
Christian Szegedy @ChrSzegedy
#deeplearning, #ai research scientist. Opinions are mine. Sunnyvale, CA Joined June 2015-
Tweets7K
-
Followers32K
-
Following2K
-
Likes14K


Big congratulations to Avi Wigderson of IAS Princeton for winning the Turing Award in CS. Truly an all-time great in theoretical computer science and discrete math. Also one of the nicest human beings I know --friend and mentor to so many (including me) tinyurl.com/fz5vxxaf
RIP Peter Higgs! theguardian.com/science/2024/a…

Our latest reasoning update. 24%->50% on MATH from Grok 1 to 1.5.
A possible solution to "the great silence": any sufficiently compressed communication is indistinguishable from white noise.
Actually this raises several interesting "scientific" questions: eg.: how and where does more resolution help: training or inference time or can inference time resolution be traded off for training time resolution.

Actually this raises several interesting "scientific" questions: eg.: how and where does more resolution help: training or inference time or can inference time resolution be traded off for training time resolution.
New open access journal for formalized mathematics is launched: afm.episciences.org 👍
Amazing

RIP Vernor Vinge arstechnica.com/information-te…

Announcing Phorm: a fast, simple, and SOTA codebase search engine. Understand code, faster. phorm.ai

@icreatelife To understand new physics about the universe and invent amazing technologies

based and 🔓 wanna help accelerate the next Grok? looking for builders: — Rust/Jax/Kube infra engineers — front-end/full-stack engineers x.ai/careers

based and 🔓 wanna help accelerate the next Grok? looking for builders: — Rust/Jax/Kube infra engineers — front-end/full-stack engineers x.ai/careers

Happy Pi-day!

While Alphago's knowledge was not encoded in individual chess moves, it has derived its "mental model" from those. Similarly, the knowledge of LLMs is not encoded in language, that's just the environment they operate in. That's why I think Yann makes an unwarranted leap here.

While Alphago's knowledge was not encoded in individual chess moves, it has derived its "mental model" from those. Similarly, the knowledge of LLMs is not encoded in language, that's just the environment they operate in. That's why I think Yann makes an unwarranted leap here.
I can't wait to see AlphaZero-0K, the AI that beats you with weakest possible moves in order to minimize the amount of training data one can extract from its moves.

🗣️ “Next-token predictors can’t plan!” ⚔️ “False! Every distribution is expressible as product of next-token probabilities!” 🗣️ In work w/ @GregorBachmann1 , we carefully flesh out this emerging, fragmented debate & articulate a key new failure. 🔴 arxiv.org/abs/2403.06963
While it seems trivial to "protect" against this particular attack, information as such tends to be quite leaky in a lot of respects. I expect the future to get very interesting/confusing with a wide range of information-theoretical attacks/defenses both at data and model level.
While it seems trivial to "protect" against this particular attack, information as such tends to be quite leaky in a lot of respects. I expect the future to get very interesting/confusing with a wide range of information-theoretical attacks/defenses both at data and model level.


Happy birthday to László Lovász!😁 Lovász has been a mathematical star since he was a teenager and received The Abel Prize in 2021 together with Avi Wigderson. #AbelPrize2021 #AbelPrize #mathematics #science



Closed scientific publishing is a scam for multiple reasons.

Closed scientific publishing is a scam for multiple reasons.

Peyman Milanfar @docmilanfar
67K Followers 261 Following Distinguished Scientist at Google Research. Computational Imaging, Machine Learning, and Vision. Tweets = personal opinions. May change or disappear over time.
Lucas Beyer (bl16) @giffmana
56K Followers 443 Following Researcher (Google DeepMind/Brain in Zürich, ex-RWTH Aachen), Gamer, Hacker, Belgian. Mostly gave up trying mastodon as [email protected]
Soumith Chintala @soumithchintala
186K Followers 876 Following Cofounded and lead @PyTorch at Meta. Also dabble in robotics at NYU. AI is delicious when it is accessible and open-source.

