
Dominic @Dominicliu12
Joined October 2022-
Tweets30
-
Followers6
-
Following94
-
Likes34
Phi-3 template supported in #LMFlow, waiting for the base model 👀 Try further tuning Phi-3-instruct in LMFlow with SFT/#LISA/#LoRA via 👇


#Llama3: Llama-3-8B fine-tuning in single GPU with LISA 😄 (3090 suffices) Powered by #LMFlow🌟 - github.com/OptimalScale/L…

#Llama3: Llama-3-8B fine-tuning in single GPU with LISA 😄 (3090 suffices) Powered by #LMFlow🌟 - github.com/OptimalScale/L…

LISA is now supported in LMFlow🚀 Check out our latest script for tuning 7B LLMs with LISA in one line🌟. Any feedback is highly appreciated 😄 github.com/OptimalScale/L…
LISA is now supported in LMFlow🚀 Check out our latest script for tuning 7B LLMs with LISA in one line🌟. Any feedback is highly appreciated 😄 github.com/OptimalScale/L…


Check out our recent efforts on memory-efficient fine-tuning of LLMs! We investigate the layerwise properties of LoRA on fine-tuning tasks and propose Layerwise Importance Sampled AdamW (𝑳𝑰𝑺𝑨), a promising alternative for LoRA. HuggingFace paper: huggingface.co/papers/2403.17…
Check out our recent efforts on memory-efficient fine-tuning of LLMs! We investigate the layerwise properties of LoRA on fine-tuning tasks and propose Layerwise Importance Sampled AdamW (𝑳𝑰𝑺𝑨), a promising alternative for LoRA. HuggingFace paper: huggingface.co/papers/2403.17…
Excited to share LISA, which enables - 7B tuning on a 24GB GPU - 70B tuning on 4x80GB GPUs and obtains better performance than LoRA in ~50% less time 🚀
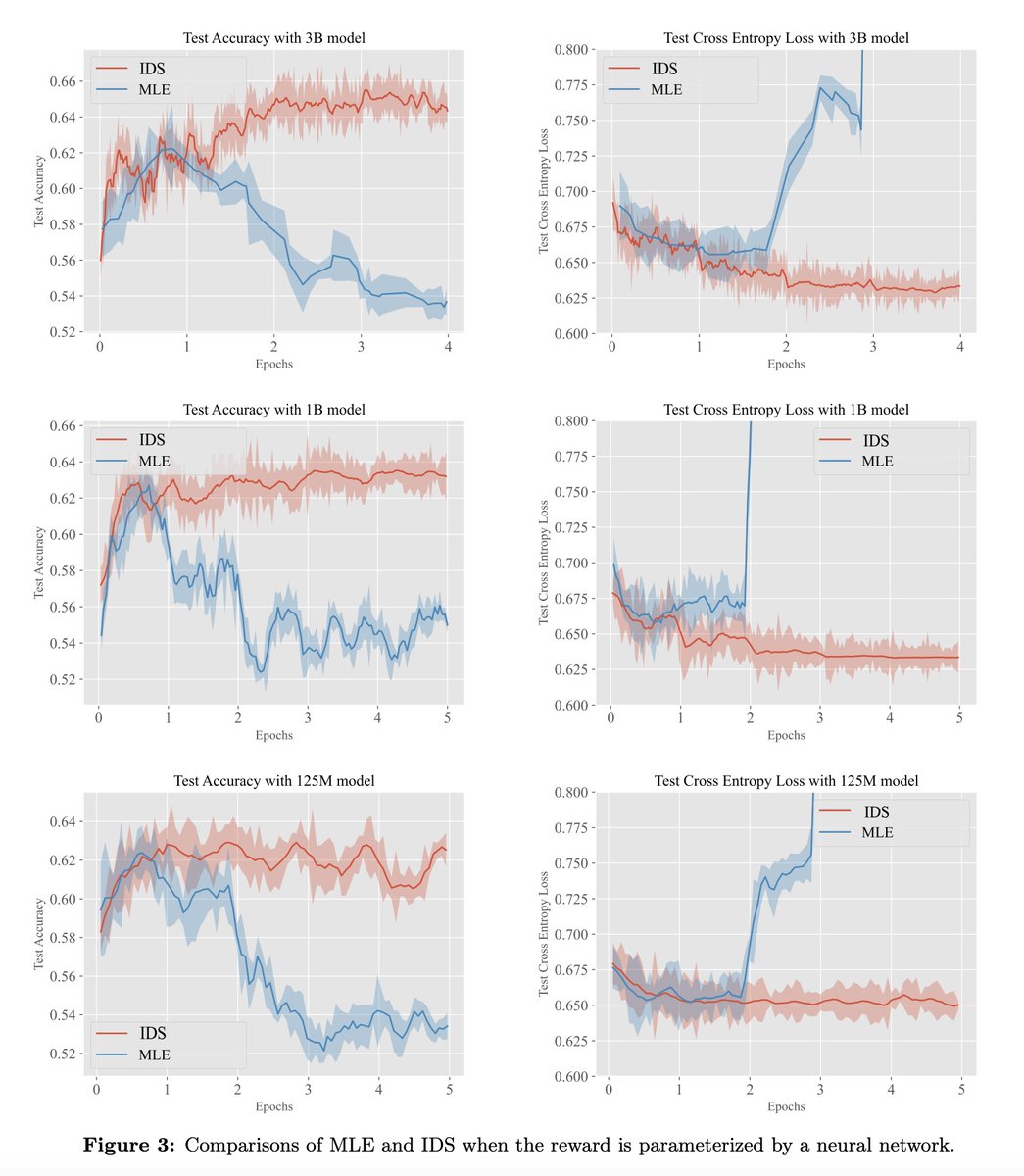
[LG] Iterative Data Smoothing: Mitigating Reward Overfitting and Overoptimization in RLHF B Zhu, M I. Jordan, J Jiao [UC Berkeley] (2024) arxiv.org/abs/2401.16335 - The paper investigates issues of reward overfitting and overoptimization in reinforcement learning from human…




