
Jiarui Yao @ExplainMiracles
UIUC CS PhD, 24 Joined May 2023-
Tweets21
-
Followers88
-
Following525
-
Likes58
Glad that our paper has been accepted to Neurips 2025! By gradient variance minimization (GVM), we balance the training data by difficulties and their contribution to the model. We achieve improvement on math reasoning. Please check the original post for more details.
Glad that our paper has been accepted to Neurips 2025! By gradient variance minimization (GVM), we balance the training data by difficulties and their contribution to the model. We achieve improvement on math reasoning. Please check the original post for more details.



(1/5) Super excited to release our new paper on Reinforcement Learning: "Self-Aligned Reward: Towards Effective and Efficient Reasoners"! Preprint: arxiv.org/pdf/2509.05489


🤝 Can LLM agents really understand us? We introduce UserBench: a user-centric gym environment for benchmarking how well agents align with nuanced human intent, not just follow commands. 📄 arxiv.org/pdf/2507.22034 💻 github.com/SalesforceAIRe…


(1/4)🚨 Introducing Goedel-Prover V2 🚨 🔥🔥🔥 The strongest open-source theorem prover to date. 🥇 #1 on PutnamBench: Solves 64 problems—with far less compute. 🧠 New SOTA on MiniF2F: * 32B model hits 90.4% at Pass@32, beating DeepSeek-Prover-V2-671B’s 82.4%. * 8B > 671B: Our 8B…



Reward models (RMs) are key to language model post-training and inference pipelines. But, little is known about the relative pros and cons of different RM types. 📰 We investigate why RMs implicitly defined by language models (LMs) often generalize worse than explicit RMs 🧵 1/6


🎥 Video is already a tough modality for reasoning. Egocentric video? Even tougher! It is longer, messier, and harder. 💡 How do we tackle these extremely long, information-dense sequences without exhausting GPU memory or hitting API limits? We introduce 👓Ego-R1: A framework…
Can LLMs make rational decisions like human experts? 📖Introducing DecisionFlow: Advancing Large Language Model as Principled Decision Maker We introduce a novel framework that constructs a semantically grounded decision space to evaluate trade-offs in hard decision-making…


(1/5) Want to make your LLM a skilled persuader? Check out our latest paper: "ToMAP: Training Opponent-Aware LLM Persuaders with Theory of Mind"! For details: 📄Arxiv: arxiv.org/pdf/2505.22961 🛠️GitHub: github.com/ulab-uiuc/ToMAP

📢 New Paper Drop: From Solving to Modeling! LLMs can solve math problems — but can they model the real world? 🌍 📄 arXiv: arxiv.org/pdf/2505.15068 💻 Code: github.com/qiancheng0/Mod… Introducing ModelingAgent, a breakthrough system for real-world mathematical modeling with LLMs.



How to improve the test-time scalability? - Separate thinking & solution phases to control performance under budget constraint - Budget-Constrained Rollout + GRPO - Outperforms baselines on math/code. - Cuts token 30% usage without hurting performance huggingface.co/papers/2505.05…
🚀 Can we cast reward modeling as a reasoning task? 📖 Introducing our new paper: RM-R1: Reward Modeling as Reasoning 📑 Paper: arxiv.org/pdf/2505.02387 💻 Code: github.com/RM-R1-UIUC/RM-… Inspired by recent advances of long chain-of-thought (CoT) on reasoning-intensive tasks, we…


