
Manish Pandey 🧬 @Manish_GenAI
Co-Founder @FreeDoctr 🧬⚕️ , Building a collaborative Platform for Patients and Doctors. 🌐🩻 #GraphML, #GeometricDL, #Gen AI #ML ,#RL, #LLM, #AIForHealthcare linkedin.com/in/manish-gena… Joined August 2021-
Tweets969
-
Followers472
-
Following7K
-
Likes3K

🚀 New Survey Alert! 📄 The Landscape of Agentic Reinforcement Learning for LLMs: A Survey By 16 top institutions (Oxford, NUS, UIUC, UCL, and more) We explore how LLMs evolve from passive text generators → proactive agents with planning, memory, tool use, reasoning & beyond.…





This is a new 100-page RL for LLM literature review. It appears fairly complete. It also covers static/dynamic data and frameworks. And it has some nice figures! 🔗arxiv.org/abs/2509.08827

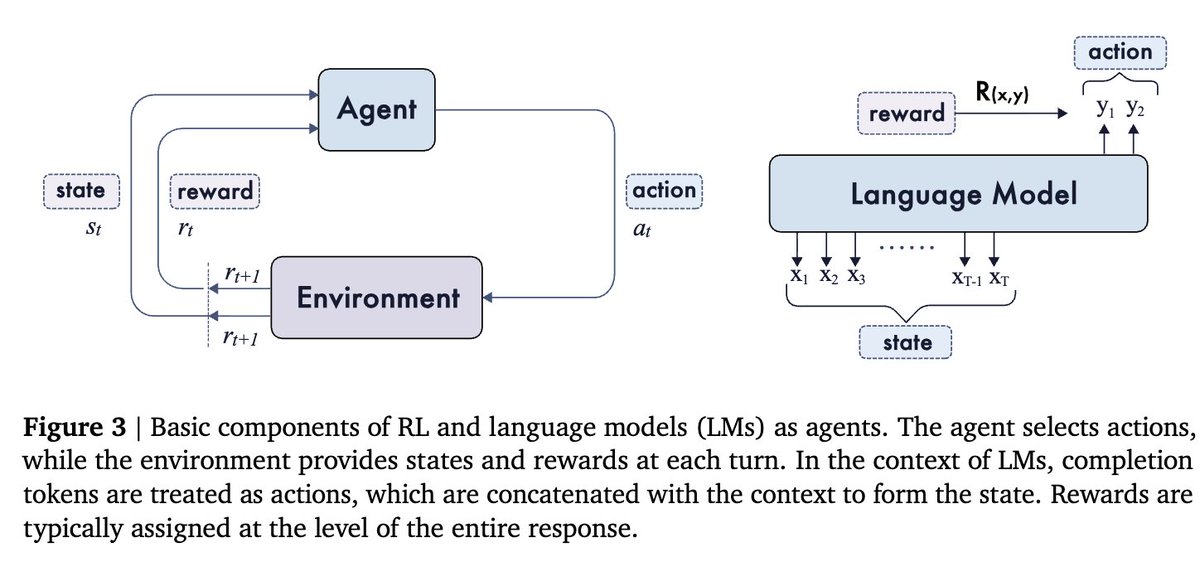


Another great @GoogleDeepMind paper. Shows how to speed up LLM agents while cutting cost and keeping answers unchanged. 30% lower total cost and 60% less wasted cost at comparable acceleration. Agents plan step by step, so each call waits for the previous one, which drags…


Biomni-R0: New Agentic LLMs Trained End-to-End with Multi-Turn Reinforcement Learning for Expert-Level Intelligence in Biomedical Research Researchers from Stanford University and UC Berkeley introduced a new family of models called Biomni-R0, built by applying reinforcement…


Compute is not a big deal for LLMs now, but memory is. It's an idea used in XQuant – a new method by @UCBerkeley created to reduce memory use up to 12x. - XQuant doesn't store usual KV cache - It quantizes and stores only X - the layer input activations - When needed, it…


