project:tiangeluo.github.io/projectpages/s… Code & Pre-trained…

Hyperbolic Image-Text Representations abs: arxiv.org/abs/2304.09172

Cool demo combining Segment Anything + MCC for single-image 3D reconstruction! What an exciting time ... combining specialized models can open up new capabilities with minimal effort

Cool demo combining Segment Anything + MCC for single-image 3D reconstruction! What an exciting time ... combining specialized models can open up new capabilities with minimal effort

AK @_akhaliq
309K Followers 3K Following AI research paper tweets, ML @Gradio (acq. by @HuggingFace 🤗) dm for promo follow on Hugging Face: https://t.co/q2Qoey80Gx
Kosta Derpanis @CSProfKGD
48K Followers 198 Following #CS Associate Prof @YorkUniversity, #ComputerVision Scientist Samsung #AI, @VectorInst Faculty Affiliate, TPAMI AE, #CVPR2024/#ECCV2024 Publicity Co-chair
Soumith Chintala @soumithchintala
185K Followers 877 Following Cofounded and lead @PyTorch at Meta. Also dabble in robotics at NYU. AI is delicious when it is accessible and open-source.
Matthias Niessner @MattNiessner
31K Followers 162 Following Professor for Visual Computing & Artificial Intelligence @TU_Muenchen Co-Founder @synthesiaIO
Alfredo Canziani @alfcnz
86K Followers 269 Following Musician, math lover, cook, dancer, 🏳️🌈, and an ass prof of Computer Science at New York University
Jia-Bin Huang @jbhuang0604
51K Followers 285 Following Associate Professor @umdcs; Part-time Research Scientist @Meta. I like pixels.
Eric Jang @ericjang11
69K Followers 3K Following physical AGI at 1X. Author of "AI is Good for You" https://t.co/eFg4WXhg0p
Autonomous Vision Gro.. @AutoVisionGroup
12K Followers 371 Following Awesome Vision Group of Andreas Geiger at the University of Tübingen. We are excited about Computer Vision, Machine Learning and Robotics.
Animesh Garg @animesh_garg
21K Followers 1K Following Foundation Models for Generalizable Autonomy. Assistant Professor in AI Robotics @GeorgiaTech + @NvidiaAI. prev @Stanford @berkeley_ai @UofTCompSci

Angjoo Kanazawa @akanazawa
14K Followers 627 Following Assist. Professor at @Berkeley_EECS, @berkeley_ai. KAIR, @nerfstudioteam, advising @WonderDynamics and @LumaLabsAI. she/her.
Rosanne Liu @savvyRL
33K Followers 966 Following Cofounded & running @ml_collective. Host of Deep Learning Classics & Trends. Research at Google DeepMind. DEI/DIA Chair of ICLR & NeurIPS. Writing https://t.co/IbycyGfnDR
Ross Wightman @wightmanr
18K Followers 1K Following Computer Vision @ 🤗. Ex head of Software, Firmware Engineering at a Canadian 🦄. Currently building ML, AI systems or investing in startups that do it better.
Kyunghyun Cho @kchonyc
61K Followers 2K Following a combination of a mediocre scientist, a mediocre manager, a mediocre advisor & a mediocre PC at @nyuniversity (@CILVRatNYU) & @genentech (@PrescientDesign).
Sander Dieleman @sedielem
50K Followers 2K Following Research Scientist at Google DeepMind. I tweet about deep learning (research + software), music, generative models (personal account).
Michael Bronstein @mmbronstein
43K Followers 4K Following #DeepMind Professor of #AI @UniofOxford / Fellow @ExeterCollegeOx / ML Lead @ProjectCETI / https://t.co/kZpGpDzYeV
Andrea Tagliasacchi �.. @taiyasaki
12K Followers 165 Following Associate Professor @ SFU (Research Chair), Research Scientist @ Google DeepMind, Associate Professor (status only) @ UofT. Opinions are my own.
Tom Goldstein @tomgoldsteincs
23K Followers 2K Following Professor at UMD. AI security & privacy, algorithmic bias, foundations of ML. Follow me for commentary on state-of-the-art AI.
Xiaolong Wang @xiaolonw
11K Followers 947 Following Assistant Professor @UCSDJacobs Postdoc @berkeley_ai PhD @CMU_Robotics
Pranav Rajpurkar @pranavrajpurkar
21K Followers 710 Following Professor at Harvard | Medical Artificial Intelligence | https://t.co/Z6tBGoluEG
Charles Dong @chardon_cs
7 Followers 198 Following MSc @ XJTLU | Programming & Computer Science | Rustacean 🦀 + Pythonista 🐍
anormyf @rigorousdreamer
7 Followers 212 Following