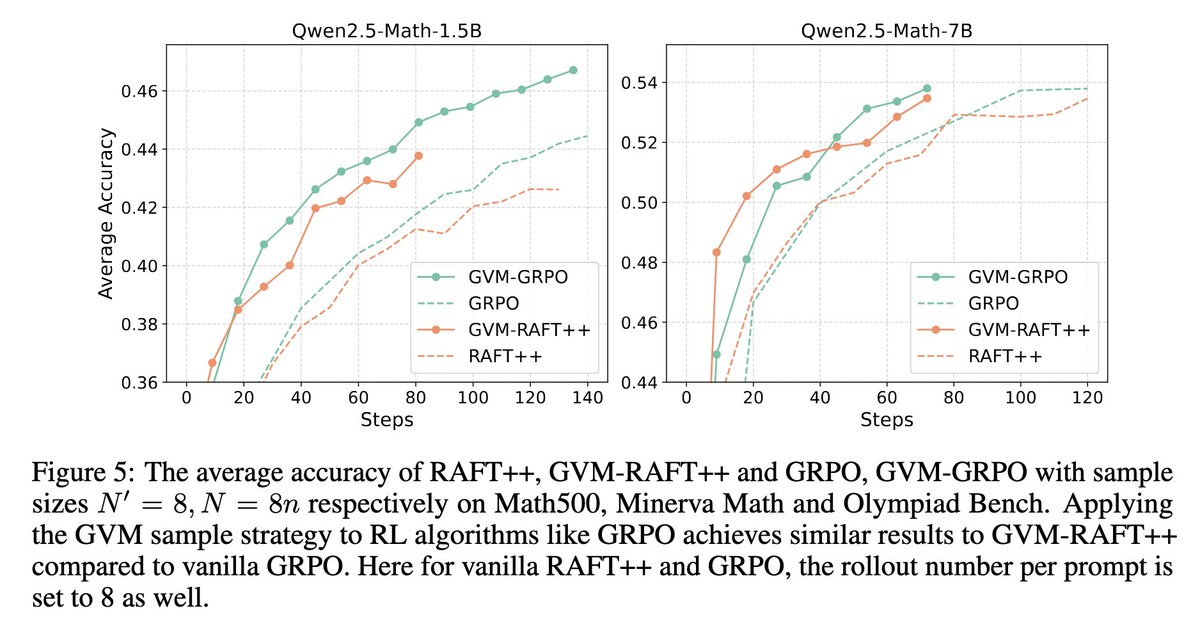
We introduce Gradient Variance Minimization (GVM)-RAFT, a principled dynamic sampling strategy that minimizes gradient variance to improve the efficiency of chain-of-thought (CoT) training in LLMs. – Achieves 2–4× faster convergence than RAFT – Improves accuracy on math…

Thrilled to announce that our paper Sparse VideoGen got into #ICML2025! 🎉 Our new approach to speedup Video Generation by 2×. Details in the thread/paper. Huge thanks to my collaborators! Blog: svg-project.github.io Paper: arxiv.org/abs/2502.01776 Code:…
Thrilled to announce that our paper Sparse VideoGen got into #ICML2025! 🎉 Our new approach to speedup Video Generation by 2×. Details in the thread/paper. Huge thanks to my collaborators! Blog: svg-project.github.io Paper: arxiv.org/abs/2502.01776 Code:…

Welcome to join our Tutorial on Foundation Models Meet Embodied Agents, with @YunzhuLiYZ @maojiayuan @wenlong_huang ! Website: …models-meet-embodied-agents.github.io


Thrilled to share my first project at NVIDIA! ✨ Today’s language models are pre-trained on vast and chaotic Internet texts, but these texts are unstructured and poorly understood. We propose CLIMB — Clustering-based Iterative Data Mixture Bootstrapping — a fully automated…

Negative samples are "not that important", while removing samples with all negative outputs is "important". 🤣
Negative samples are "not that important", while removing samples with all negative outputs is "important". 🤣
🚀Can your language model think strategically? 🧠 SMART: Boosting LM self-awareness to reduce Tool Overuse & optimize reasoning! 🌐 arxiv.org/pdf/2502.11435 📊 github.com/qiancheng0/Ope… Smaller models, bigger brains. Smarter tool use, better results! 🔥 #AI #LLM


Carolyn @kim_carolyn16
162 Followers 3K Following



Kiheax @Kiheax7083
125 Followers 3K Following
Yunsheng Tian @ CoRL2... @YunshengTian
963 Followers 732 Following 🤖 Applied Scientist @Amazon FAR (Frontier AI & Robotics) | PhD @MIT_CSAIL

Sansa Gong @sansa19739319
469 Followers 301 Following Text Diffusion Models; PhD @hkunlp2020 Prev. @sjtu1896
Shangchen Zhou @ShangchenZhou
1K Followers 517 Following Research Assistant Professor at NTU @MMLabNTU - Computer Vision
Lingdong Kong @ldkong1205
1K Followers 497 Following - PhD Candidate @NUSComputing 🦁 - 2025 @Apple PhD Scholar in AI/ML - 3D Scene Perception, Generation, and World Modeling
Yusu Qian @sueqian111
1K Followers 450 Following multimodal research at Apple, previously at NYU @nyuniversity and NJU @njuniversity