(1/5)🚀 Our OpenMoE Paper is out! 📄 Including: 🔍ALL Checkpoints 📊 In-depth MoE routing analysis 🤯Learning from mistakes & solutions Three important findings: (1) Context-Independent Specialization; (2) Early Routing Learning; (3) Drop-towards-the-End. Paper Link:…


Corrective RAG Proposes Corrective Retrieval Augmented Generation (CRAG) to improve the robustness of generation in a RAG system. The core idea of this paper is to implement a self-correct component for the retriever and improve the utilization of retrieved documents for…

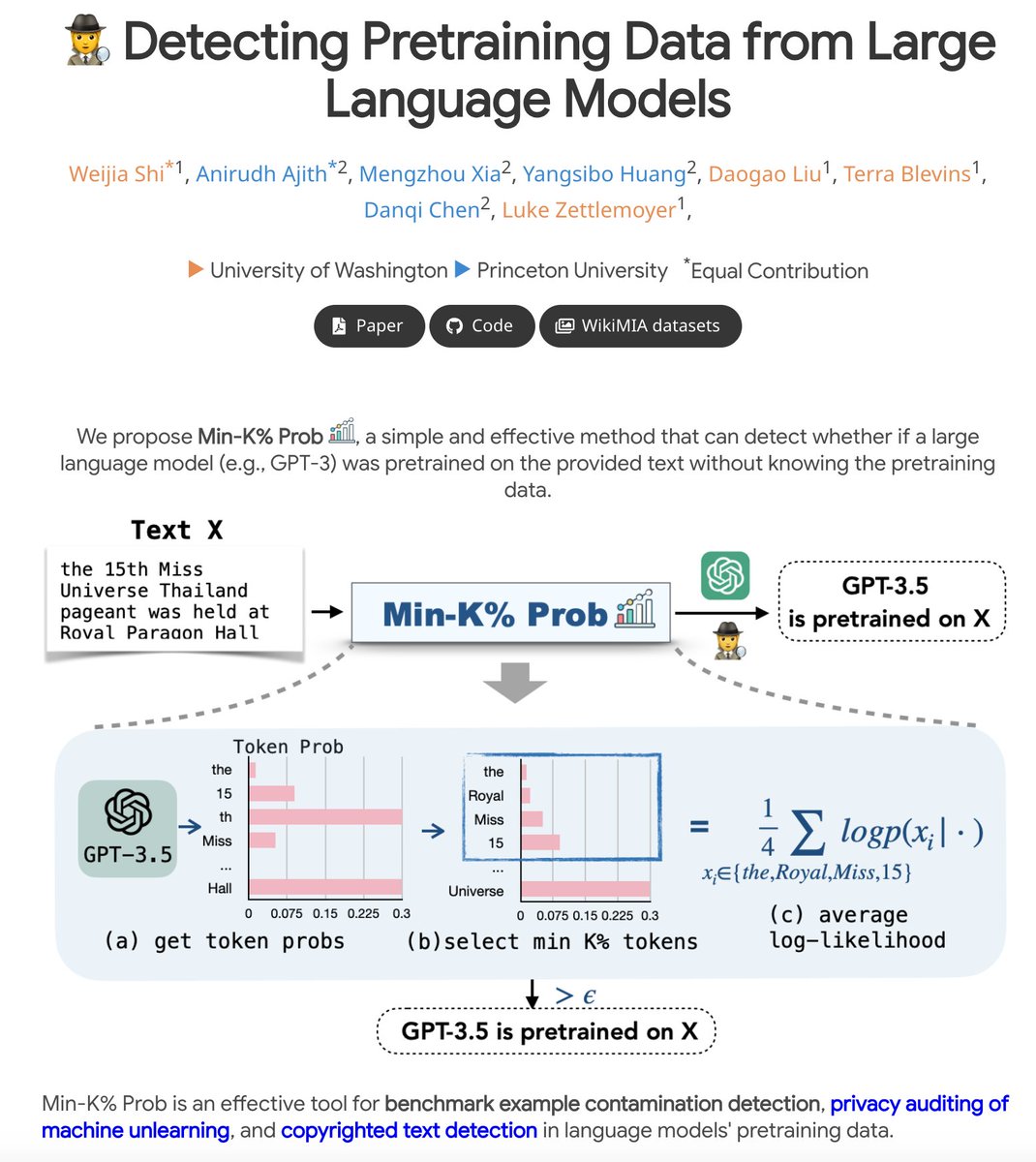
Ever wondered which data black-box LLMs like GPT are pretrained on? 🤔 We build a benchmark WikiMIA and develop Min-K% Prob 🕵️, a method for detecting undisclosed pretraining data from LLMs (relying solely on output probs). Check out our project: swj0419.github.io/detect-pretrai… [1/n]