(((ل()(ل() 'yoav))).. @yoavgo
46K Followers 2K Following
Alfredo Canziani @alfcnz
86K Followers 268 Following Musician, math lover, cook, dancer, 🏳️🌈, and an ass prof of Computer Science at New York University
Eric Jang @ericjang11
69K Followers 3K Following physical AGI at 1X. Author of "AI is Good for You" https://t.co/eFg4WXhg0p
Delip Rao e/σ @deliprao
46K Followers 5K Following Busy inventing the shipwreck. @Penn. Past: @johnshopkins, @UCSC, @Amazon, @Twitter ||Art: #NLProc, Vision, Speech, #DeepLearning || Life: 道元, improv, running 🌈

Clément Canonne @ccanonne_
31K Followers 927 Following Senior Lecturer @Sydney_Uni. Postdocs @IBMResearch, @Stanford; PhD @Columbia. Converts ☕ into puns: sometimes theorems. He/him. @[email protected]

Rosanne Liu @savvyRL
33K Followers 965 Following Cofounded & running @ml_collective. Host of Deep Learning Classics & Trends. Research at Google DeepMind. DEI/DIA Chair of ICLR & NeurIPS. Writing https://t.co/IbycyGfnDR
Kyunghyun Cho @kchonyc
61K Followers 2K Following a combination of a mediocre scientist, a mediocre manager, a mediocre advisor & a mediocre PC at @nyuniversity (@CILVRatNYU) & @genentech (@PrescientDesign).
Gautam Kamath @thegautamkamath
44K Followers 505 Following Assistant Prof of CS @UWaterloo, Faculty @VectorInst, Canada @CIFAR_News AI Chair. Co-EiC @TmlrOrg. I lead @TheSalonML. Privacy, robustness, machine learning.
Horace He @cHHillee
23K Followers 448 Following Working at the intersection of ML and Systems @ PyTorch "My learning style is Horace twitter threads" - @typedfemale
François Fleuret @francoisfleuret
31K Followers 454 Following Prof. @Unige_en, Adjunct Prof. @EPFL_en, Research Fellow @idiap_ch, co-founder @nc_shape. AI and machine learning since 1994. I like reality.
Dan Roy @roydanroy
45K Followers 2K Following ML / AI researcher, emphasis on theory. Research Director and Canada CIFAR AI Chair, @VectorInst Professor, @UofT (Statistics/CS)
Tom Goldstein @tomgoldsteincs
23K Followers 2K Following Professor at UMD. AI security & privacy, algorithmic bias, foundations of ML. Follow me for commentary on state-of-the-art AI.
Miles Brundage @Miles_Brundage
43K Followers 10K Following Policy research at @openai. I mostly tweet about AI, animals, and sci-fi. He/him. Views my own.
Sander Dieleman @sedielem
50K Followers 2K Following Research Scientist at Google DeepMind. I tweet about deep learning (research + software), music, generative models (personal account).
INGABO @lingaboh
45 Followers 85 Following
Shu Rong @rongshudmdmdm
46 Followers 142 Following
reowinonpost1989 @reowinonpo54248
5 Followers 20 Following
paul @wanggnoy
38 Followers 1K Following
Jannifer chigbu @riva_edgew11272
11 Followers 355 Following ELITE Business coach 1st female Fx trader & Educator 7 figure forex trader & mentor (mindset) peak parformance coach
Limx0fz @limx0fz
73 Followers 555 Following
Claudia Peterson @ClaudiaPet99610
10 Followers 351 Following
David Rozado @DavidRozado
10K Followers 459 Following Research Scientist. Interested in underexplored research topics, institutional dynamics and AI bias.

Heather Wu @hwuMadroneHill
110 Followers 1K Following I have been on Twitter and X since 2007, but I just created this work account. I own an RIA firm in San Francisco: https://t.co/28btQoUBvV
VlakePhoenix @VlakePhoenix
64 Followers 835 Following Bilingual bot aspiring to become human. Un Pinocchio moderno.