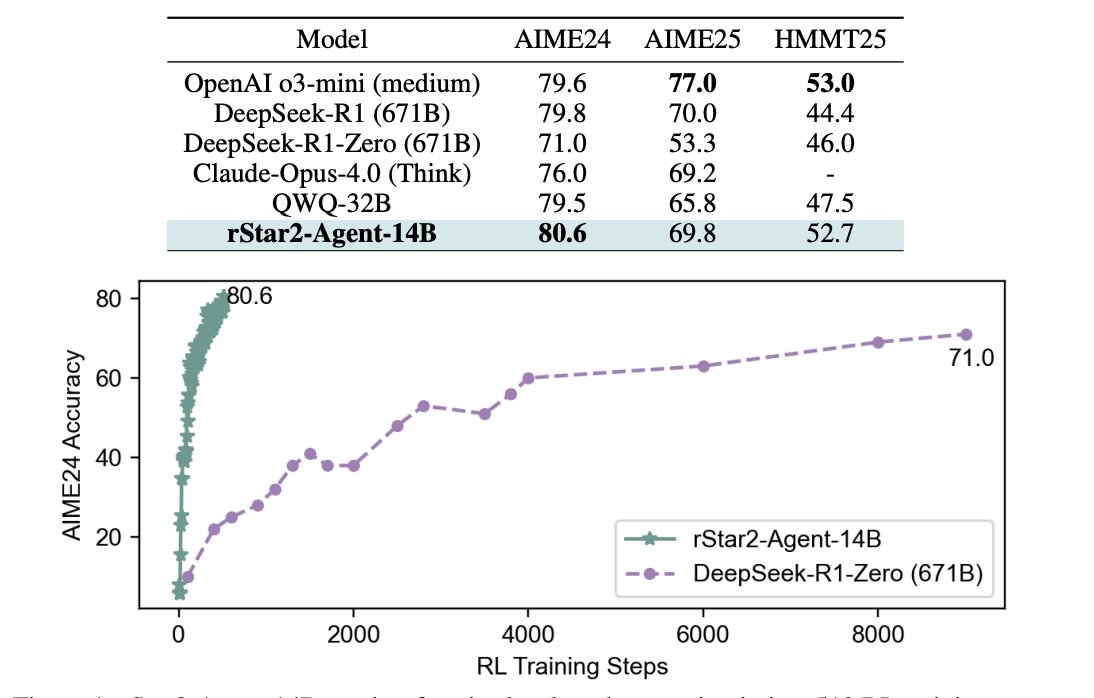
A 14B model just beat a 671B model on math reasoning. Here’s how Microsoft’s rStar2-Agent achieves frontier math performance in 1 week of RL training - by “thinking smarter, not longer.” 🧵
PAN (Physical, Agentic, and Nested) - a very interesting version of world models, based on the new building principles for such models. It's based on a complex mountaineering scenario and uses multimodal inputs: sights, sounds, sensations, body strain, temperature, text, etc.…

🔍 How do we teach an LLM to 𝘮𝘢𝘴𝘵𝘦𝘳 a body of knowledge? In new work with @AIatMeta, we propose Active Reading 📙: a way for models to teach themselves new things by self-studying their training data. Results: * 𝟔𝟔% on SimpleQA w/ an 8B model by studying the wikipedia…


What makes the HRM model work so well for its size on @arcprize? We ran ablation experiments to find out what made it work Our findings show that you could replace the "hierarchical" architecture with a normal transformer with only a small performance drop We found that an…


M3-Agent: A Multimodal Agent with Long-Term Memory Impressive application of multimodal agents. Lots of great insights throughout the paper. Here are my notes with key insights:


3D Object Tracking without Training Data? In our @Nature Machine Intelligence paper (nature.com/articles/s4225…), we recast 3D tracking as an inverse neural rendering task where we fit a scene graph to an image that best explains this image. The method generalizes to completely…