Nahal Shahini @nel7868
3 Followers 42 Following
responsible ai @answerable_ai
9 Followers 135 Following
Christoph Hanazeder @CHanazeder
22 Followers 504 Following CTO at PTS tec Working on Agents to Update existing ERP Systems with LLMs
riskturkai @riskturkai
311 Followers 74 Following Our work aims to bridge the gap between AI technology and financial applications, revolutionizing the way risk is managed in the industry.
Steve @Steve5328110822
0 Followers 6 Following
Amgad Hasan @AmgadGamalHasan
236 Followers 292 Following A machine learning engineer specializing in LLMs and ASR models
A_bigail @Abigail20898125
34 Followers 1K Following
Xin Jin @Xander_K1ng
8 Followers 64 Following Second year graduate student, Chongqing Technology and Business University. || Research interest: Computer Vision, Data Augmentation.
Rafael Lopez @rlgd27
10 Followers 122 Following
Linda Asare @Sandralotts2k7
2K Followers 433 Following
jhc @jhc884070851573
31 Followers 75 Following
Youngtaek Oh @ytaek_oh
0 Followers 54 Following
Smith Winston @SmithWinst13560
8 Followers 102 Following
Edwin @Edwin03947234
0 Followers 207 Following

Eva Louise Marie Gabr.. @e681554349
7 Followers 3K Following
Pingyue Zhang @PingyueZhangNU
0 Followers 19 Following
Douglas McDowell @DouglasRMcD
74 Followers 90 Following Seasoned developer for Martin Retail Group/Publicis Groupe. Splitting time between my "day job", my post-grad course in AI Leadership, and independent GPT work
Yaofeng Xie @xi_9856_xi
0 Followers 38 Following
Akshay Paruchuri @Yahskapar
231 Followers 820 Following CS PhD Student @unccs. Student Researcher @GoogleHealth. Interested in all things computer vision, graphics, machine learning, and healthcare! Optimist.
Gunbir Singh Baveja @g_baveja
16 Followers 85 Following visiting researcher @kaist_ai advised by @JosephLim_AI; sophomore @UBC
Tristan @trirpi
6 Followers 24 Following
Ryan Reece @RyanDavidReece
2K Followers 4K Following Physicist, machine learning @tenstorrent, poker player, aspiring philosopher of science. Formerly @CerebrasSystems, @ATLASexperiment. (views are my own)
Y31q @ml_yglk
0 Followers 19 Following






獨行道 @arakalx
0 Followers 258 Following
Suman Chowdhury @_sumanchowdhury
31 Followers 197 Following PhD candidate in #ComputerVision for #AutonomousVehicles at @AcSIR_India, @CSIR_CMERI
cetinsamet @cetinsametttttt
175 Followers 2K Following
NeuralNetNinja @DeepLearnQuest
8 Followers 151 Following curious. documenting my deep learning journey.
vondrak @vondrakking
312 Followers 153 Following
Amin Haeri @ahhhh_min
0 Followers 93 Following
rid rid @ridrid1376346
3 Followers 20 Following
Max Bardelang @maxbardelang
5 Followers 24 Following
Sanyamee Patel @sanyamee369
3 Followers 49 Following
Lê Hoàng Nam @Le_Hoang_Nam_24
11 Followers 42 Following