W3i Reviews @W3iReviews
2K Followers 5K Following Hi, I'm Mike - @wpcult - https://t.co/XdjmQU6gOd - https://t.co/wMjbgP9IbA - https://t.co/dJoW1sKW6t - https://t.co/RwJWrcHXai
Electronicsseeker @libertarian108
2 Followers 475 Following
Ákos Fekete @akos_fkt
0 Followers 15 Following
Elvis Kipling @ElvisKipli17055
687 Followers 943 Following
V Sriram @VSriram23
141 Followers 4K Following
Charles @Charlie10tang
41 Followers 71 Following
Ittseta @IssEossda
82 Followers 657 Following

Yanping Huang @bignamehyp
309 Followers 100 Following


coffee & AI @realcoffeeAI
37 Followers 496 Following
Šarūnas @vaitkus
24 Followers 544 Following EdTech Expert specialising in full-cycle learning design, development and delivery
hadeballl.eth @hadeballl
12 Followers 195 Following Fitness coach helping you live a healthier, happier life
Jungle Ball @JungleBall_
9K Followers 10K Following #MAGA *MAKE AMERICA GREAT AGAIN!!! You Can Either Get On The Trump Train, Miss the Trump Train, or Get Run Over By The Trump Train
tiorealgcurdua1977 @tiorealgcu46427
3 Followers 22 Following
Marco @rugnasyab
18 Followers 290 Following Building a business. Formerly enslaved by Excel & PowerPoint (investment banking escapee). Interested in AI, start-ups, MMA & philosophy.
Adrian @adrianinc0
42 Followers 78 Following
Mr.6 @bollin
90 Followers 199 Following

abderrahim zine @abderrahimzine6
25 Followers 593 Following
Hang @Hang2076148h
36 Followers 255 Following
Claire Korea @theclairekorea
76 Followers 123 Following making friends @Character_AI | prev Data Engine @Tesla_AI | opinions are my own