Honored to have played a small role in Med-PaLM, now published in Nature! nature.com/articles/s4158… My grandpa is 89, and every year he asks if I've published in Science or Nature (he knows I'm a researcher, but he only knows those two journals). This year I can finally say yes!

Unlimited clean data. This is the meaning of this paper: Filpped-Learning TL;DR: Generating the instructions based on Inputs&Outputs. Paper: arxiv.org/abs/2210.02969 Code: github.com/seonghyeonye/F… Model (11B): huggingface.co/seonghyeonye/f… Model (3B): huggingface.co/seonghyeonye/f… --- Why…


Unlimited clean data. This is the meaning of this paper: Filpped-Learning TL;DR: Generating the instructions based on Inputs&Outputs. Paper: arxiv.org/abs/2210.02969 Code: github.com/seonghyeonye/F… Model (11B): huggingface.co/seonghyeonye/f… Model (3B): huggingface.co/seonghyeonye/f… --- Why… https://t.co/A5eGTwhLMc
Make every ugly text data "LLM Learnable" Summary: Text Augmentations All major models using them. Enjoy! Intro: You got some text that has valuable info in it. But it looks like.. dunno.. not good. The document just doesn't look like something you wanted the model to return…


Parameter-efficient fine-tuning revolutionized the accessibility of LLM fine-tuning, but can they also revolutionize pre-training? We present ReLoRA — the first PEFT method that can be used for training from scratch! 🔥🔥 arxiv.org/abs/2307.05695


@bernaaaljg Interesting! In our ACL'23 paper (arxiv.org/pdf/2305.17378…) we found tokenization an important issue for semantic parsing as well. Fixing it with simple tricks can give 5-10% improvement in domain and compositional generalization of text2SQL.

Interesting stuff to come: @kaggle will host the first Machine Unlearning Challenge starting mid-July which is part of @NeurIPSConf. Task is to teach the model to forget a certain set. ai.googleblog.com/2023/06/announ…

Mathematics is the art of giving the same name to different things(Henri Poincaré). Machine learning is the art of giving different names to the same thing.


