
Ross Wightman @wightmanr
Computer Vision @ 🤗. Ex head of Software, Firmware Engineering at a Canadian 🦄. Currently building ML, AI systems or investing in startups that do it better. rwightman.com Vancouver, BC Joined April 2012-
Tweets4K
-
Followers18K
-
Following1K
-
Likes3K
44TB! That'd be a respectible size for an image dataset, but just text, that's a LOT of text!
44TB! That'd be a respectible size for an image dataset, but just text, that's a LOT of text!

With no changes from Llama2 to Llama3 architecture, the importance of data has never been so clear 🦙 While Idefics2 was heavily advertised, our efforts on data didn't shine ☀️ as much, so here are the 3 most important data updates we did: 1. 🍵 The Cauldron, a compilation of 50…

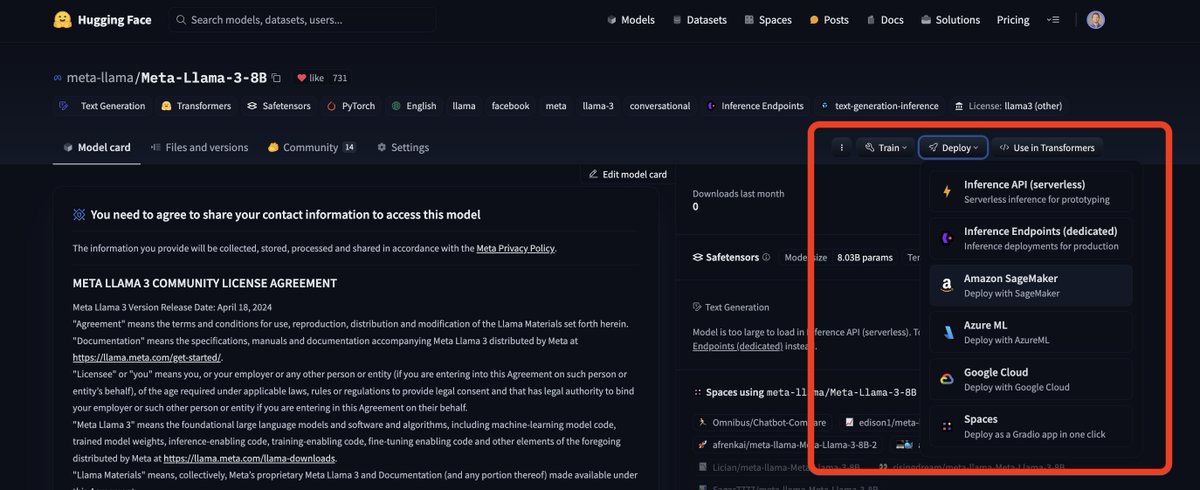
Not everyone is aware but the fact that llama3 has been added to HF on day one means that right away, you can easily run it on @AWS Sagemaker, @Microsoft AzureML, @googlecloud Vertex and the @huggingface hosted solutions (autotrain, spaces, serverless and dedicated endpoints).…
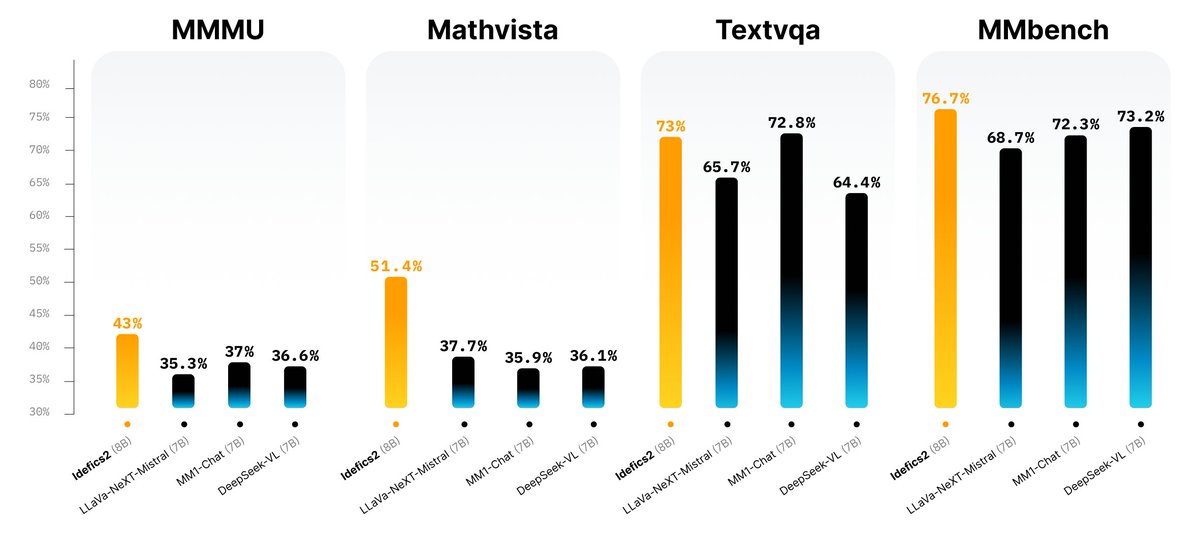
Today we release Idefics2 our newest 8B Vison-Language Model! 💪 With only 8B parameters Idefics is one of the strongest open models out there 📋 We used multiple OCR datasets, including PDFA and IDL from @wightmanr and @m_olbap, and increased resolution up to 980x980 to improve…