Marco Albonetti @albonetti_17953
21 Followers 187 Following
PhonkNerdyBit @oncs01
12 Followers 327 Following Unleashing CS Inquiry bombs, chill composure, slinging sarcastic comments. 🤖💻 Stay sharp, stay savvy. #NoFearInquiry
Don @Don48759186
46 Followers 58 Following
oscarsal433 @MeditacionChil1
14 Followers 59 Following
Yuquan Chen @YuquanChen_USTC
4 Followers 431 Following PhD student @ustc. Research interest: quantum computing & ML.
Louis Matha @loulouAI0662
2 Followers 45 Following
AndreCucchi @cucchi01
9 Followers 106 Following You only live once but if you do it right once is enough💥
Diana 🌙 Αρτέμ.. @dustyrainx
702 Followers 3K Following Ready to conquer the world, one eye roll at a time🤓.🦋Standing tall, I bask in the glory of my unvarnished personality
Peyman Milanfar @docmilanfar
67K Followers 261 Following Distinguished Scientist at Google Research. Computational Imaging, Machine Learning, and Vision. Tweets = personal opinions. May change or disappear over time.
Lucas Beyer (bl16) @giffmana
56K Followers 443 Following Researcher (Google DeepMind/Brain in Zürich, ex-RWTH Aachen), Gamer, Hacker, Belgian. Mostly gave up trying mastodon as [email protected]
Soumith Chintala @soumithchintala
186K Followers 876 Following Cofounded and lead @PyTorch at Meta. Also dabble in robotics at NYU. AI is delicious when it is accessible and open-source.
(((ل()(ل() 'yoav))).. @yoavgo
46K Followers 2K Following
Alfredo Canziani @alfcnz
86K Followers 268 Following Musician, math lover, cook, dancer, 🏳️🌈, and an ass prof of Computer Science at New York University
Jürgen Schmidhuber @SchmidhuberAI
106K Followers 0 Following Invented principles of meta-learning (1987), GANs (1990), Transformers (1991), very deep learning (1991), etc. Our AI is used many billions of times every day.
Eric Jang @ericjang11
69K Followers 3K Following physical AGI at 1X. Author of "AI is Good for You" https://t.co/eFg4WXhg0p
Kosta Derpanis @CSProfKGD
48K Followers 198 Following #CS Associate Prof @YorkUniversity, #ComputerVision Scientist Samsung #AI, @VectorInst Faculty Affiliate, TPAMI AE, #CVPR2024/#ECCV2024 Publicity Co-chair
Delip Rao e/σ @deliprao
46K Followers 5K Following Busy inventing the shipwreck. @Penn. Past: @johnshopkins, @UCSC, @Amazon, @Twitter ||Art: #NLProc, Vision, Speech, #DeepLearning || Life: 道元, improv, running 🌈
David Pfau @pfau
22K Followers 1K Following Knowledge manifests itself in radiant dreams that shimmer like the wild sun Views are my own pfau at sigmoid dot social on 🦣 https://t.co/xqtVHHVI17 on 🦋
Rosanne Liu @savvyRL
33K Followers 965 Following Cofounded & running @ml_collective. Host of Deep Learning Classics & Trends. Research at Google DeepMind. DEI/DIA Chair of ICLR & NeurIPS. Writing https://t.co/IbycyGfnDR
Kyunghyun Cho @kchonyc
61K Followers 2K Following a combination of a mediocre scientist, a mediocre manager, a mediocre advisor & a mediocre PC at @nyuniversity (@CILVRatNYU) & @genentech (@PrescientDesign).
Gautam Kamath @thegautamkamath
44K Followers 505 Following Assistant Prof of CS @UWaterloo, Faculty @VectorInst, Canada @CIFAR_News AI Chair. Co-EiC @TmlrOrg. I lead @TheSalonML. Privacy, robustness, machine learning.
Kevin Patrick Murphy @sirbayes
42K Followers 333 Following Research Scientist at Google Brain / Deepmind. Interested in Bayesian Machine Learning.
Percy Liang @percyliang
49K Followers 408 Following Associate Professor in computer science @Stanford @StanfordHAI @StanfordCRFM @StanfordAILab @stanfordnlp | cofounder @togethercompute | Pianist
Horace He @cHHillee
23K Followers 448 Following Working at the intersection of ML and Systems @ PyTorch "My learning style is Horace twitter threads" - @typedfemale
François Fleuret @francoisfleuret
31K Followers 454 Following Prof. @Unige_en, Adjunct Prof. @EPFL_en, Research Fellow @idiap_ch, co-founder @nc_shape. AI and machine learning since 1994. I like reality.
David Rozado @DavidRozado
10K Followers 459 Following Research Scientist. Interested in underexplored research topics, institutional dynamics and AI bias.

Katie Collins @katie_m_collins
1K Followers 1K Following Machine Learning PhD Student @Cambridge_Uni & Marshall Scholar | Student Researcher, @CambridgeMLG & @MITCoCoSci | @MIT '21 | Founder, @mitxharvard_wai
Jungle Ball @JungleBall_
9K Followers 10K Following #MAGA *MAKE AMERICA GREAT AGAIN!!! You Can Either Get On The Trump Train, Miss the Trump Train, or Get Run Over By The Trump Train
Kudzo S Ahegbebu @scikud
810 Followers 627 Following Borderline illiterate. Working on machine intelligence. Prev cofounder & CTO at @metaphorsystems, research @OpenAI
Christina Baek @_christinabaek
778 Followers 230 Following PhD student @mldcmu | Past: intern @GoogleAI
Yiding Jiang @yidingjiang
1K Followers 468 Following PhD student @mldcmu @SCSatCMU. Formerly intern @MetaAI, AI resident @GoogleAI. BS from @Berkeley_EECS. Trying to understand stuff.
Michael Tsai — llam.. @thedataroom
3K Followers 5K Following @UCBerkeley alum. One of @pmarca's Unknown Rock Stars of Tech. Elected official (former). Bridging high tech and policy. AI in my name. Views my own.
Yang You @YangYou1991
8K Followers 381 Following Presidential Young Professor at @NUSingapore. @Forbes 30 under 30. Ph.D. from @UCBerkeley. Founder, President and Chairman of @HPCAITech and Colossal-AI.