Part I: Tricks or Traps? A Deep Dive into RL for LLM Reasoning "we demonstrate that employing only two techniques, i.e., advantage normalization (group-level mean, batch-level std) and token-level loss aggregation, can unlock the learning capability of critic-free policies using…


Current multimodal LLMs excel in English and Western contexts but struggle with cultural knowledge from underrepresented regions and languages. How can we build truly globally inclusive vision-language models? We are introducing CulturalGround, a large-scale dataset with 22M…


Want to add that even with language-assisted visual evaluations, we're seeing encouraging progress in vision-centric benchmarks like CV-Bench (arxiv.org/abs/2406.16860) and Blink (arxiv.org/abs/2404.12390), which repurpose core vision tasks into VQA format. These benchmarks do help…

Want to add that even with language-assisted visual evaluations, we're seeing encouraging progress in vision-centric benchmarks like CV-Bench (arxiv.org/abs/2406.16860) and Blink (arxiv.org/abs/2404.12390), which repurpose core vision tasks into VQA format. These benchmarks do help…

Summary of GPT-OSS architectural innovations: 1. sliding window attention (ref: arxiv.org/abs/1901.02860) 2. mixture of experts (ref: arxiv.org/abs/2101.03961) 3. RoPE w/ Yarn (ref: arxiv.org/abs/2309.00071) 4. attention sinks (ref: streaming llm arxiv.org/abs/2309.17453)

To guys diving into fine-tuning open-source MoEs today: check out ESFT, our customized PEFT method for MoE models. Train with 90% less parameters, gain 95%+ task perf and keep 98% general perf :)

To guys diving into fine-tuning open-source MoEs today: check out ESFT, our customized PEFT method for MoE models. Train with 90% less parameters, gain 95%+ task perf and keep 98% general perf :)


1/N 🚀 Launching LEANN — the tiniest vector index on Earth! Fast, accurate, and 100% private RAG on your MacBook. 0% internet. 97% smaller. Semantic search on everything. Your personal Jarvis, ready to dive into your emails, chats, and more. 🔗 Code: github.com/yichuan-w/LEANN 📄…


📢NEW POSITION PAPER: Use Sparse Autoencoders to Discover Unknown Concepts, Not to Act on Known Concepts Despite recent results, SAEs aren't dead! They can still be useful to mech interp, and also much more broadly: across FAccT, computational social science, and ML4H. 🧵


Attention is all you need - but how does it work? In our new paper, we take a big step towards understanding it. We developed a way to integrate attention into our previous circuit-tracing framework (attribution graphs), and it's already turning up fascinating stuff! 🧵