Malaz Tamim @TamimMalaz
38 Followers 398 Following Data Engineering and Analytics Master Student @Tu_Muenchen | Computer Science Alumnus @aub_lebanon
Sebas De La Roche @AspaRoche
57 Followers 312 Following 👨💻 Senior Full Stack Engineer ➡️ Machine Learning student | Merging coding & AI for smarter solutions | #WebDev #MachineLearning #Tech
Salik Mubeen @salik_mubeen
172 Followers 367 Following Software Developer | In love with React.js | Typescript, Node.js, GraphQL, React Native, Databases, Golang, Python | current @iitdelhi ML/AI/structural engg
Sang Dao @SangDao811932
175 Followers 1K Following
Ankur Bohra @AnkurBohra9
18 Followers 2K Following
AK @_akhaliq
309K Followers 3K Following AI research paper tweets, ML @Gradio (acq. by @HuggingFace 🤗) dm for promo follow on Hugging Face: https://t.co/q2Qoey80Gx
Kosta Derpanis @CSProfKGD
48K Followers 198 Following #CS Associate Prof @YorkUniversity, #ComputerVision Scientist Samsung #AI, @VectorInst Faculty Affiliate, TPAMI AE, #CVPR2024/#ECCV2024 Publicity Co-chair
Michael Black @Michael_J_Black
58K Followers 638 Following Director, Max Planck Institute for Intelligent Systems (@MPI_IS). Chief Scientist @meshcapade. Building 3D digital humans using vision, graphics, and learning.
Soumith Chintala @soumithchintala
185K Followers 877 Following Cofounded and lead @PyTorch at Meta. Also dabble in robotics at NYU. AI is delicious when it is accessible and open-source.
Matthias Niessner @MattNiessner
31K Followers 162 Following Professor for Visual Computing & Artificial Intelligence @TU_Muenchen Co-Founder @synthesiaIO
PyTorch @PyTorch
379K Followers 77 Following Tensors and neural networks in Python with strong hardware acceleration. PyTorch is an open source project at the Linux Foundation. #PyTorchFoundation
Alfredo Canziani @alfcnz
86K Followers 269 Following Musician, math lover, cook, dancer, 🏳️🌈, and an ass prof of Computer Science at New York University
Jia-Bin Huang @jbhuang0604
51K Followers 285 Following Associate Professor @umdcs; Part-time Research Scientist @Meta. I like pixels.
Lucas Beyer (bl16) @giffmana
56K Followers 445 Following Researcher (Google DeepMind/Brain in Zürich, ex-RWTH Aachen), Gamer, Hacker, Belgian. Mostly gave up trying mastodon as [email protected]
Eric Jang @ericjang11
69K Followers 3K Following physical AGI at 1X. Author of "AI is Good for You" https://t.co/eFg4WXhg0p
Richard Socher @RichardSocher
101K Followers 971 Following CEO @youSearchEngine Investing at @aixventuresHQ Before: Stanford Adj Prof in AI/NLP, Chief Scientist at Salesforce, MetaMind
Animesh Garg @animesh_garg
21K Followers 1K Following Foundation Models for Generalizable Autonomy. Assistant Professor in AI Robotics @GeorgiaTech + @NvidiaAI. prev @Stanford @berkeley_ai @UofTCompSci