Shanyong Wang @Swimmingwang04
8 Followers 76 Following Now visiting at @RutgersU | Exchange @UofIllinois | Undergraduate @ShanghaiTechUni
Zhaoxi Chen @Frozen_Burning
1K Followers 951 Following Ph.D. student @MMLabNTU | Neural Rendering & 3D Generation | Ex Intern @RealityLabs | Undergrad @Tsinghua_Uni
HUANG Qichang @huang85993
302 Followers 8K Following
Kaiyu Yang @KaiyuYang4
5K Followers 2K Following Research Scientist at @Meta Fundamental AI Research (FAIR), New York. Previously: Postdoc @Caltech, PhD @PrincetonCS, Undergrad @Tsinghua_Uni.
Howard @howzzz213
40 Followers 973 Following
Mr. Jack Tung @MrJackTung
293 Followers 6K Following
Jovan Carter @JovanC64207
130 Followers 5K Following
Zhiyong Wang @Zhiyong16403503
784 Followers 4K Following Postdoc at Edinburgh, Ph.D. at CUHK. Former Visiting Scholar at Cornell. Working on reinforcement learning and multi-armed bandits.
Sweedaur @Sweedaur477
15 Followers 775 Following
Deeksha Varshney @Deeksha63834527
273 Followers 2K Following Assistant Professor @IIT Jodhpur; Research Fellow @NUS; PhD @IITPatna; Working on LLM's and their interpretabilty.
Zijia Liu @xwzliuzijia
12 Followers 30 Following Visiting @uiuc_nlp | PhD Candidate @Tongji_Uni | #LLM #AI4S
Zhengyi “Zen” Luo @zhengyiluo
4K Followers 1K Following Research Scientist, GEAR @NvidiaAI | PhD @CMU_Robotics | Founder @CirkitDesign | CS @penn

Tianbao (TB) Yang @yang_ML
633 Followers 1K Following Professor at Texas A&M University; ML/AI researcher; optimization for ML/AI; large reasoning models, developing LibAUC library for training deep neural nets.
Xingyuan Pan @XP_research
17 Followers 55 Following Applied Scientist @ Amazon AGI, prev UIUC CS, Interested in Data-centric AI, LLM, Data Attribution
Johan Obando-Ceron �... @johanobandoc
2K Followers 4K Following Graduate student @Mila_Quebec @UMontrealDIRO | RL/Deep Learning/AI | De Cali/Colombia pal’ Mundo 🇨🇴 | #JuntosProsperamos⚡#TogetherWeThrive| 🌱🌎

harpreet singh @harpree67826976
3 Followers 402 Following
Young @younqchan
330 Followers 5K Following Researcher working on Out-of-Distribution Generalizable Reasoning and AI Scientist from causality perspective.
Zhanpeng Zhou @zhanpeng_zhou
273 Followers 382 Following Ph.D. candidate @sjtu1896 | Exploring the theoretical foundations of deep learning.
B @bbbb_bb_b
0 Followers 4K Following
Xuheng Li @xuhengli_
975 Followers 2K Following CS PhD candidate @UCLA, supervised by @QuanquanGu | RL, deep learning theory, diffusion model | Previously BSc @PKU1898 | Stargazer
MASSIL @Massilabatna
42 Followers 2K Following
Quanquan Gu @QuanquanGu
16K Followers 2K Following Professor @UCLA, Pretraining and Scaling at ByteDance Seed | Recent work: Build AGI | Opinions are my own
Josh @JoshPurtell
2K Followers 5K Following Ars longa Reinforcement learning as a service. We’re hiring
Chloe H. Su @Huangyu58589918
558 Followers 1K Following CS PhD @Harvard @KempnerInst Automated Reasoning @AmazonScience Prev @mldcmu @ntusg
juxiliu789 @juxiliu789
80 Followers 7K Following