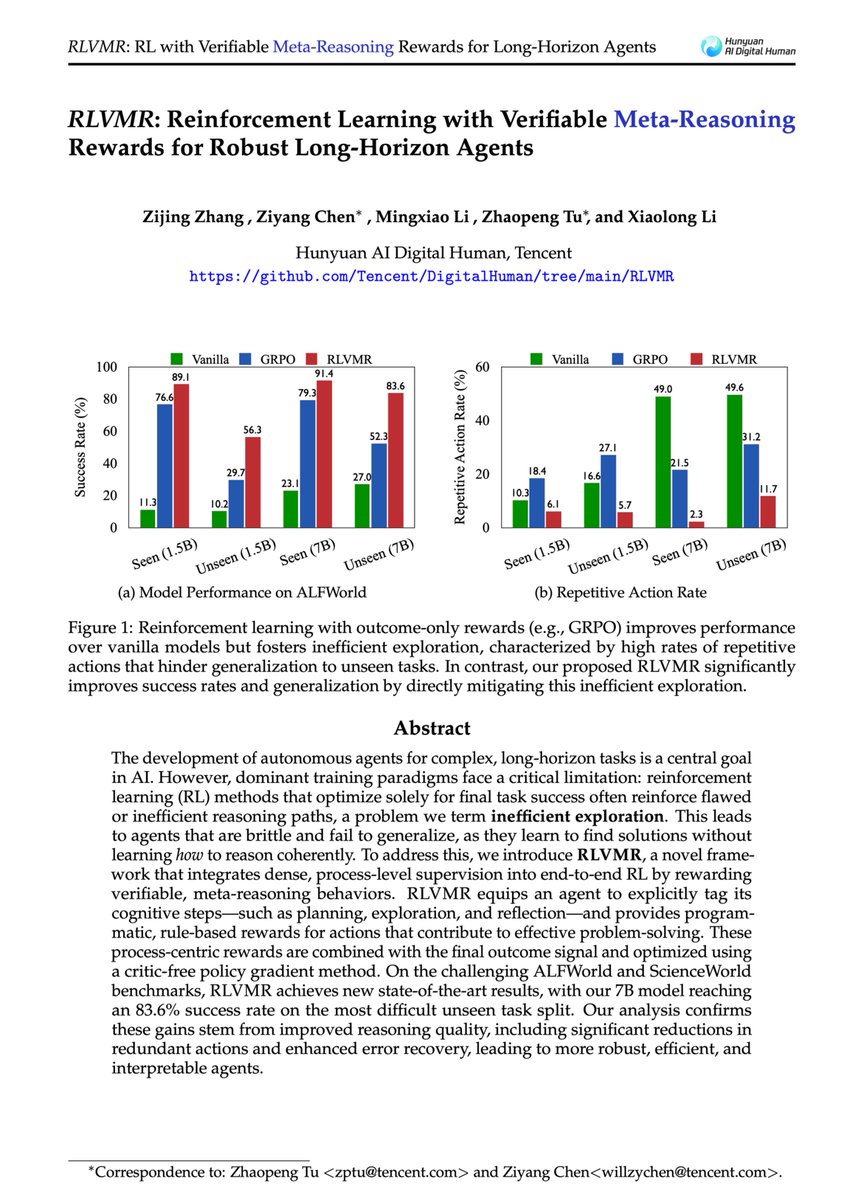
Are RL agents truly learning to reason, or just finding lucky shortcuts? 🤔 Introducing RLVMR: Reinforcement Learning with Verifiable Meta-Reasoning Rewards — a novel framework that rewards not just outcomes, but the quality of reasoning itself, creating more robust and…