Kevin Patrick Murphy @sirbayes
42K Followers 334 Following Research Scientist at Google Brain / Deepmind. Interested in Bayesian Machine Learning.
Sergey Levine @svlevine
79K Followers 122 Following Associate Professor at UC Berkeley Co-founder, Physical Intelligence
Angjoo Kanazawa @akanazawa
14K Followers 627 Following Assist. Professor at @Berkeley_EECS, @berkeley_ai. KAIR, @nerfstudioteam, advising @WonderDynamics and @LumaLabsAI. she/her.
Rosanne Liu @savvyRL
33K Followers 966 Following Cofounded & running @ml_collective. Host of Deep Learning Classics & Trends. Research at Google DeepMind. DEI/DIA Chair of ICLR & NeurIPS. Writing https://t.co/IbycyGfnDR
Percy Liang @percyliang
49K Followers 408 Following Associate Professor in computer science @Stanford @StanfordHAI @StanfordCRFM @StanfordAILab @stanfordnlp | cofounder @togethercompute | Pianist
Kyunghyun Cho @kchonyc
61K Followers 2K Following a combination of a mediocre scientist, a mediocre manager, a mediocre advisor & a mediocre PC at @nyuniversity (@CILVRatNYU) & @genentech (@PrescientDesign).
Dima Damen @dimadamen
8K Followers 643 Following Professor of Computer Vision, University of Bristol - passionate about the temporal stream in our lives.
Dreaming Tulpa 🥓�.. @dreamingtulpa
34K Followers 1K Following Coder and AI whisperer | 🇨🇭 | @aiia_dao Keeping up to date with Generative AI on https://t.co/JjX7INV1K5 Building https://t.co/0tHHSgyHnn More here 👉 https://t.co/8ES5KiPMND
@levelsio @levelsio
416K Followers 1K Following 🦄https://t.co/sQ0aiU7v02 $202K/m 💆https://t.co/AoNP9BW2Dp $2K/m ✨https://t.co/BmbkrX4Zyf $0.5K/m 📸https://t.co/lAyoqmSBRX $57K/m 🖼https://t.co/1oqUgfD6CZ $44K/m 🌍https://t.co/BjTozWAXwG $27K/m 🛰https://t.co/ZHSvI2wjyW $51K/m
Mr. For Example @MrForExample
1K Followers 384 Following Just a young man on a meaningful Adventure🚀 Machine Learning Research Engineer 🤖 Practice & Love Combat Sports 🥋
DatologyAI @datologyai
963 Followers 17 Following DatologyAI builds tools to automatically select and optimize the best data on which to train AI models, leading to better models which train faster.
Martin Nebelong @MartinNebelong
27K Followers 1K Following 🎨 Artist on the forefront of tech, VR and AI. Client list include Runway, Lumalabs, Media Molecule, The UN, LEGO, Adobe. Once performed VR for 40k audience.
felixkit @felixkit
273 Followers 122 Following
Rajko Radovanović @rajko_rad
4K Followers 4K Following AI/infra @a16z (partner to amazing teams eg @MistralAI @udiomusic); Enjoy most things outdoors, care about democracy in 🇷🇸🇭🇷🇸🇮🇧🇦🇲🇪
Kyle Sargent @KyleSargentAI
267 Followers 345 Following 3D, view synthesis, reconstruction, generative models CS PhD student @Stanford. Past: AI Resident @Google, A.B. @Harvard Like/retweet/follow != endorsement.
Keunhong Park @KeunhongP
1K Followers 277 Following Former Research Scientist at Google. Find me on Mastodon at @[email protected].
martin_casado @martin_casado
50K Followers 2K Following GP @ a16z ... questionable heuristics in a grossly underdetermined world
worldlabs @theworldlabs
189 Followers 3 Following
Tripo @tripoai
4K Followers 2 Following The only one you need to follow for 3D and AI. Tripo webapp: https://t.co/lQfcaFgwYo Tripo OpenAPI Platform: https://t.co/5sCzUy6sKX Powered by @VASTAIResearch
near @nearcyan
45K Followers 883 Following https://t.co/IdaJwZJCXm partner @ https://t.co/9g1MIgjiqc dms open
Charlie Shenton @charshenton
971 Followers 247 Following GFX programmer interested in VR and GPU driven rendering