Introducing Idefics2, the strongest Vision-Language-Model (VLM) < 10B! 🚀 Idefics2 comes with significantly enhanced capabilities in OCR, document understanding, and visual reasoning. 💬📄🖼️ TL;DR; 📚 8B base and instruction variant 🖼️ Image + text inputs ⇒ Text output 📷…

I wrote a blog post on going from not knowing anything about deep learning last year to training state of the art OSS models - vikas.sh/post/how-i-got… . Hope it helps you. tldr; read the deep learning book, implemented papers + taught, built open source tools
Did you know that you can now view PDFs hosted on the @huggingface hub, directly on the hub? Read here @StasBekman's Machine Learning Engineering Open Book


“[Open-source AI] is really fundamental because it allows everyone to seize the technology, to diminish the fear of limited understanding or of not being qualified to use AI” - @RemiCadene 🔥🔥 Great piece in @opinion by @parmy on the open-source landscape bloomberg.com/opinion/articl…

AK @_akhaliq
309K Followers 3K Following AI research paper tweets, ML @Gradio (acq. by @HuggingFace 🤗) dm for promo follow on Hugging Face: https://t.co/q2Qoey80Gx
Sebastian Raschka @rasbt
266K Followers 906 Following Machine learning & AI researcher writing at https://t.co/A0tXWzG1p5. LLM research engineer @LightningAI. Previously stats professor at UW-Madison.
Mark Tenenholtz @marktenenholtz
114K Followers 544 Following Head of AI @PredeloHQ. XGBoost peddler, transformer purveyor.
elvis @omarsar0
189K Followers 483 Following Building with LLMs @dair_ai • Prev: Meta AI, Galactica LLM, PapersWithCode, Elastic, PhD • Creator of the Prompting Guide (~4M learners)
Lucas Beyer (bl16) @giffmana
56K Followers 444 Following Researcher (Google DeepMind/Brain in Zürich, ex-RWTH Aachen), Gamer, Hacker, Belgian. Mostly gave up trying mastodon as [email protected]
Soumith Chintala @soumithchintala
186K Followers 877 Following Cofounded and lead @PyTorch at Meta. Also dabble in robotics at NYU. AI is delicious when it is accessible and open-source.
Jeremy Howard @jeremyphoward
222K Followers 5K Following 🇦🇺 Co-founder: @AnswerDotAI & @FastDotAI ; Hon Professor: @UQSchoolITEE ; Digital Fellow: @Stanford
Dmytro Mishkin 🇺�.. @ducha_aiki
18K Followers 591 Following Marrying classical CV and Deep Learning. I do things, which work, rather than being novel, but not working.
abhishek @abhi1thakur
81K Followers 662 Following 🤗 I build AutoTrain @huggingface 👨🏽💻 World's First 4x Grand Master @kaggle 🎥 YouTube 100k+: https://t.co/BHnem8fTu5 ⭐ GitHub Star
merve @mervenoyann
55K Followers 4K Following open-sourceress at @huggingface 🧙🏻♀️ proud mediterrenean 🍋 I do TL;DR on ML papers sometimes. RTs != endorsements
Hugging Face @huggingface
343K Followers 189 Following The AI community building the future. https://t.co/VkRPD0VKaZ #BlackLivesMatter #stopasianhate
Horace He @cHHillee
23K Followers 448 Following Working at the intersection of ML and Systems @ PyTorch "My learning style is Horace twitter threads" - @typedfemale
Sanyam Bhutani @bhutanisanyam1
35K Followers 994 Following 👨💻 Sr Data Scientist @h2oai | Previously: @weights_biases 🎙 Podcast Host @ctdsshow 👨🎓 International Fellow @fastdotai 🎲 Grandmaster @Kaggle
Radek Osmulski 🇺�.. @radekosmulski
25K Followers 552 Following Resources to take your Machine Learning skills to the next level 🧪 Senior Data Scientist, RecSys @NVIDIAAI 🏫 @fastdotai trained DL Eng 📝 https://t.co/By87iXx5Pu
Julien Chaumond @julien_c
46K Followers 1K Following Co-founder and CTO at @huggingface 🤗. ML/AI for everyone, building products to propel communities fwd. @Stanford + @Polytechnique
clem 🤗 @ClementDelangue
90K Followers 5K Following Co-founder & CEO @HuggingFace 🤗, the open and collaborative platform to build machine learning
Tanishq Mathew Abraha.. @iScienceLuvr
54K Followers 1K Following PhD at 19 | Founder and CEO at @MedARC_AI | Research Director at @StabilityAI | @kaggle Notebooks GM | Biomed. engineer @ 14 | TEDx talk➡https://t.co/xPxwKTq6Qb
Eric Jang @ericjang11
69K Followers 3K Following physical AGI at 1X. Author of "AI is Good for You" https://t.co/eFg4WXhg0p
François Fleuret @francoisfleuret
31K Followers 455 Following Prof. @Unige_en, Adjunct Prof. @EPFL_en, Research Fellow @idiap_ch, co-founder @nc_shape. AI and machine learning since 1994. I like reality.
Delip Rao e/σ @deliprao
46K Followers 5K Following Busy inventing the shipwreck. @Penn. Past: @johnshopkins, @UCSC, @Amazon, @Twitter ||Art: #NLProc, Vision, Speech, #DeepLearning || Life: 道元, improv, running 🌈
Master @MasterXing88
84 Followers 858 Following
Frank al Ghul @alf_ghul
794 Followers 4K Following A las dictaduras les pasa lo que a las bicicletas. Si paran, se caen. Voyerista de atracos callejeros. Arquitecto de la agricultura del ser