Kimberly @simpson_kimberl
1K Followers 3K Following
DoloresHenry @0vO22CPeqmpuFS5
4 Followers 202 Following
Ervloohiel @Ervloohiel9025
8 Followers 1K Following
SandyAlsopp @ub2OYB2W3Hb5K
0 Followers 152 Following
Wanda @barnes_wanda16
129 Followers 3K Following
RubySpenser @8CS46WwAdbqapY
0 Followers 434 Following
Tiffany @mazzaferro_tiff
241 Followers 3K Following
Wiekuiv @Wiekuiv930765
4 Followers 565 Following
Brittany @e_brittany55
256 Followers 3K Following
Reid Borer @ReidBorer22446
36 Followers 2K Following
VenusTrevelyan @307XuQvm1vZ3KNw
0 Followers 490 Following
Cleora Dare @CleoraD97124
56 Followers 3K Following
BuffettStyle🇺🇸 @Ofloufau323664
47 Followers 2K Following 15-30% Monthly | 2 High-Conviction Stocks.Short-Term Gains: 15-20% in Days/Weeks.DM "JOIN" for WhatsApp Alerts. Live Trade Signals • Market Analysis
Yuan Liu @YuanLiu41955461
2K Followers 1K Following Assistant professor at @hkust. I'm working on 3D vision and graphics. We are constantly recruiting PhD and visiting students.
Siru Ouyang @Siru_Ouyang
904 Followers 881 Following CS PhD candidate @IllinoisCDS. Alumni @sjtu1896.
Jason Lee @jason_lee328
271 Followers 523 Following PRIOR @allen_ai AI and Robotics @RAIVNLab @uwcse Robot Learning Masters @ UW w/ R. Krishna, D. Fox
Peiyang Song @p_song1
346 Followers 219 Following CS Major w/ Robotics Minor @Caltech. #AI Researcher @UCBerkeley & @Stanford. Applying for 26Fall PhD positions in Computer Science.
Harkirat Behl @BehlHarkirat
2K Followers 322 Following Crafting Phi models @ Microsoft Research ''Synthetic Data''
REITsCashflow🇺🇸 @Dalporx0490054
38 Followers 2K Following 15-30% Monthly | 2 High-Conviction Stocks.Short-Term Gains: 15-20% in Days/Weeks.DM "JOIN" for WhatsApp Alerts. Live Trade Signals • Market Analysis
Lavon Cronin @CroninLavo77863
110 Followers 4K Following
Susan Sacchetti @SacchettiS78544
161 Followers 3K Following
Edorigem @Edorigem876
44 Followers 1K Following
Navreet Kaur @navreeetkaur
318 Followers 788 Following PhD @uw_ischool. Research in NLP, Human-AI Interaction, AI Governance. She/her
Div @hurtbadly2
119 Followers 1K Following Scientific computing / Ostracizing with Julia Cryo-ET, HEP, HPC 🍎🟣🍏
Pasquale Graham-Ullri... @PUllrich30282
26 Followers 3K Following
REITsDaily🇺🇸 @Ceaalkee6782
47 Followers 2K Following 15-30% Monthly | 2 High-Conviction Stocks.Short-Term Gains: 15-20% in Days/Weeks.DM "JOIN" for WhatsApp Alerts. Live Trade Signals • Market Analysis
AlgoTradeEdge🇺🇸 @Jiirxau798744
51 Followers 2K Following 15-30% Monthly | 2 High-Conviction Stocks.Short-Term Gains: 15-20% in Days/Weeks.DM "JOIN" for WhatsApp Alerts. Live Trade Signals • Market Analysis
Mihir Parmar @Mihir3009
713 Followers 773 Following Research Scientist @Google | Innovating in NLP | PhD in CS @ASU
Droduv @Droduv5610
90 Followers 2K Following
Bakary Jammeh @BakaryJamm58365
70 Followers 2K Following Humble yourselves, therefore, under the mighty hand of God so that at the proper time He may exalt you, casting all your anxieties on Him..✝️🙏🏿🫂
Nan HUO @NanHUO9637
562 Followers 842 Following CS PhD Student @HKUniversity. Previously M.S. @JohnsHopkins.
Alpay Ariyak @AlpayAriyak
3K Followers 3K Following Post-Training Lead @ Together AI | OpenChat Project Lead (#1 7B LLM on Arena for 2+ months, 2M+ downloads) | DeepCoder, DeepSWE
Mu Cai @MuCai7
2K Followers 1K Following Research Scientist @GoogleDeepMind, Gemini Multimodal. Previous: Ph.D. @WisconsinCS | Intern @MSFTResearch @Cruise
Hyungjoo Chae @hyungjoochae
356 Followers 782 Following PhD student @gtcomputing | M.S. from Yonsei University | Research intern at @LG_AI_Research
SmartGuard @Sogi184119
50 Followers 634 Following