Regret @ImperialistsL
377 Followers 737 Following guess how long ill stay jobless until my phd application gets accepted
Alexandre Borghi @_Alex_Borghi_
468 Followers 4K Following ML @SambaNovaAI | Prev. ML research @graphcoreai and @ImaginationTech.
I07XNbUI4 @DeepFeed2
85 Followers 6K Following
Gracelyn @coderlin3
89 Followers 3K Following
Runxin Xu @pigjunebaba
7K Followers 3K Following AI researcher @deepseek_ai | @PKU1898 | @SJTU1896 Opinions are my own.
Tim @Glorious_Tim
126 Followers 3K Following
Simon Shaolei Du @SimonShaoleiDu
9K Followers 2K Following Assistant Professor @uwcse. Postdoc @the_IAS. PhD in machine learning @mldcmu.
Masoud @alborz_esf
127 Followers 2K Following
Xiusi Chen @xiusi_chen
622 Followers 456 Following Postdoc @UofIllinois @uiuc_nlp, Ph.D. @UCLA, BS @PKU1898. RM-R1. Ex-Intern @AmazonScience (x2),@NECLabsAmerica. LLM, Neuro-Symbolic AI.
Peixuan Han @peixuanhakhan
93 Followers 83 Following 2nd year Ph.D. student at UIUC @IllinoisCS LLM Researcher Prev: Tsinghua @Tsinghua_Uni CS Undergrad Amazon @awscloud 25Summer Intern
Dustin Tran @dustinvtran
54K Followers 695 Following I work on reasoning & posttraining at xAI. ex-google
Wenyan Li @Wenyan62
270 Followers 196 Following PhD student at the CoAStaL NLP Group, University of Copenhagen. Former researcher at Comcast AI and SenseTime.
Crystal @crystalsssup
13K Followers 665 Following Staff @Kimi_Moonshot prev. co-maker of ModelizeAI & gemsouls "Personality goes a long way" @UCSanDiego
Tianyi Xiong @tianyixiong23
198 Followers 428 Following PhD student @umdcs | B.Eng. @Tsinghua_Uni | Previously @MSFTResearch @BytedanceTalk
Zixian Ma @zixianma02
714 Followers 255 Following PhD student @UWcse | research intern at @allen_ai | prev @StanfordSVL & @StanfordHCI & @SFResearch
Tairan He @TairanHe99
6K Followers 800 Following Robotics&AI PhD Student @CMU_Robotics Research Intern at @NVIDIA Prev: @MSFTResearch @sjtu1896 Emboddied AI; Humanoid; Robot Learning
Jie Wang @JieWang_ZJUI
1K Followers 420 Following RA@GRASP Lab; @UPenn Prev: @DynaRobotics @IDEACVR @ZJU_China @UIUC; Doing VLAs+Robot Learning; My club: https://t.co/PsXQPPkPpy
Edward Hughes @edwardfhughes
2K Followers 463 Following #OpenEndedness. Staff Research Engineer @GoogleDeepMind, Visiting Fellow @LSEnews, Advisor @coop_ai, Choral Director @GodwineChoir. Views my own.

Wenting Zhao @wzhao_nlp
5K Followers 610 Following reasoning & llms @Alibaba_Qwen Opinions are my own

Yuhao Dong @dyhTHU
94 Followers 193 Following


Quant Science @quantscience_
67K Followers 13 Following Develop profitable trading strategies, build a systematic trading process, and trade your ideas with Python—even if you’ve never done it before.
Sharon Zhou @realSharonZhou
25K Followers 0 Following Building & teaching AI | VP of AI, @AMD | Prev: Founder & CEO, Lamini. CS Faculty & PhD @Stanford. @Google. @Harvard | @MIT 35 under 35. Angel investor.
Lifan Yuan @lifan__yuan
2K Followers 137 Following PhD student @uiuc_nlp @GoogleDeepMind. Prev: @TsinghuaNLP
Yining Ye(叶奕宁) @Yining_Ye
332 Followers 227 Following Working on LLM/VLM Tool Learning and Reasoning at Tsinghua and Bytedance, reading at least one paper a day — The future will not invent itself.
Jure Leskovec @jure
44K Followers 396 Following Professor of #computerscience @Stanford; Co-founder at https://t.co/hhm1j5wP0f #machinelearning #graphs.
Zhi Su@CoRL @ZhiSu22
2K Followers 200 Following Undergrad @Tsinghua_IIIS | 🤖 Robot Learning | Looking for PhD position
Princeton NLP Group @princeton_nlp
5K Followers 62 Following Princeton NLP Group led by @prfsanjeevarora @danqi_chen @karthik_r_n
Princeton PLI @PrincetonPLI
2K Followers 32 Following Princeton University initiative enhancing fundamental understanding of AI, enabling its use in academic disciplines, and examining AI's societal implications.
He Wang @HughWang19
2K Followers 153 Following Assistant Professor of Computer Science at Peking University, Founder and CTO of Galbot.
Fan Nie @FanNie1208
779 Followers 362 Following AI @Stanford | Prev. @EPFL @SJTU1886 |Research in Reliable AI & Large Language Models
Jiayi Geng @JiayiiGeng
1K Followers 210 Following PhD @LTIatCMU | MSE @Princeton_nlp @PrincetonPLI @cocosci_lab @PrincetonCS. Working on Multi-agent / Cognitive science & LLMs
Wei-Chiu Ma @weichiuma
2K Followers 208 Following Assistant Professor @Cornell @CornellCIS Prev: Postdoc @allen_ai @uwcse; PhD @MIT_CSAIL; Sr. Research Scientist @UberATG @Waabi_ai
Yunsheng Tian @ CoRL2... @YunshengTian
963 Followers 732 Following 🤖 Applied Scientist @Amazon FAR (Frontier AI & Robotics) | PhD @MIT_CSAIL
Rocky Duan @rocky_duan
3K Followers 97 Following Research Lead @ Amazon FAR (Frontier AI & Robotics). Previously @CovariantAI CTO, @OpenAI, @UCBerkeley PhD. 2024 Forbes 30 Under 30.
zhyncs @zhyncs42
3K Followers 538 Following 🌁 OPINIONS ARE MY OWN, Homepage https://t.co/saCowtppUm, Just for fun @lmsysorg SGLang, Prev @basetenco @meituan @Baidu_Inc
a16z @a16z
882K Followers 52 Following we invest in software eating the world https://t.co/A9eTFq6plZ https://t.co/MXGUBJoesw Watch "The Ben & Marc Show": https://t.co/eRuDhx7kpe