Sagar Vaze @Sagar_Vaze
838 Followers 146 Following Machine Learning and Computer Vision PhD Student at @UniofOxford and @Oxford_VGG
Jupyter Meowbooks @untitled01ipynb
15K Followers 306 Following Managing Director, Memetics and Advanced Shitposting Institute (hyperstitonal) || may post manipulated imagery and bad memes. AKA Kandrej Arpathy
Avataar @Avataar
455 Followers 153 Following Avataar is reimagining the industry with the power of spatial storytelling, moving into a new era of visual discovery by enabling generative AI-powered visuals.
Common Sense Machines @CSM_ai
7K Followers 0 Following Making 3D World Generation Simpler and Joyful. Web: https://t.co/esQEjtX3eo. Discord: https://t.co/0QUMNkxQyF. Email: [email protected]

Walter Scheirer @wjscheirer
2K Followers 643 Following Prof. @NotreDame. IEEE @ComputerSociety PAMI TC Chair. Computer Vision Foundation CTO. Artificial Intelligence + Digital Humanities + History of Technology.
Kiana Ehsani @ehsanik
3K Followers 456 Following Senior Research Scientist @allen_ai, ex-Ph.D. @uwcse, Interested in computer vision, robotics and deep learning, Climber on the weekends "Opinions are my own"
Maximilian Nickel @mnick
1K Followers 543 Following Random Hypothesis Generator at Facebook AI Research. All views my own.
Alex Nichol @unixpickle
8K Followers 389 Following Code, AI, and 3D printing. Opinions are my own, not my computer's...for now. Husband of @thesamnichol. Co-creator of DALL-E 2. Researcher @openai.

Robin Rombach @robrombach
6K Followers 397 Following Generative enthusiast and long-term PhD Student @LMU_Muenchen. Author of VQGAN, Latent Diffusion, Stable Diffusion.
Nicolas Carion @alcinos26
2K Followers 222 Following Research Scientist at Meta. Previously, post-Doc @nyuniversity, PhD student @FacebookAI Paris. RL, Transformers, Computer Vision.
patricio gonzalez viv.. @patriciogv
17K Followers 2K Following Bridging CG & ML. Artist & Author of @bookofshaders, @pixelspiritdeck, #glslViewer, @lygia_xyz and many creative tools.
Record3D App @record3d
1K Followers 7 Following Record your very own 3D Videos with the iOS App Record3D! Replay them in AR, experience the True3D effect and stream RGBD video via USB! https://t.co/mNvrDpEFpW
Tanmay Gupta @tanmay2099
1K Followers 508 Following Research Scientist at PRIOR @allen_ai (AI2) | Previously PhD @illinoisCS (UIUC) & BTech @IITKanpur


Sepp Hochreiter @HochreiterSepp
10K Followers 395 Following Pioneer of Deep Learning and known for vanishing gradient and the LSTM. I mostly tweet about random ArXiv papers which sparked my interest.
typedfemale @typedfemale
23K Followers 480 Following a really exciting new account "have you ever though you might be like scott alexander? very smart, but can't do math" - anon
Chitwan Saharia @Chitwan_Saharia
3K Followers 289 Following @ideogram_ai Past: Sr. Research Scientist @GoogleAI || B. Tech, CSE, @IITBombay
Luma AI @LumaLabsAI
79K Followers 49 Following Luma's mission is to build multimodal AI to expand human imagination and capabilities. Join us → https://t.co/amvw1U21Nc

Zachary DeVito @Zachary_DeVito
889 Followers 6 Following PyTorch Core Developer and researcher at FAIR. I work on Tensor programming models.
Jitendra MALIK @JitendraMalikCV
4K Followers 0 Following

Daniel Watson @watson_nn
1K Followers 596 Following Research Scientist @GoogleDeepMind. Opinions my own. 🇵🇦
ScottieFox @ScottieFoxTTV
11K Followers 309 Following Visual Magic Craftsman: Voiding Warranties on Tech (for science) #anything2anything ML Research Engineer at @BlockadeLabs
Jonathan Ho @hojonathanho
4K Followers 151 Following
Neural Fields @neural_fields
5K Followers 8 Following Neural fields in visual computing and beyond. Join community slack: https://t.co/dSwTv8fRH0