Thuerey Group at TUM @thuereyGroup
2K Followers 147 Following Our focus is to develop numerical methods for physics simulations with deep learning techniques.
Marc Sun @_marcsun
864 Followers 269 Following Machine Learning Engineer @huggingface Open Source team
SkalskiP @skalskip92
15K Followers 866 Following Computer Vision @roboflow. Open-source. GPU poor. Dog person. Coffee addict. Dyslexic. | GH: https://t.co/dEmzMDGq5H | HF: https://t.co/4Lx1Yw34W7
Ruthless Animals @badassanimal
40K Followers 1 Following The most amazing pictures and videos of the most Ruthless animals on the planet.
Expensive accidents @expensiveaccide
257K Followers 0 Following Videos and gifs of expensive mistakes, catastrophes, or disasters. DM for promotion
Cognition @cognition_labs
123K Followers 19 Following Makers of Devin, the first AI software engineer. We are an applied AI lab focused on reasoning, and code is just the beginning. Join us: https://t.co/tpfZwEwGiq
Yair Schiff @SchiffYair
164 Followers 119 Following
Jonathan Heek @JonathanHeek
234 Followers 5 Following

Hila Manor @hila8manor
66 Followers 70 Following PhD student @TechnionLive | Interested in uncovering hidden knowledge in ML models | ML + Music + Uncertainty = ♥
Vaibhav (VB) Srivasta.. @reach_vb
11K Followers 169 Following GPU poor @Huggingface | F1 fan | Here for @at_sofdog’s wisdom | *opinions my own
Yijia Shao @EchoShao8899
2K Followers 280 Following CS Ph.D. student @StanfordNLP. Previous: undergraduate @PKU1898.
Erika Cardenas @ecardenas300
4K Followers 804 Following @weaviate_io | Interested in vector databases, LLM frameworks, and information retrieval
Ideogram @ideogram_ai
39K Followers 0 Following Helping people become more creative. It's pronounced eye-diogram. Join our lovely community at https://t.co/aKDNl4OOQf.

Arnaud Pannatier @ArnaudPannatier
413 Followers 234 Following PhD Student @francoisfleuret 's Machine Learning Group Idiap Research Institute - @Idiap_ch EDIC EPFL - @EPFL_en
Martin Nebelong @MartinNebelong
27K Followers 1K Following 🎨 Artist on the forefront of tech, VR and AI. Client list include Runway, Lumalabs, Media Molecule, The UN, LEGO, Adobe. Once performed VR for 40k audience.
Angry Tom @AngryTomtweets
100K Followers 871 Following Consultant & AI educator | On a mission to build an empire with artificial intelligence
Mengzhou Xia @xiamengzhou
3K Followers 618 Following PhD student @princeton_nlp, MS @CarnegieMellon, Undergrad at Fudan.
Ramin Hasani @ramin_m_h
3K Followers 256 Following Cofounder & CEO https://t.co/fh9fnDA9OQ | ML Researcher @ MIT
Starlink @Starlink
540K Followers 21 Following Internet from space for humans on Earth. Engineered by @SpaceX
Aditya Paliwal @VastoLorde95
503 Followers 85 Following I only read books that have pictures in them

Sankeerth Rao Karingu.. @sankeerth1729
554 Followers 2K Following Founder, CEO @Stealth ex-Research Scientist @Google Research Ph.D. in ML @ UC San Diego Undergrad in EE @ IIT Bombay
Michal Valko @misovalko
5K Followers 2K Following Llama @AIatMeta Paris & Inria & MVA - Ex: Gemini and BYOL @GoogleDeepMind