Brukxec @Brukxec9834100
24 Followers 560 Following
Hongsuk Benjamin Choi @redstone_hong
514 Followers 398 Following robotics & computer vision. PhD @Berkeley_AI | prev @ Seoul National University | Intern at Amazon FAR
Kaiyu Yang @KaiyuYang4
4K Followers 2K Following Research Scientist at @Meta Fundamental AI Research (FAIR), New York. Previously: Postdoc @Caltech, PhD @PrincetonCS, Undergrad @Tsinghua_Uni.
abderrahim zine @abderrahimzine6
46 Followers 3K Following
Shoubin Yu @shoubin621
760 Followers 855 Following Ph.D. Student at @unccs @uncnlp, advised by @mohitban47. Interested in multimodal AI.
David J Phillips @davj
19K Followers 13K Following Founder & CEO @tryfondo – accounting & tax on autopilot for 1,000+ startups (next deadline: Oct 15). Angel: Flexport, LiquidDeath, Rippling, Cluely, 100+.
Crouniec @Crouniec775814
52 Followers 1K Following
Uguofab @Uguofab057
41 Followers 1K Following
Seeixe @Seeixe043
42 Followers 619 Following
lolbin7 @lolbin7
10 Followers 52 Following
Silvia @Swererqe9606
0 Followers 263 Following Every morning when I wake up, I am grateful for your company.
Daija Rowe @DRowe57081
57 Followers 2K Following
Cirjam @Cirjam883
48 Followers 1K Following
Mabelle Wolf @MabelleWol22054
102 Followers 4K Following


Da Yin @Wade_Yin9712
1K Followers 562 Following Postdoc @Meta FAIR | PhD @uclanlp | BA @PKU1898 | Amazon PhD Fellow 2023
Chenlu Ye @ye_chenlu
255 Followers 264 Following Ph.D. student at UIUC, interested in RL reasoning, agent

Jeff Wang @jeffwsurf
10K Followers 311 Following CEO @windsurf, Host of https://t.co/Tfkpdmdkzf + Rich Dad Crypto, GP @RandRCapital, AI @ https://t.co/AxabQu0jj6




Alex Hägele @haeggee
827 Followers 663 Following Fellow @AnthropicAI + PhD Student in Machine Learning @ICepfl MLO. MSc/BSc from @ETH_en. Previously: Student Researcher @Apple MLR
Sang Cho @Saaaang94
2K Followers 470 Following reasoning @xAI | prev-founding engineer @anyscalecompute | senior committer of @raydistributed | committer @vllm_project Sglang | Github: rkooo567
Tyler Griggs @tyler_griggs_
684 Followers 356 Following CS PhD student @UCBerkeley Sky Lab, co-leading @NovaSkyAI and building SkyRL | Previously @GoogleCloud infra | @Harvard 2020

Jessy Lin @realJessyLin
3K Followers 885 Following PhD @Berkeley_AI, visiting researcher @AIatMeta. Interactive language agents 🤖 💬
Nitish ⚡️ @nitishmutha
4K Followers 347 Following Co-founder and CTO @GenieAI - Building the world’s best AI Legal Drafter. @UCL alum.
Kawin Ethayarajh @ethayarajh
4K Followers 939 Following Assistant Professor @ChicagoBooth @UChicago. Behavioral machine learning. PhD @StanfordAILab @stanfordnlp.
Bert Maher @tensorbert
3K Followers 353 Following I’m a software engineer building high-performance kernels and compilers at Anthropic! Previously at Facebook/Meta (PyTorch, HHVM, ReDex)
Amy Pavel @amypavel
3K Followers 654 Following Asst Prof UC Berkeley EECS. Prev @UTCompSci, @apple, @cmuhcii. HCI+AI+A11y. Creating human-AI tools for effective and accessible communication. 🦋
Ian Arawjo @IanArawjo
2K Followers 1K Following Asst Prof @UMontreal, PhD @CornellInfoSci. Creator of @chainforge_ai. Programming and culture, intercultural CS, LLM evaluation. Prev: Postdoc @HarvardHci
Minna Song @minnasong
1K Followers 27 Following CEO & Co-Founder @Elise_AI Building AI to transform housing & healthcare
Jianfei Yang @Jianfei_AI
1K Followers 178 Following Assistant Professor @NTUsg Prev Researcher @Harvard @UCBerkeley @UTokyo_News
Olivier Duchenne @inventorOli
2K Followers 26 Following I post about my DIY robots hardware hobby. Robotics research lead at Mistral AI. Ex-Meta/FAIR, core contributor to Llama 3. ENS PhD. Repeat founder.
Cristina Scheau @cristina_scheau
1K Followers 774 Following head of ChatgptSearch@OpenAI, prev 🚗, Meta
Cheng Lu @clu_cheng
8K Followers 202 Following Member of technical staff @OpenAI. PhD @Tsinghua_Uni. Interested in scalable generative models.