Rowan Zellers @rown
6K Followers 875 Following Researcher at @OpenAI studying multimodality - vision&language&sound. he/him. website: https://t.co/5Er4j3qN91 , mastodon: @[email protected]
PhysDreamer Physics-Based Interaction with 3D Objects via Video Generation Realistic object interactions are crucial for creating immersive virtual experiences, yet synthesizing realistic 3D object dynamics in response to novel interactions remains a significant

This AI Research Introduces PERF: The Panoramic NeRF Transforming Single Images into Explorable 3D Scenes Quick read: marktechpost.com/2023/11/08/thi… Paper: arxiv.org/abs/2310.16831… Github: github.com/perf-project/P… Project: perf-project.github.io #ArtificialInteligence #DataScience…


Core pytorch NNs (forward and backward) written in clean, readable Triton (from @bobmcdear) github.com/BobMcDear/atto…

This incredibly well-written paper illustrates how deep domain thinking can lead to simplicity and why representation still matters with today’s AI. Also, this is how one should approach writing surveys. Not “Foo did X and Bar did Y. End of story.” arxiv.org/abs/2404.11735


RefFusion from NVIDIA uses reference images to effectively inpaint, insert objects, and outpaint with Gaussian Splatting. 🔗radiancefields.com/reffusion-inpa…
Say hello to our new web-based AI World builder! 🗺️🤖🪄 Turning an idea into a controllable 3D world requires enormous effort. Cube now allows creators to generate 3D controllable videos (from images + text) for rapid ideation/UGC. Access (Maker/Pro): 3d.csm.ai/register

What do you see in these images? These are called hybrid images, originally proposed by Aude Oliva et al. They change appearance depending on size or viewing distance, and are just one kind of perceptual illusion that our method, Factorized Diffusion, can make.

New #NVIDIA paper: Real-time text-to-3D generation #ICCV2023 3D generation from text requires expensive per-prompt optimization. We train 1 model on many prompts for real-time generalization to unseen prompts, interpolations and more! ATT3D details: research.nvidia.com/labs/toronto-a…

Our computer vision textbook is released! Foundations of Computer Vision with Antonio Torralba and Bill Freeman mitpress.mit.edu/9780262048972/… It’s been in the works for >10 years. Covers everything from linear filters and camera optics to diffusion models and radiance fields. 1/4

We've raised a $1.25B infrastructure fund! We love all infra, compute, network, storage, databases, data science, gen AI, dev tools ... from silicon to UIs. Infra is the true root of value in tech. And we're deepening our commitment to it. a16z.com/new-funds-new-…

DreamScape: 3D Scene Creation via Gaussian Splatting joint Correlation Modeling arxiv.org/abs/2404.09227