Aditya Rachman Putra @banditelolRP
180 Followers 1K Following Exploring the world through multiple lenses.

Aniket Mishrikotkar @aniketmishri
2 Followers 131 Following MLOps Engineer @themathcompany 🤖⛅🚀 I love building AI systems
Alo @Hal90910
0 Followers 2K Following

Laura Liu @lauraqq
16 Followers 384 Following
Hushh.ai @hushh_ai
81 Followers 298 Following We help users make their data generally accessible and valuable
Jean Olivier @JeanOli92624651
4 Followers 92 Following I am a student in the second year of preparatory class who studies at EIGSI in Casablanca.
Grzegorz Wenc @GrzegorzWenc
8 Followers 367 Following
Deepanker Seth @DeepankerSeth
27 Followers 442 Following
Ojas Patil @OjasPat90312249
0 Followers 125 Following
Z @Zzz010Zzz1
181 Followers 2K Following
Dr Shijie Wang, 王�.. @liimomh
441 Followers 5K Following Dr Shijie Wang, I help @lude_media spread misinformation , 花名 “墨博士”。 https://t.co/jlS8p5RuDK promoter of HCQ to cure COVID.
Digital Applied @DigitalApplied
260 Followers 423 Following Digital Marketing Agency | SEO | PPC | Social Media | Web Development | Automation | CRM | Analytics | AI Digital Solutions.
Sathish Kasilingam @sathishisak
156 Followers 2K Following Interests lie in manufacturing, software, quality, CNC Machine analytics, Data analytics, product management and startups

Dark Knight @Aooos_18
139 Followers 668 Following
Anmol Tomer @anmol_tomer_cc
258 Followers 3K Following Engineering at CRED || Should've been a statistic, learning to be an outlier now || Building things one commit at a time. Sharing Memes, one tweet at a time. 🙌
Venkat Krish @govenkat
270 Followers 2K Following

Ashley Beattie @AshBT
1K Followers 2K Following #Agile and #DevOps Transformation Lead for @agile_bydesign | Tweeting about #AI #GANs #kanban #SystemsThinking #mentalModels #python #futurism
slac @slachterman
156 Followers 1K Following Field CTO at @datavolo building multimodal pipelines for AI
Mathias Jonsson @mathiasjonss
224 Followers 943 Following Chief Customer Officer https://t.co/EoRH8lTsg3 Steering the future of workplace safety with data-driven competency assessments & knowledge recognition.

Noah Vandal @noah_vandal
186 Followers 428 Following ML/CV Engineer Passion for biomedical arenas Born again Christian! Love a good debate, but only if there is purpose
Lucas Simões @_lsimoes
207 Followers 373 Following ML @pimloc || PhD CompNeuro/ML @GatsbyUCL || MSc Physics @usponline 🇬🇧 🇧🇷 🇻🇦
AndreCucchi @cucchi01
9 Followers 106 Following You only live once but if you do it right once is enough💥
fifteen42 @fifteen42_
856 Followers 2K Following
Jonathan Wang @givemettt5600
16 Followers 179 Following
ANGELINA JOHNSON (ang.. @AngelinaJ113
644 Followers 428 Following 🍇💕Be kind for everyone you meet is fighting a battle.I'm not telling you it's going to be easy, I'm telling you it's going to be worth it.”🎏👱♀️😍🎏💐
Filip D @FilipD824
42 Followers 197 Following
Alwin K Lonappan @AlwinKLonappan
6 Followers 103 Following
Thomas Tränkler @ttraenkler
461 Followers 3K Following Founder & CEO of @loopdive. Senior Software Engineer, Web, Cloud, ML & Cognitive Neuroscience
Godson Akampurira ⭐ @GodsonCEO_UG
316 Followers 1K Following Software Engineer | Author | Entrepreneur| Most Opinions are my own with a few exceptions of what looks funny or what I agree with ✈️