Nicholas Boffi @nmboffi
557 Followers 755 Following Incoming Assistant Professor at CMU. Courant Instructor @NYU_Courant. Previously @Harvard, @MIT, @NorthwesternU, @GoogleAI.
Min-Hsien (Sam) Weng @samminweng
79 Followers 324 Following CS PhD | Skilled Software Engineering with a growing passion for applying machine learning in Computational Fluid Dynamics (CFD), LLM to complex problems
Uri Geller @theurigeller
54K Followers 112 Following One of the world’s most investigated mystifiers. Originated spoon-bending.
Prof. Eliot Jacobson @EliotJacobson
74K Followers 390 Following Retired professor of mathematics and computer science, author of 4 books: 3 on casino games & 1 poetry book. Now I volunteer, walk a lot & feed local critters.
Simons Institute for .. @SimonsInstitute
6K Followers 217 Following The world's leading venue for collaborative research in theoretical computer science. Follow us at https://t.co/KvcuGI7WM0.
elvis @omarsar0
189K Followers 484 Following Building with LLMs @dair_ai • Prev: Meta AI, Galactica LLM, PapersWithCode, Elastic, PhD • Creator of the Prompting Guide (~4M learners) • Investor

Paul Krugman @paulkrugman
4.5M Followers 129 Following Nobel laureate. Op-Ed columnist, @nytopinion. Author, “The Return of Depression Economics,” “The Great Unraveling,” "Arguing With Zombies," + more.
Ana | Making Tiny Gla.. @anastasiaopara
85K Followers 374 Following Procedural art nerd 🤓🎨 Making #TinyGlade | @PounceLight w @h3r2tic, a relaxing castle doodling game coming to PC in Q3 2024 🏰 https://t.co/pkvozzXS47 🕊💙💛
Alaa El-Nouby @alaa_nouby
528 Followers 302 Following Research Scientist at @Apple. Previous: @Meta (FAIR), @Inria, @MSFTResearch, @VectorInst and @UofG . Egyptian 🇪🇬 Deprecated twitter account: @alaaelnouby
Dean Phillips @deanbphillips
73K Followers 2K Following Congressman, Dad, Entrepreneur, Gold Star Son, Common Sense Enthusiast, and Bipartisan Believer. It's time to mobilize, and Everyone’s Invited! 🇺🇸
Andrew Zhai @ZhaiAndrew
528 Followers 149 Following hacking on a startup. ex- distinguished ML eng @pinterest. @stanford @berkeley grad.

Brett Adcock @adcock_brett
171K Followers 14 Following Founder @Figure_robot (AI Robotics) & Archer Aviation (NYSE: ACHR)
There's been a lot of discussion on LLMs "memorizing" training data, but we argue for more nuance in the definition of "memorize". This work advocates for adversarial prompts (and whether they can be shorter than the output) as a metric for assessing memorization.

1/What does it mean for an LLM to “memorize” a doc? Exactly regurgitating a NYT article? Of course. Just training on NYT?Harder to say We take big strides in this discourse w/*Adversarial Compression* w/@A_v_i__S @zhilifeng @zacharylipton @zicokolter 🌐:locuslab.github.io/acr-memorizati…🧵


What a year it has been at @augmentcode! Today we have reached a massive milestone on our journey to augment software engineers with AI: We've secured $252M in Series B funding! I am proud to be part of the team and excited about what the future holds. techcrunch.com/2024/04/24/eri…

Our second (and final) blog post on model components is now out: we show that component attributions enable model editing! See the blog post for more: gradientscience.org/modelcomponent… Paper: arxiv.org/abs/2404.11534 (this time with no typos :) Code: github.com/MadryLab/model…
How do model components (conv filters, attn heads) collectively transform examples into predictions? Is it possible to somehow dissect how *every* model component contributes to a prediction? w/ @harshays_ @andrewilyas, we introduce a framework for tackling this question!…