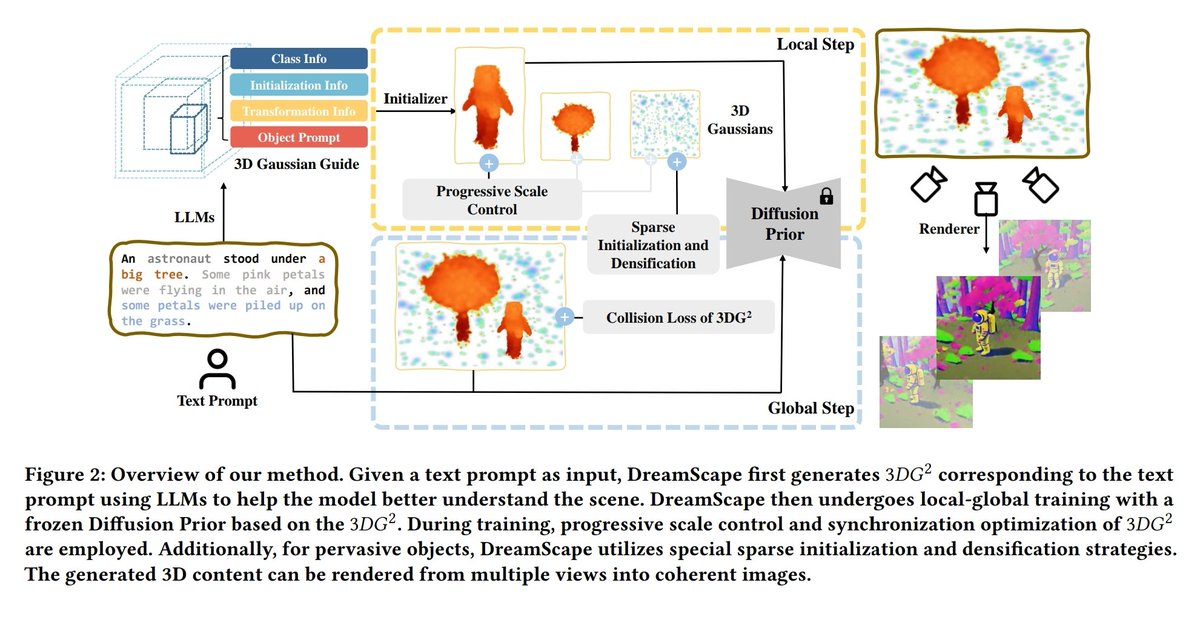



Meta presents Taming Latent Diffusion Model for Neural Radiance Field Inpainting Yields state-of-the-art NeRF inpainting results on various real-world scenes proj: hubert0527.github.io/MALD-NeRF/ abs: arxiv.org/abs/2404.09995
Video2Game: Real-time, Interactive, Realistic and Browser-Compatible Environment from a Single Video proj: video2game.github.io abs: arxiv.org/abs/2404.09833
📢📢📢 3D Gaussian Splatting brought you real-time rendering, but at slightly lower PSNR compared to mipNeRF360... 𝐚𝐬 𝐨𝐟 𝐭𝐨𝐝𝐚𝐲, 𝐭𝐡𝐚𝐭 𝐢𝐬 𝐧𝐨 𝐥𝐨𝐧𝐠𝐞𝐫 𝐭𝐫𝐮𝐞. Introducing "3D Gaussian Splatting as Markov Chain Monte Carlo" arxiv.org/abs/2404.09591

Google announces Probing the 3D Awareness of Visual Foundation Models Recent advances in large-scale pretraining have yielded visual foundation models with strong capabilities. Not only can recent models generalize to arbitrary images for their training task, their

This is an interesting, timely, and important paper. The takeaway is that "recent self-supervised models such as DINOv2 learn representations that encode depth and surface normals, with StableDiffusion being a close second". This contrasts with vision-language models like CLIP,…
Google announces Probing the 3D Awareness of Visual Foundation Models Recent advances in large-scale pretraining have yielded visual foundation models with strong capabilities. Not only can recent models generalize to arbitrary images for their training task, their

What I've learned about Apple's mysterious fisheye projection format, the format they use for their impressive Immersive videos on the Vision Pro: blog.mikeswanson.com/post/747761863…


Check out RealmDreamer (realmdreamer.github.io)--our new 3D scene generation method! No multiview data required :) One of my favorites is this: "Fantasy lighthouse in the Arctic, surrounded by a world of ice and snow, shining with a mystical light under the aurora borealis."
RealmDreamer Text-Driven 3D Scene Generation with Inpainting and Depth Diffusion We introduce RealmDreamer, a technique for generation of general forward-facing 3D scenes from text descriptions. Our technique optimizes a 3D Gaussian Splatting representation to match
Google presents Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention 1B model that was fine-tuned on up to 5K sequence length passkey instances solves the 1M length problem arxiv.org/abs/2404.07143

Meta announces 2nd-gen inference chip MTIAv2. * 708TF/s Int8 / 353TF/s BF16 * 256MB SRAM, 128GB memory * 90W TDP. 24 chips per node, 3 nodes per rack. * standard PyTorch stack (Dynamo, Inductor, Triton) for flexibility Fabbed on TSMC's 5nm process, its fully programmable via the…
Trends for United States
You might like