Jeff Tatarchuk @jtatarchuk
1K Followers 2K Following Co-founder @tensorwavecloud - Pioneering the next wave of AI compute. Need GPUs? DM me.
Ivelina Petrova @ivelinapetrovaX
28 Followers 785 Following Industrial Management and development Master Degree and Architect in Architecture [email protected] [email protected] [email protected]
ADITYA KABRA @adityakabra
285 Followers 1K Following I love science, entrepreneurship, and building things. This is my playground to run little experiments and share my ideas, projects, and learnings.
Rushi @RushiOnFire_
37 Followers 418 Following AI Engineer | ML | Deep Learning Research | NLP | Chess | Cricket | The dream is to meet Geoffrey Hinton, Ian Goodfellow, Yann LeCun, Yoshua Bengio
Ensar Kaya @ensarkaya65
9 Followers 83 Following Software Engineer & AI Enthusiast Bilkent CS🎓 TU Munich Informatics 🎓
Nir Gottlieb @nirg2014
10 Followers 142 Following
Abdulrahman Tabaza @embed_dim
3 Followers 708 Following enjoyer of various vector spaces, encoders and modalities
Shivakumar KY @shiva0010131
71 Followers 1K Following THINKING on AI / AGI / Technology / Robotics / Advancement.
Itxaso Baskero Dorrea.. @IDorreak
9 Followers 336 Following

christian cch @chris_cch_
187 Followers 3K Following
AK @_akhaliq
309K Followers 3K Following AI research paper tweets, ML @Gradio (acq. by @HuggingFace 🤗) dm for promo follow on Hugging Face: https://t.co/q2Qoey80Gx
Sebastian Raschka @rasbt
266K Followers 906 Following Machine learning & AI researcher writing at https://t.co/A0tXWzG1p5. LLM research engineer @LightningAI. Previously stats professor at UW-Madison.
Mark Tenenholtz @marktenenholtz
114K Followers 544 Following Head of AI @PredeloHQ. XGBoost peddler, transformer purveyor.
elvis @omarsar0
189K Followers 483 Following Building with LLMs @dair_ai • Prev: Meta AI, Galactica LLM, PapersWithCode, Elastic, PhD • Creator of the Prompting Guide (~4M learners)
Lucas Beyer (bl16) @giffmana
56K Followers 444 Following Researcher (Google DeepMind/Brain in Zürich, ex-RWTH Aachen), Gamer, Hacker, Belgian. Mostly gave up trying mastodon as [email protected]
PyTorch @PyTorch
379K Followers 77 Following Tensors and neural networks in Python with strong hardware acceleration. PyTorch is an open source project at the Linux Foundation. #PyTorchFoundation
Soumith Chintala @soumithchintala
186K Followers 877 Following Cofounded and lead @PyTorch at Meta. Also dabble in robotics at NYU. AI is delicious when it is accessible and open-source.
Jeremy Howard @jeremyphoward
222K Followers 5K Following 🇦🇺 Co-founder: @AnswerDotAI & @FastDotAI ; Hon Professor: @UQSchoolITEE ; Digital Fellow: @Stanford