Ji Lin @jilin_14
6K Followers 944 Following Research @Meta Superintelligence Lab | Prev: Research @OpenAI; PhD @MIT
Andre Saraiva @andresnds
3K Followers 138 Following o1-preview, o1-mini, o1, o3-mini,o4-mini, o3... Reasoning Researcher at OpenAI. Ex-DeepMind.

Chris @chatgpt21
16K Followers 784 Following Agi 2029 - Applied in RL, CL, and generalization | Program Manager | Investing in early startups 📈 E/CC 🦾🤖



Miles Wang @MilesKWang
3K Followers 1K Following Researcher @OpenAI. Beneficial and safe AGI. Prev @Harvard

Fang-Pen Lin 🇺🇸 @fangpenlin
4K Followers 2K Following AI nerd (MAZE https://t.co/BsQE7sP5B2), one-person-army software engineer @CakeLens @BeanHubApp. Opinions are my own. GH: https://t.co/LSwKjBDjy4
Cerebras @CerebrasSystems
34K Followers 256 Following The world's fastest AI inference and training. Try the latest open models at: https://t.co/jREGhLI2nj
Siru Ouyang @Siru_Ouyang
904 Followers 881 Following CS PhD candidate @IllinoisCDS. Alumni @sjtu1896.
Yuan Liu @YuanLiu41955461
2K Followers 1K Following Assistant professor at @hkust. I'm working on 3D vision and graphics. We are constantly recruiting PhD and visiting students.

Andrew Feldman @andrewdfeldman
4K Followers 209 Following CEO and Founder @CerebrasSystems. I build teams that solve hard problems, grow heirloom tomatoes, dance tango and love Vizslas
Pingbang Hu 🇹🇼 @PingbangHu
350 Followers 268 Following Ph.D. candidate @UofIllinois. Alumni @Umich & @SJTU1896. Interned @amazon & @jouhouken. Data-centric trustworthy machine learning and AI.
Sunny Sanyal @SunnySanyal9
1K Followers 521 Following PhD candidate @UTexasECE| Intern @GoogleDeepMind, @LightningAI & @AmazonScience | On Job market
Vijay Chidambaram @vijay_ut
224 Followers 577 Following Professor @utcompsci. Work on all things systems and storage. Lead @utsaslab. Prev: @WisconsinCS. Views my own.
Renwen (Alice) Zhang @renwenzhang
1K Followers 1K Following Assistant Professor @NTUsg @wkwschool | Director of SWEET Lab | PhD @NorthwesternU | technology & wellbeing; HCI; health & interpersonal communication
Jason Lee @jason_lee328
271 Followers 523 Following PRIOR @allen_ai AI and Robotics @RAIVNLab @uwcse Robot Learning Masters @ UW w/ R. Krishna, D. Fox

Bespoke Labs @bespokelabsai
2K Followers 104 Following RL Environment Curation for the Agentic Future. Data Curation: https://t.co/EnYs1QL3Hj
Composio @composiohq
11K Followers 16 Following Something connects to something, something a̶n̶y̶t̶h̶i̶n̶g̶ e̶v̶e̶r̶y̶t̶h̶i̶n̶g̶ happens https://t.co/o5a0zrTEL7
Utkarsh Mall @utkarshmall13
213 Followers 194 Following 🧑🏫 Assistant Professor of CV @MBZUAI Previously: 🔬 Postdoctoral Researcher @Columbia 🧑🎓PhD @Cornell Research Interests: Computer Vision for ScienceTrends for United States
You might like



