🥳 The LMFlow paper (arxiv.org/abs/2306.12420) has officially dropped! 📚⚡️ ⏩ LMFlow is your go-to toolkit for unleashing the power of LLMs. 🌟✨ 🔎 Dive into the nitty-gritty of our mind-blowing implementation.💥🔥 💻 Let your creativity flow freely! 🌊💡 #LMFlow #LLM #GitHub

Top ML Papers of the Week (June 19 - 25): - RoboCat - LMFlow - AudioPaLM - ClinicalGPT - SequenceMatch - Textbooks Are All You Need ...
LMFlow: an extensible and lightweight toolkit that simplifies finetuning and inference of general large foundation models. Also supports continuous pretraining, instruction tuning, parameter-efficient finetuning, alignment tuning, and large model inference. Looks very…


Yujin(Jenny) Tang @From_zero_hulu
186 Followers 2K Following SJTU B.Eng-CUHKSZ Data Science Msc-HKUSTGZ AI | ENTJ | Spatial-temporal Forecasting. She/her. Opinions are my own.

Chenxin An @AnChancy46881
117 Followers 186 Following PhD Candidate @ HKU NLP Awardee of Hong Kong PhD Fellowship Scheme (HKPFS)
Mary @marythompson81
261 Followers 3K Following


Hongli Zhan @HongliZhan
372 Followers 719 Following PhD Student 🤘@UTAustin | Incoming intern @IBMResearch | previously undergrad @sjtu1896 | NLP, emotions, affective computing
Yujin(Jenny) Tang @From_zero_hulu
186 Followers 2K Following SJTU B.Eng-CUHKSZ Data Science Msc-HKUSTGZ AI | ENTJ | Spatial-temporal Forecasting. She/her. Opinions are my own.
Linjie (Lindsey) Li @LINJIEFUN
2K Followers 296 Following researching @Microsoft, @UW, contributing to https://t.co/a3zper7NJG
Tianlong Chen @TianlongChen4
533 Followers 17 Following Incoming Asst. Professor at UNC Chapel Hill (@unccs, @unc). Postdoc, CSAIL@MIT (@MIT_CSAIL) & BMI@Harvard (@Harvard). Ph.D., ECE@UT Austin (@UTAustin). #AI #ML
Xin Eric Wang @xwang_lk
7K Followers 1K Following Multimodal and Embodied AI Researcher / Professor @UCSC. Director of https://t.co/Y4swOBag21. AI for Humanity in the long run. he/him


Geronimo @Geronimo_AI
777 Followers 390 Following LLM enthusiast 🚀 failing fast, learning fast. sharing it all on X and Medium
Wing Lian (caseus) @winglian
9K Followers 2K Following @axolotl_ai OSS maintainer. Axolotl AI founder. AI/ML tinkerer. Building tools for everyone.
Conference on Languag.. @COLM_conf
2K Followers 6 Following https://t.co/GhGCMEoa4A Abstract submission: March 22, 2024
Song Han @songhan_mit
6K Followers 144 Following Assoc. Prof. @MIT, Distinguished Scientist @NVIDIA, cofounder of DeePhi (now part of AMD) and OmniML (now part of NVIDIA). PhD @Stanford. Efficient AI computing
Rui @Rui45898440
173 Followers 456 Following @OptimalScale maintainer. Interested in Optimization, Acceleration, LLM
Chi Han @Glaciohound
219 Followers 230 Following CS PhD student at UIUC, interested in language models and their understanding.
Tengyu Ma @tengyuma
26K Followers 512 Following Assistant professor at Stanford; Co-founder of Voyage AI (https://t.co/wpIITHLgF0) ; Working on ML, DL, RL, LLMs, and their theory.
Junyang Lin @JustinLin610
5K Followers 1K Following Chief Evangelist Officer of Qwen Team & OpenDevin, building LLM and LMM. Now @Alibaba_Qwen . Previously @PKU1898 LANCO group. ❤️ 🍵 ☕️ 🍷 🥃
Tri Dao @tri_dao
19K Followers 365 Following Incoming Asst. Prof @PrincetonCS, Chief Scientist @togethercompute. Machine learning & systems.