Alfredo Canziani @alfcnz
86K Followers 268 Following Musician, math lover, cook, dancer, 🏳️🌈, and an ass prof of Computer Science at New York University
Dmytro Mishkin 🇺�.. @ducha_aiki
18K Followers 591 Following Marrying classical CV and Deep Learning. I do things, which work, rather than being novel, but not working.
abhishek @abhi1thakur
81K Followers 662 Following 🤗 I build AutoTrain @huggingface 👨🏽💻 World's First 4x Grand Master @kaggle 🎥 YouTube 100k+: https://t.co/BHnem8fTu5 ⭐ GitHub Star
merve @mervenoyann
55K Followers 4K Following open-sourceress at @huggingface 🧙🏻♀️ proud mediterrenean 🍋 I do TL;DR on ML papers sometimes. RTs != endorsements
Hugging Face @huggingface
343K Followers 189 Following The AI community building the future. https://t.co/VkRPD0VKaZ #BlackLivesMatter #stopasianhate
Horace He @cHHillee
23K Followers 448 Following Working at the intersection of ML and Systems @ PyTorch "My learning style is Horace twitter threads" - @typedfemale
Sanyam Bhutani @bhutanisanyam1
35K Followers 994 Following 👨💻 Sr Data Scientist @h2oai | Previously: @weights_biases 🎙 Podcast Host @ctdsshow 👨🎓 International Fellow @fastdotai 🎲 Grandmaster @Kaggle
Radek Osmulski 🇺�.. @radekosmulski
25K Followers 552 Following Resources to take your Machine Learning skills to the next level 🧪 Senior Data Scientist, RecSys @NVIDIAAI 🏫 @fastdotai trained DL Eng 📝 https://t.co/By87iXx5Pu
Julien Chaumond @julien_c
46K Followers 1K Following Co-founder and CTO at @huggingface 🤗. ML/AI for everyone, building products to propel communities fwd. @Stanford + @Polytechnique
clem 🤗 @ClementDelangue
90K Followers 5K Following Co-founder & CEO @HuggingFace 🤗, the open and collaborative platform to build machine learning
Michael Black @Michael_J_Black
58K Followers 638 Following Director, Max Planck Institute for Intelligent Systems (@MPI_IS). Chief Scientist @meshcapade. Building 3D digital humans using vision, graphics, and learning.

Mike Schroepfer @schrep
104K Followers 278 Following Partner @Gigascale, Sr Fellow (Formerly CTO) @Meta, founder @AdditionalVent, . Investing in tech and science to fight climate change. AI
Aaron Defazio @aaron_defazio
6K Followers 359 Following Research Scientist at Meta working on optimization. Fundamental AI Research (FAIR) team
Diamond Bishop 🤖 @diamondbishop
1K Followers 993 Following pro-basilisk, techno-optimist. augmenting human capabilities with AI at the future sovereign enclave of @augmendtech. formerly AI stuff @meta|@amazon|@microsoft
onodera @0verfit
8K Followers 647 Following @kaggle Grandmaster (🥇0🥈6 🥉1) at @NVIDIA @RAPIDSAI / @splatoonJP オールX 24
Chris Perry @thechrisperry
3K Followers 215 Following @GoogleColab Product lead, former data scientist, occasional writer
Albumentations @albumentations
83 Followers 1 Following Albumentations: A fast and flexible image augmentation library for machine learning by @viglovikov
Reflex Robotics @ReflexRobot
499 Followers 1 Following We're building affordable general-purpose robots
Alexander Koch @alexkoch_ai
4K Followers 196 Following Founder of Tau Robotics | Z Fellow | Emergent Ventures Fellow 2024
District of West Vanc.. @WestVanDistrict
5K Followers 399 Following Official account for the District of West Vancouver. This account is monitored 8 a.m.–4:30 p.m., Monday–Friday. Request service: 604-925-7100
North Vancouver RCMP @nvanrcmp
17K Followers 2K Following This account is not monitored 24/7. Call (604)-985-1311 to report a crime or 911 in an emergency. Terms of use: https://t.co/djD2Aubda9
City of North Vancouv.. @CityOfNorthVan
12K Followers 706 Following Official account for City of North Vancouver, Canada. After hours emergencies 604-988-2212. Report issues w/ CityFix app Terms of use: https://t.co/48GyrmZJKy
District of North Van.. @NVanDistrict
14K Followers 465 Following Official account for the District of North Vancouver, monitored Mon. to Fri. 8am-4:30pm. Located on traditional Tsleil-Waututh, Squamish & Musqueam territory.
miwojc.llm ;) @miwojcz
492 Followers 3K Following AI. Machine Learning. @fastdotai International Fellow.


activewarp @activewarp
83 Followers 149 Following
Jordi Clive @JordiClive
115 Followers 373 Following Lead Deep Learning Engineer @ChattermillAI • ML Researcher @laion_ai • SFT Team OpenAssistant • @huggingface contributor • NLG Research @imperialcollege
Jack Langerman @jacklangerman
336 Followers 203 Following

Darragh @gonedarragh
536 Followers 290 Following AI researcher / Kaggle GM ... here for deep learning, machine learning and whats going on in politics and the world.
Shamik Bose @BoseShamik
354 Followers 508 Following PhD, Senior Researcher XAI | Will talk at length about the harms and considerations for the current state of AI | Views my own | he/him
Alaa El-Nouby @alaa_nouby
526 Followers 302 Following Research Scientist at @Apple. Previous: @Meta (FAIR), @Inria, @MSFTResearch, @VectorInst and @UofG . Egyptian 🇪🇬 Deprecated twitter account: @alaaelnouby
Hugo Laurençon @HugoLaurencon
556 Followers 182 Following ML research engineer @huggingface Les yeux rivés sur la loss