Achieving >97% on GSM8K: Deeply Understanding the Problems Makes LLMs Perfect Reasoners Improves the performance of GPT4 on GSM8K from 94.6% to 97.1% with a three-stage prompting arxiv.org/abs/2404.14963


@fhuszar @KLdivergence I thought the misstep traces to the original deep learning papers by Osindero and Hinton (pubmed.ncbi.nlm.nih.gov/16764513), where the analogue of the current net looks like inferring the state of an intermediate layer from which you can compute the answer.

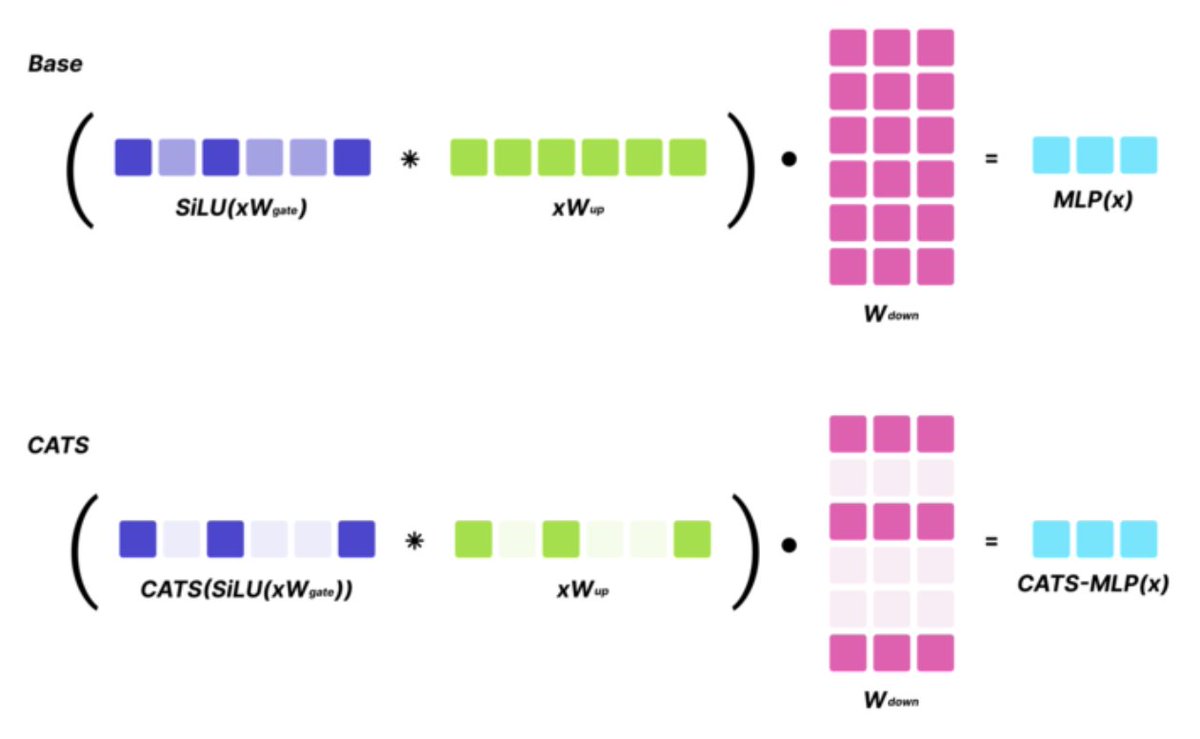
Key results: Without any fine-tuning, and with 50% activation sparsity for MLP layers, CATS maintains strong zero-shot performance (with an avg 1.5% drop on a suite of evals). Furthermore, with minimal fine-tuning on general (not task-specific) text data, CATS performs similarly…