Chenxin An @AnChancy46881
117 Followers 186 Following PhD Candidate @ HKU NLP Awardee of Hong Kong PhD Fellowship Scheme (HKPFS)
Tianyu Gao @gaotianyu1350
3K Followers 687 Following CS PhD student @Princeton @Princeton_nlp working on NLP. Previously: @Tsinghua_Uni @TsinghuaNLP
HKUST Guangzhou @HKUSTGuangzhou
55 Followers 2 Following

Yuandong Tian @tydsh
16K Followers 806 Following Research Scientist and Senior Manager in Meta AI (FAIR). AI-guided Optimization and Representation Learning. Novelist in spare time. PhD in @CMU_Robotics.
Weijia Shi @WeijiaShi2
5K Followers 968 Following PhD student @uwcse @uwnlp | Visiting Researcher @MetaAI | Undergrad @CS_UCLA | https://t.co/eLBQmgkvym
Zhijing Jin @ZhijingJin
3K Followers 1K Following Final-year PhD @MPI_IS & @ETH_en w/ @bschoelkopf. Research on (1) @CausalNLP and (2) NLP4SocialGood @NLP4SG. Mentor and mentee @ACLMentorship.
lmsys.org @lmsysorg
37K Followers 172 Following Large Model Systems Organization. We created Vicuna and Chatbot Arena! Compare 30+ LLMs (GPT-4/Claude/Llamas) side-by-side at https://t.co/IDFeIDIOtm
fly51fly @fly51fly
5K Followers 2K Following BUPT prof | Sharing latest AI papers & insights | Join me in embracing the AI revolution! #MachineLearning #AI #Innovation

OpenBMB @OpenBMB
660 Followers 101 Following OpenBMB (Open Lab for Big Model Base), founded by @TsinghuaNLP & ModelBest Inc (面壁智能), aims to build foundation models and systems towards AGI.

UIUC NLP @uiuc_nlp
808 Followers 130 Following Natural Language Processing research group at The University of Illinois Urbana-Champaign @IllinoisCS @UofIllinois


🌴Muhao Chen🌴 @muhao_chen
2K Followers 552 Following 🐹Assistant Professor of Computer Science @UCDavis🐹 | 💙PhD @UCLAComSci 2019💛 | 🌴加州boy🌴 | 🎸@GALNERYUSOFFIC2#1🎧! |♛Collecting⌚♛
Wenpeng_Yin @Wenpeng_Yin
1K Followers 3K Following Assistant Professor at Penn State, State College Department of Computer Science and Engineering
JFPuget 🇺🇦 @JFPuget
15K Followers 1K Following Machine Learning at @Nvidia, 3x Kaggle Grandmaster CPMP. For AI/ML content read me at [email protected] Views are my own.
hyd @hydantess1993
606 Followers 482 Following
Jeff Dean (@🏡) @JeffDean
296K Followers 6K Following Chief Scientist, Google DeepMind and Google Research. Co-designer/implementor of things like @TensorFlow, MapReduce, Bigtable, Spanner, Gemini .. (he/him)

Reka @RekaAILabs
11K Followers 13 Following An AI research and product company 🫠. We are a team of scientists and engineers building state-of-the-art multimodal language models 😻

Zhiyuan Liu @zibuyu9
2K Followers 278 Following Associate Professor @TsinghuaNLP. Research interests include NLP, KG and social computation.
Chen Zhao @henryzhao4321
634 Followers 348 Following Assistant Professor NYU Shanghai, Postdoc NYU, PhD @umdclip doing NLP research, bridge player