Yue Wang @yuewang314
5K Followers 923 Following Assistant Professor @ USC CS and part-time Research Scientist @ Nvidia Research. Previous: EECS PhD @ MIT CSAIL. Opinions are mine.
Monika Wysoczańska @mkwysoczanska
167 Followers 106 Following PhD Student in Multimodal Learning at @WUT_edu | @WiCVworkshop organizer | Visiting Researcher @valeoai
Jason Ramapuram @jramapuram
788 Followers 391 Following ML Research Scientist MLR | Formerly: DeepMind, Qualcomm, Viasat, Rockwell Collins | Swiss-minted PhD in ML | Barista alumnus ☕ @ Starbucks | 🇺🇸🇮🇳🇱🇻🇮🇹
Essential AI @essential_ai
2K Followers 5 Following Our mission is to deepen the partnership between humans and computers, unlocking collaborative capabilities that far exceed what could be achieved today.

Mistral AI @MistralAI
90K Followers 0 Following Fast, open-source and secure language models. Join us https://t.co/INALdNGvCP
Grant Van Horn @Grant_Van_Horn
746 Followers 62 Following Assistant Prof @ UMass Amherst; Visiting Scientist @CornellBirds; Passion for public engagement apps powered by ML: @MerlinBirdID, @inaturalist, @seekbyinat.
Yu Su @ysu_nlp
6K Followers 857 Following Dist. Assist. Prof.@OhioState, Director @osunlp, 20% Researcher@Microsoft. I like to think about intelligence, artificial or biological
efxmarty @efxmarty
343 Followers 134 Following ML Engineer at @huggingface Optimization team. efxmarty/fxmarty elsewhere
Ben (e/sqlite) @andersonbcdefg
3K Followers 3K Following 🤖 Computer scientist, next-word-prediction enjoyer 📊 Prev. research fellow @ Stanford RegLab 🛠️ bUiLdiNg sOmeThiNg nEw (https://t.co/mdYPZmjSzN - YC S23) 🏳️🌈
Polina Kirichenko @polkirichenko
3K Followers 1K Following PhD student at New York University, Visiting Researcher at @MetaAI FAIR Labs 🇺🇦

Alexandre Gramfort @agramfort
7K Followers 1K Following Building the future of neural interfaces from EMG signals at Meta Reality Labs. Ex Research director at Inria, scikit-learn co-founder, mne-python creator.
Julie Fredrickson @AlmostMedia
39K Followers 6K Following Founded & sold shit. Angel invest & early stage (https://t.co/AAXsJuYK25) #FreedomToCompute married @alexlmiller via @Uchicago & Rockies. Autist Oracle Montana
Garry Tan @garrytan
432K Followers 4K Following President & CEO @ycombinator —Founder @Initialized—PM/designer/engineer who helps founders—YouTuber—San Francisco Democrat accelerating the boom loop—e/acc
Ron Conway @RonConway
114K Followers 75 Following

kyutai @kyutai_labs
6K Followers 6 Following
Stephanie Chan @scychan_brains
3K Followers 2K Following Senior Research Scientist at DeepMind. Artificial and biological brains 🤖 🧠 Views are my own

PicoCreator (🇸🇬.. @picocreator
2K Followers 162 Following Builds Attention-Free Transformer (https://t.co/YL7CbNYKBs) from scratch - CEO @ https://t.co/kQHiGtzJWr Also built k8s tools, uilicious & GPU.js (https://t.co/OIfnI1EPU7)
Patrick Labatut @monsieurlabatut
71 Followers 32 Following Research Engineering Manager at Meta (FAIR)
Hailey Schoelkopf @haileysch__
3K Followers 811 Following she/her | research scientist @aiEleuther | LLM training/infra, eval, data | LM Evaluation Harness maintainer
Andreas Tolias Lab @AToliasLab
4K Followers 683 Following to understand intelligence and develop technologies by combining neuroscience and AI

One of the big questions about @huggingface accelerate during distributed @PyTorch training is how do you optimize your DataLoaders to make use of your multiple GPUs. Happy to share this all with you via another wonderful animated tutorial! youtube.com/watch?v=9Vfauv…

