
Extremely excited to announce Zamba! A 7B SSM with a novel architecture competitive with Gemma-7B and Mistral-7B and significantly beating Llama2-7B trained on only 1T open training tokens.

Extremely excited to announce Zamba! A 7B SSM with a novel architecture competitive with Gemma-7B and Mistral-7B and significantly beating Llama2-7B trained on only 1T open training tokens.
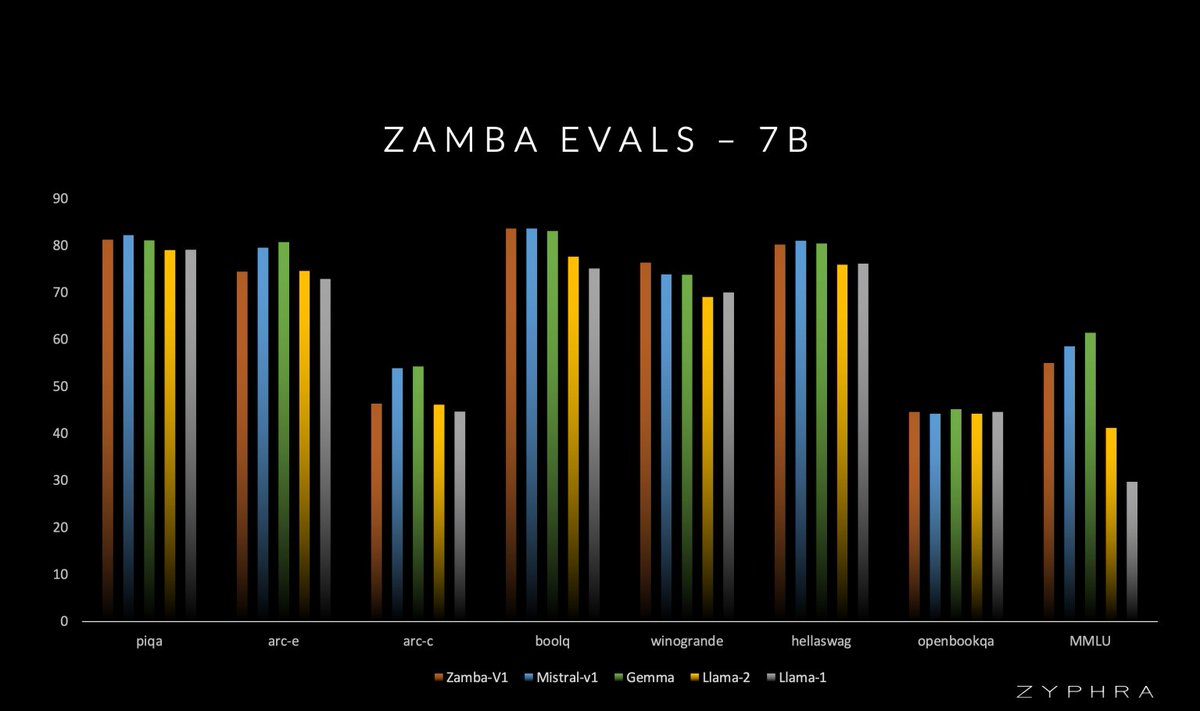
While MoEs trade greater memory cost for reduced FLOPs, GPU memory is the key constraint for many to run models locally. With Zamba, we experimented with going in the other direction -- sharing global attention parameters to boost performance at the same parameter count.


@BerenMillidge Thank you for working in the open, Beren!