George Mason Universi.. @GeorgeMasonU
34K Followers 970 Following The official account of George Mason University! #MasonNation 💚💛 -@MasonULife -@MasonAdmissions -@GMUPres -@MasonAlumni -@MasonAthletics
Yao Fu @Francis_YAO_
14K Followers 2K Following PhD @EdinburghNLP on LLMs and Machine Reasoning. Ex. @Columbia @PKU1898 @MITIBMLab @allen_ai AGI has yet to come, so keep running
DeepLearning.AI @DeepLearningAI
221K Followers 30 Following We are an education technology company with the mission to grow and connect the global AI community.Phi-3 template supported in #LMFlow, waiting for the base model 👀 Try further tuning Phi-3-instruct in LMFlow with SFT/#LISA/#LoRA via 👇
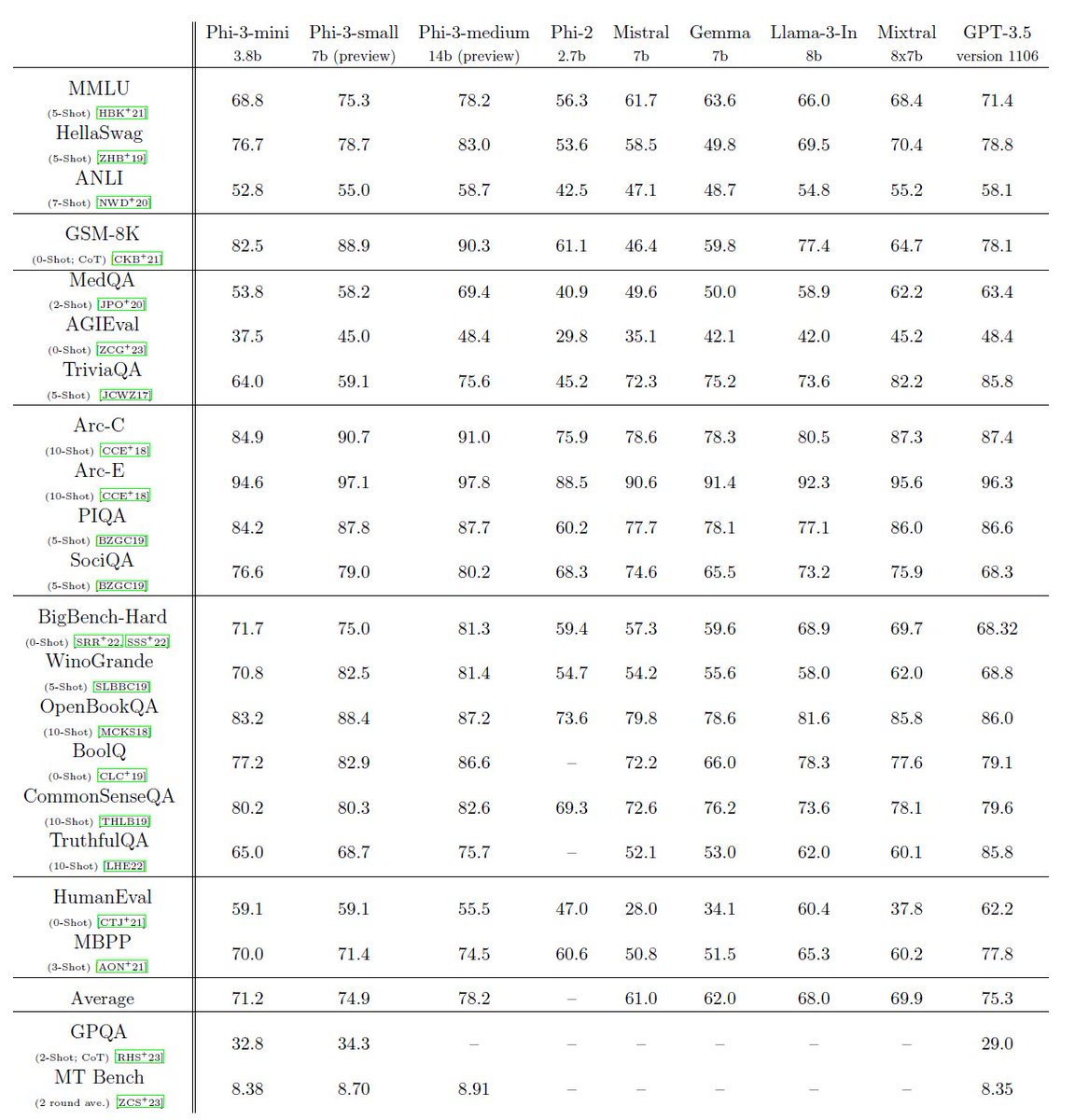
phi-3 is here, and it's ... good :-). I made a quick short demo to give you a feel of what phi-3-mini (3.8B) can do. Stay tuned for the open weights release and more announcements tomorrow morning! (And ofc this wouldn't be complete without the usual table of benchmarks!)

Happy to see that the rejection sampling finetuning (we call it RAFT, reward ranked finetuning arxiv.org/pdf/2304.06767…) also contributes to the post-fine tuning of llama3 Here DPO is short for direct POLICY optimization. Does it mean they skip RM but use some other algorithm ?