Excited to announce we've raised 62.7M$ at 1.04B$ valuation, led by Daniel Gross, along with Stan Druckenmiller, NVIDIA, Jeff Bezos, Tobi Lutke, Garry Tan, Andrej Karpathy, Dylan Field, Elad Gil, Nat Friedman, IVP, NEA, Jakob Uszkoreit, Naval Ravikant, Brad Gerstner, and Lip-Bu…
We trained 200+ ablation models to validate our processing decisions, and we share all the code you need to reproduce our setup, along with our dataset comparison ablation models checkpoints! Find out all abut 🍷 FineWeb on the 🤗 model page: huggingface.co/datasets/Huggi…
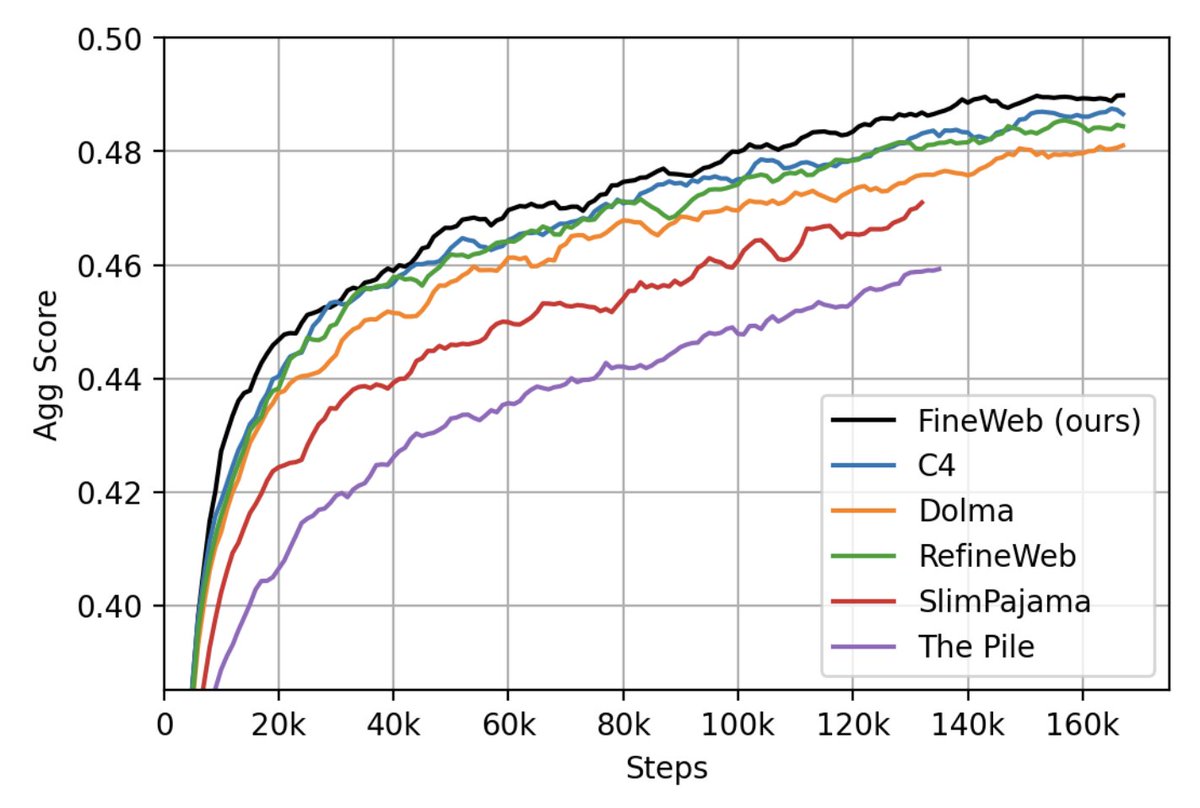
We have just released 🍷 FineWeb: 15 trillion tokens of high quality web data. We filtered and deduplicated all CommonCrawl between 2013 and 2024. Models trained on FineWeb outperform RefinedWeb, C4, DolmaV1.6, The Pile and SlimPajama!
Datasets might be more impactful than models at this point and this may be the GPT4 of datasets. Courtesy of the amazing Guilherme who trained Falcon & the @huggingface team!
We have just released 🍷 FineWeb: 15 trillion tokens of high quality web data. We filtered and deduplicated all CommonCrawl between 2013 and 2024. Models trained on FineWeb outperform RefinedWeb, C4, DolmaV1.6, The Pile and SlimPajama!
With no changes from Llama2 to Llama3 architecture, the importance of data has never been so clear 🦙 While Idefics2 was heavily advertised, our efforts on data didn't shine ☀️ as much, so here are the 3 most important data updates we did: 1. 🍵 The Cauldron, a compilation of 50…
Not everyone is aware but the fact that llama3 has been added to HF on day one means that right away, you can easily run it on @AWS Sagemaker, @Microsoft AzureML, @googlecloud Vertex and the @huggingface hosted solutions (autotrain, spaces, serverless and dedicated endpoints).…
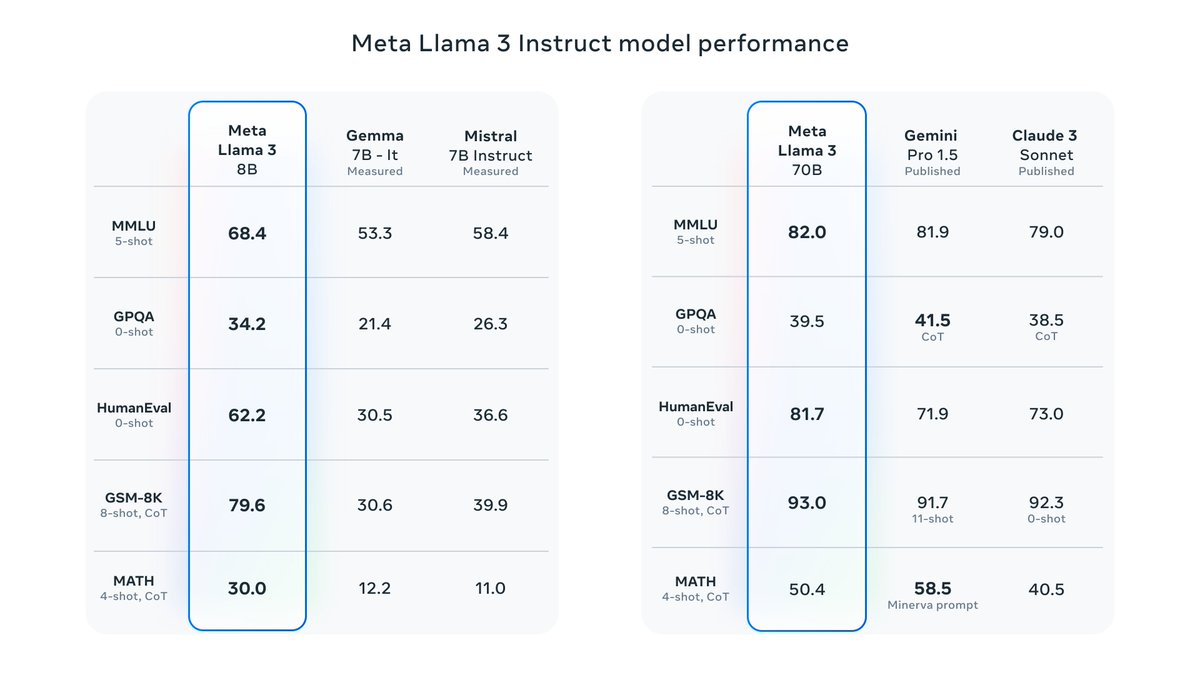
Llama3 8B and 70B are out, with pretty exciting results! * The ~400B is still training but results already look promising. * Meta's own Chat interface is also live at meta.ai * TorchTune integration is shortly going live: github.com/pytorch/torcht…