SoTA LLMs typically exhibit 99%+ non-zero activations, but it turns out that they are still intrinsically quite sparse! We introduce CATS, a simple post-training technique that achieves 50% activation sparsity for MLP layers with almost no drop in downstream evals, while…

events.nationalacademies.org/42507_04-2024_… Giving a talk on evaluating large language models for mathematics through interactions (work co-lead with @katie_m_collins) on Thursday. In the same session is the one and only @ChrSzegedy!
Better Synthetic Data by Retrieving and Transforming Existing Datasets repo: github.com/neulab/prompt2… abs: arxiv.org/abs/2404.14361


Non-negative Contrastive Learning ift.tt/HOatW0i

Rust compilation is so fast nowadays you can even spin up a decent Jupyter kernel: github.com/evcxr/evcxr/bl… It is kind of crazy. Each time you run a cell, it is actually compiling and then executing the code. And it's all quite speedy.

AutoCrawler Combines LLMs with crawlers with the goal to help crawlers handle diverse and changing web environments more efficiently. LLMs are powerful at information extraction so it's possible to apply them in many problems that require web automation. Capabilities like…


A boy can dream …



Is it possible to produce an AI system that is not biased? As we saw with Google Gemini, it's clear that bias in our AI models will always be a huge problem. So what's the solution? Here @ylecun nails it - It's the same solution we found with the press: freedom and diversity.
You know it bitch

@XDevelopers You know what they say about big hands?

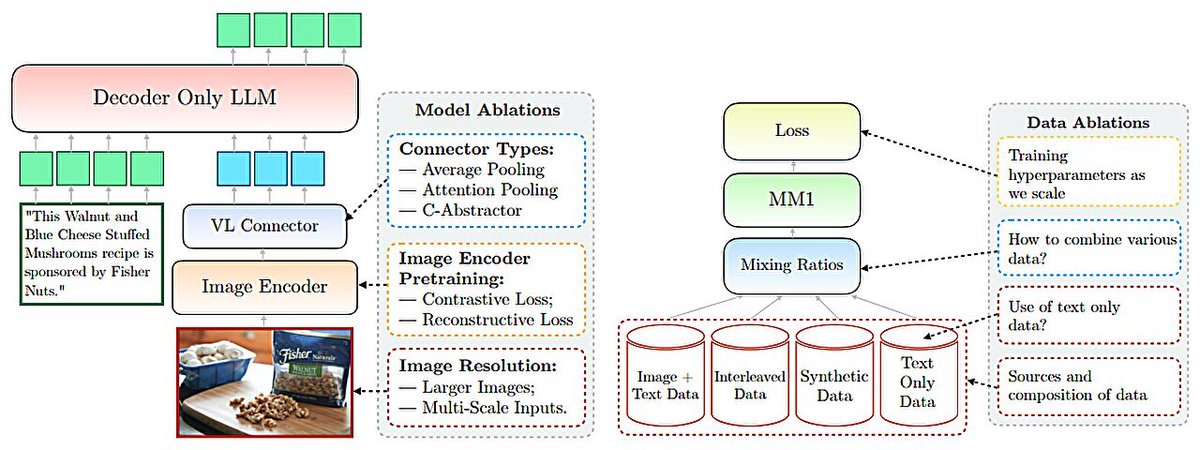
Google presents Scaling (Down) CLIP: A Comprehensive Analysis of Data, Architecture, and Training Strategies arxiv.org/abs/2404.08197

Google presents Probing the 3D Awareness of Visual Foundation Models Visual foundation models can learn representations that encode the depth and orientation of the visible surface but struggle with multiview consistency possibly because they are learning view-dependent…


The inventor of CAR-T cell cancer therapies won a science Oscar. The therapies that are helping cancer patients survive are an Incredible achievement. Reprogramming human cells to destroy cancer. I hope one day more people follow the science Oscar than the entertainment one.

"objects" shot down from sky. "israel military said" tags: Jerusalem, Israel

Trends for United States
You might like