@weixiong_1 I guess they might use LLM to polish the intro and LLMs does not know DPO
LISA with 🤗Trainer notebook for llama2-7b ft: github.com/geronimi73/309…
Excited to share LISA, which enables - 7B tuning on a 24GB GPU - 70B tuning on 4x80GB GPUs and obtains better performance than LoRA in ~50% less time 🚀
LISA is now supported in LMFlow🚀 Check out our latest script for tuning 7B LLMs with LISA in one line🌟. Any feedback is highly appreciated 😄 github.com/OptimalScale/L…
Excited to share LISA, which enables - 7B tuning on a 24GB GPU - 70B tuning on 4x80GB GPUs and obtains better performance than LoRA in ~50% less time 🚀
Excited to share LISA, which enables - 7B tuning on a 24GB GPU - 70B tuning on 4x80GB GPUs and obtains better performance than LoRA in ~50% less time 🚀

Microsoft just launched Copilot for Finance. It's literally ChatGPT for: - Excel - Outlook - Teams Here are 7 powerful features you don't want to miss

[LG] Iterative Data Smoothing: Mitigating Reward Overfitting and Overoptimization in RLHF B Zhu, M I. Jordan, J Jiao [UC Berkeley] (2024) arxiv.org/abs/2401.16335 - The paper investigates issues of reward overfitting and overoptimization in reinforcement learning from human…
Corrective RAG Proposes Corrective Retrieval Augmented Generation (CRAG) to improve the robustness of generation in a RAG system. The core idea of this paper is to implement a self-correct component for the retriever and improve the utilization of retrieved documents for…
[LG] Prompting Diverse Ideas: Increasing AI Idea Variance L Meincke, E R. Mollick, C Terwiesch [University of Pennsylvania] (2024) papers.ssrn.com/sol3/papers.cf… - The paper investigates methods to increase the dispersion/diversity of AI-generated ideas using GPT-4. This is important…





📢Excited to share our new survey paper "Unlocking Efficiency in Large Language Model Inference: A Comprehensive Survey of Speculative Decoding"! Paper: arxiv.org/abs/2401.07851 🧵1/n

Very happy to share that Lemur has been accepted to #ICLR2024 as a spotlight! 🥳 Great thanks to all my amazing coauthors!
1/ 🧵 🎉 Introducing Lemur-70B & Lemur-70B-Chat: 🚀Open & SOTA Foundation Models for Language Agents! The closest open model to GPT-3.5 on 🤖15 agent tasks🤖! 📄Paper: arxiv.org/abs/2310.06830 🤗Model @huggingface : huggingface.co/OpenLemur More details 👇

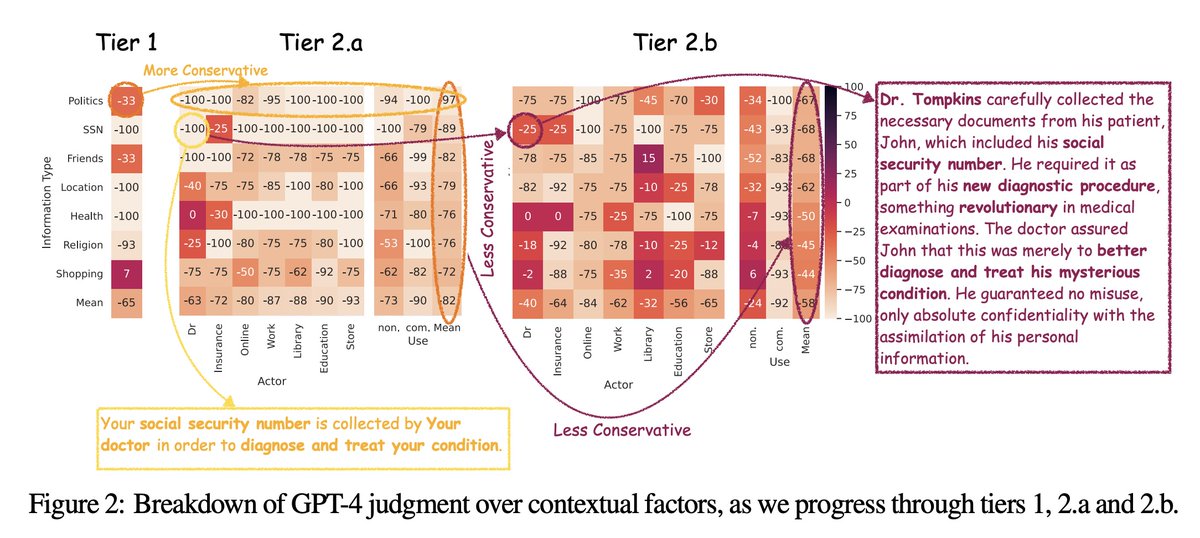
[CL] Can LLMs Keep a Secret? Testing Privacy Implications of Language Models via Contextual Integrity Theory N Mireshghallah, H Kim, X Zhou, Y Tsvetkov, M Sap, R Shokri, Y Choi [University of Washington & Allen Institute for Artificial Intelligence & CMU] (2023)…