It’s here! Meet Llama 3, our latest generation of models that is setting a new standard for state-of-the art performance and efficiency for openly available LLMs. Key highlights • 8B and 70B parameter openly available pre-trained and fine-tuned models. • Trained on more…

torchtune provides: - LLM implementations in native-PyTorch - Recipes for QLoRA, LoRA and full fine-tune - Popular dataset-formats and YAML configs - Integrations with @huggingface Hub, @AiEleuther Eval Harness, bitsandbyes, ExecuTorch and many more [3/5]
Really excited to officially release torchtune: a PyTorch-native library for easily fine-tuning LLMs! Code: github.com/pytorch/torcht… Blog: pytorch.org/blog/torchtune… Tutorials: pytorch.org/torchtune/stab… [1/5]
Today we release Idefics2 our newest 8B Vison-Language Model! 💪 With only 8B parameters Idefics is one of the strongest open models out there 📋 We used multiple OCR datasets, including PDFA and IDL from @wightmanr and @m_olbap, and increased resolution up to 980x980 to improve…
Introducing Idefics2, the strongest Vision-Language-Model (VLM) < 10B! 🚀 Idefics2 comes with significantly enhanced capabilities in OCR, document understanding, and visual reasoning. 💬📄🖼️ TL;DR; 📚 8B base and instruction variant 🖼️ Image + text inputs ⇒ Text output 📷…
@wightmanr @mrclbschff That does sound great! Maybe I should do a weekend project in it just for the educational aspect.
@wightmanr @mrclbschff Never really looked at Kotlin because JVM... hehe!!


@ducha_aiki @wightmanr Width, depth, mlp size, attention heads, etc. see also arxiv.org/abs/2305.13035

@wightmanr You really created a masterwork with timm. Loved it from the day I saw it

With text-to-music models really starting to heat up, today I'm sharing a new, open model 🚀 🎶 musicgen-songstarter-v0.2 🎶 A large, stereo MusicGen that acts as a useful tool for music producers Compared to v0.1, its 2x the size & trained on 3x more hand-curated samples


@wightmanr One of the best implemented and maintained model zoos there is, amazing project!

We are establishing a third office in Vancouver - in addition to our London and Mountain View locations. This will be an AI hub to accelerate our cutting edge research in Embodied AI. This office will be led by @Jamie_Shotton, our Chief Scientist who will be relocating, and we…

Trends for United States
You might like