Fangru Lin @FangruLin99
4K Followers 467 Following Research Intern @GoogleDeepMind; DPhil student @UniofOxford; Clarendon Scholar; Prev @MSFTResearch, @Microsoft, @turinginst; Computational Linguist
Richard Sutton @RichardSSutton
52K Followers 64 Following Student of mind and nature, libertarian, chess player, cancer survivor. @ Keen, UAlberta, Amii, https://t.co/u8za2Kod54, The Royal Society, Turing Award
Zhijian Liu @zhijianliu_
2K Followers 824 Following Research Scientist @NVIDIA. Assistant Professor @UCSanDiego. PhD @MIT. Efficient AI. Views are my own.
HKUNLP @hkunlp2020
117 Followers 85 Following We are a group of researchers working on natural language processing in the Department of Computer Science at the University of Hong Kong.
Qianqian Wang @QianqianWang5
3K Followers 440 Following Incoming Assistant Professor at Harvard and Kempner Institute. Postdoc at UC Berkeley. Former Ph.D. student at Cornell Tech. https://t.co/LyIdb5HmM9

Yushi Hu @huyushi98
3K Followers 1K Following 🎓PhD student @uwnlp | Prev. @AIatMeta @allen_ai @GoogleAI @UChicago | Building multimodal intelligence
Skywork @Skywork_ai
6K Followers 152 Following Skywork Super Agents: the Originator of Al Workspace Agents, turns your 8 hours of work into 8 minutes. Support: https://t.co/Zvze6mFI6E
Chuan Wen @ChuanWen15
483 Followers 343 Following Assistant Professor @sjtu1896. Prev PhD student @Tsinghua_IIIS w/ @gao_young. Prev visitor @berkeley_ai w/ @pabbeel .
Jiahui Yu @jhyuxm
18K Followers 933 Following Perception @OpenAI; previously co-led Gemini Multimodal @GoogleDeepMind. opinions are my own.
Shuchao Bi @shuchaobi
13K Followers 693 Following Research @Meta Superintelligence Labs, RL/post-training/agents; Previously Research @OpenAI on multimodal and RL; Opinions are my own.
Hongyu Ren @ren_hongyu
23K Followers 692 Following research @meta superintelligence. CS PhD @stanford. prev @openai, led the development of o3-mini and o1-mini.
Dylan Foster 🐢 @canondetortugas
3K Followers 1K Following Foundations of RL/AI @MSFTResearch. Previously @MIT @Cornell_CS https://t.co/vQIdUzsw8B RL Theory Lecture Notes: https://t.co/bhgL3aKIk0

Feng Yao @fengyao1909
1K Followers 662 Following Ph.D. student @UCSD_CSE | Intern @Amazon Rufus Foundation Model Ex. @MSFTResearch @TsinghuaNLP


Yuhuai (Tony) Wu @Yuhu_ai_
44K Followers 453 Following Co-Founder @xAI. Grok Reasoning, STaR, Minerva, AlphaGeometry, Autoformalization, AlphaStar, Memorizing transformer.
Jinjie Ni @NiJinjie
2K Followers 523 Following AI researcher building foundation models. I'm on the job market.Trends for United States
You might like



