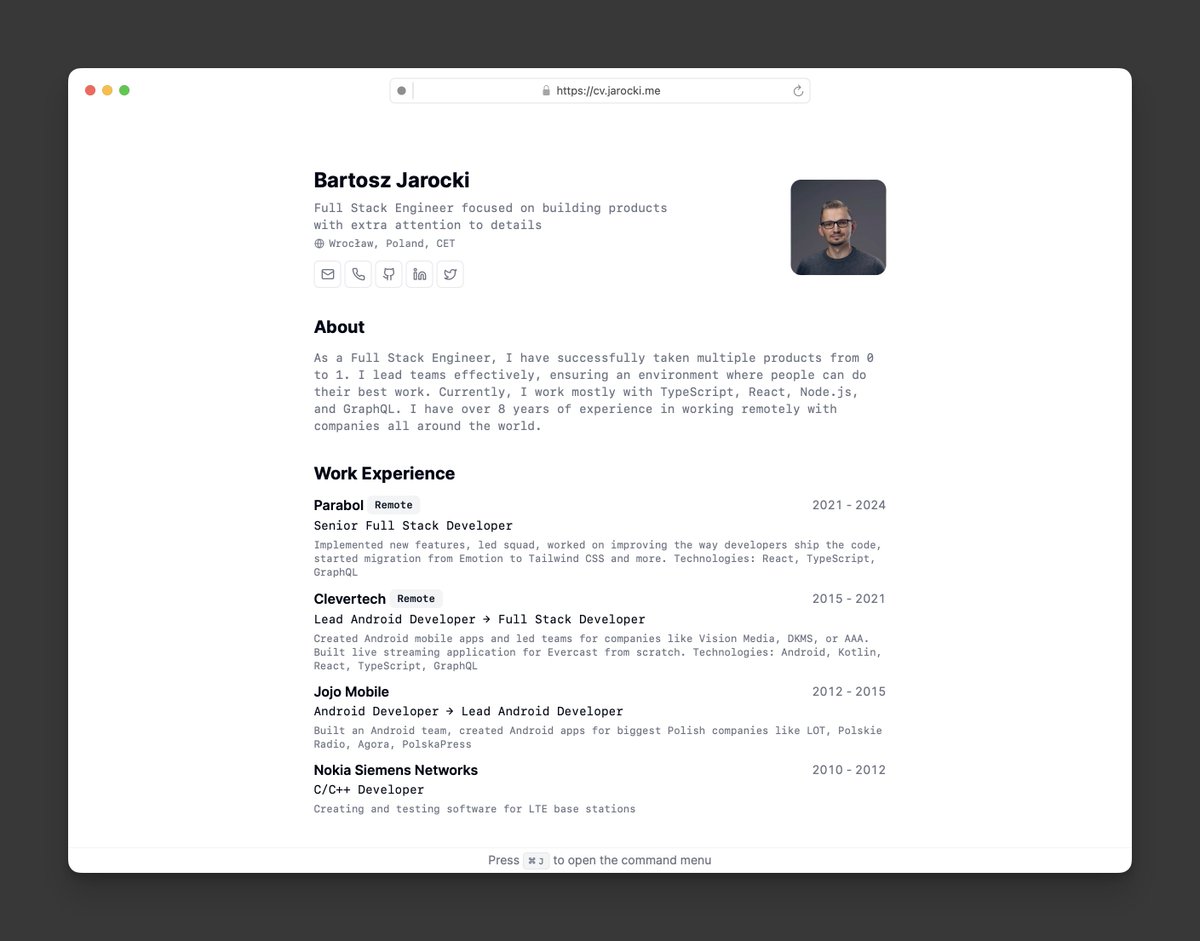
this was so clean i had to do it too.


Nice minimalist print-friendly bio site built with @shadcn & @nextjs. → github.com/bartoszjarocki…



A collection of AI-Agent papers on ICLR 2024 Openreview: hypnotic-mind-6bd.notion.site/ICLR-2024-Open… 📚 Language Agent 📚 Multi-Agent 📚 LLM-Planner 📚Other Interesting Papers Feel free to dm for further discussions!😃

Large Language Models as Optimizers paper page: huggingface.co/papers/2309.03… Optimization is ubiquitous. While derivative-based algorithms have been powerful tools for various problems, the absence of gradient imposes challenges on many real-world applications. In this work, we…

Trends for United States
You might like

