
Hugo @Mldhug
PhD student in multimodal learning for audio understanding at @telecomparis, ex-MVA (ENS Paris Saclay) Joined August 2019-
Tweets12
-
Followers40
-
Following337
-
Likes51
Given a number of ASR models of different sizes, how can I allocate an audio sample to the smallest one that will be good enough ? @Mldhug worked on this question during his internship, and ended up with interesting conclusions you will find in our paper !
Given a number of ASR models of different sizes, how can I allocate an audio sample to the smallest one that will be good enough ? @Mldhug worked on this question during his internship, and ended up with interesting conclusions you will find in our paper !

It's really surprising how far one can go with *linear* predictors in the autoregressive setting. Interesting theory and experiments on TinyStories: a linear model (with 162M params :-) ) can generate totally coherent text with few grammatical mistakes. arxiv.org/abs/2309.06979
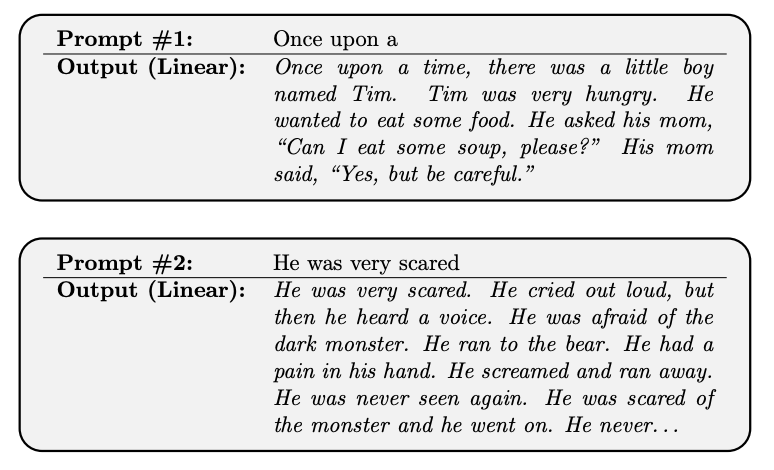

Why is Whisper so robust to background noise? Not because Whisper suppresses them, but because Whisper 𝐮𝐧𝐝𝐞𝐫𝐬𝐭𝐚𝐧𝐝𝐬 them! Check out the amazing work by Yuan Gong @YGongND. They reveal this emergent capability of Whisper, and get SOTA *simultaneous* ASR + audio tagging


Towards Language Models That Can See: Computer Vision Through the LENS of Natural Language Looks promising; I'll have to try and see if it stands upto some poking ;-) Love that they get around the need for multimodal training. ar5iv.org/abs/2306.16410 github.com/ContextualAI/l…


DreamDiffusion: Generating High-Quality Images from Brain EEG Signals paper page: huggingface.co/papers/2306.16… paper introduces DreamDiffusion, a novel method for generating high-quality images directly from brain electroencephalogram (EEG) signals, without the need to translate…


Super excited to finally launch Voicebox🤩, the most versatile speech generative model ever💬👄 Demo page: voicebox.metademolab.com

Super excited to finally launch Voicebox🤩, the most versatile speech generative model ever💬👄 Demo page: voicebox.metademolab.com

Who killed non-contrastive image-text pretraining? @AlecRad and @_jongwook_kim with the below Fig2 in CLIP. Who collected the 7 Dragonballs and asked Shenron to resurrect it? Yours truly, in this new paper of ours. Generative captioning is not only competitive, it seems better!




Thanks for tweeting, @ak! We’re super excited about the future of text-only vision model selection! 🙏 @MarsScHuang @kcjacksonwang @syeung10
Thanks for tweeting, @ak! We’re super excited about the future of text-only vision model selection! 🙏 @MarsScHuang @kcjacksonwang @syeung10

Macaw-LLM: Multi-Modal Language Modeling with Image, Audio, Video, and Text Integration paper page: huggingface.co/papers/2306.09… Although instruction-tuned large language models (LLMs) have exhibited remarkable capabilities across various NLP tasks, their effectiveness on other data…


We'll present GeneCIS at #CVPR2023 (Highlight) TL;DR: While most image representations are *fixed*, we present a general way to train and evaluate models which can adapt to different *conditions* on the fly. Code: github.com/facebookresear… Project page: sgvaze.github.io/genecis/ 🧵
We'll present GeneCIS at #CVPR2023 (Highlight) TL;DR: While most image representations are *fixed*, we present a general way to train and evaluate models which can adapt to different *conditions* on the fly. Code: github.com/facebookresear… Project page: sgvaze.github.io/genecis/ 🧵


Markita Capurro @CapurrMarkit
65 Followers 5K Following
Suzanna Victorine @SuzannaVic50137
102 Followers 5K Following
Leana Brueckner @BruecknerL46438
36 Followers 5K Following
Myrtie Tench @MyrtieT36381
72 Followers 5K Following

Lin Fahrenbruck @fahrenbruc18863
52 Followers 5K Following
Aurian @sound_au
4 Followers 37 Following PhD student at Telecom Paris in ADASP Group. Currently working on learning music representations.
Jorgi Kukla @JorgiKuk
83 Followers 5K Following
Kelli Bradford @KelliB58262
126 Followers 3K Following
Maysa Senesenes @mays_senesen
27 Followers 5K Following

Morgan Guzon @guzo_mor
37 Followers 5K Following
Huck Yang @huckiyang
569 Followers 528 Following Sr. Research Scientist @NVIDIAAI Generative Error Correction | Ph.D. @GeorgiaTech | Past: @GoogleAI @AmazonScience | 🗣️ education
Michel Olvera @michelolzam
163 Followers 1K Following PhD in Computer Science @Univ_Lorraine. Machine learning and signal processing enthusiast. Researcher at @telecomparis.
Elena Georgieva 🎶 @elenatheodora1
588 Followers 619 Following PhD Candidate @nyuMARL. Former lecturer & M.A.'19 @Stanford @CCRMA I do music/AI research, audio engineering, and vocals. she/her
Jing Liu @JLiu_Compuling
295 Followers 1K Following 1st year PhD student @CoML_ENS | Msc @LeuvenAi| ResMA @CLSRadboud| interested in memory-augmented language models
Becca Baker @BeccaBaker73854
144 Followers 3K Following
Matthieu Rouif @matthieurouif
9K Followers 3K Following Co-founder & CEO @photoroom_app (YC S20) - Photo editor to sell it like a pro. ex GoPro, Stanford, Polytechnique
Michal Valko @misovalko
5K Followers 2K Following Llama @AIatMeta Paris & Inria & MVA - Ex: Gemini and BYOL @GoogleDeepMind
Maureen de Seyssel @Maureendss
513 Followers 638 Following PhD from @CoML_ENS in speech, ml and cognition. Ex research intern @MetaAI. @CoML_ENS. unsupervised (multilingual) speech representations
Thibaut Loiseau @thibaut_loiseau
2 Followers 47 Following

Yassine Elkheir @YassineElkheir
21 Followers 416 Following
Axel @Axelito9803
2 Followers 21 Following
Robin Alg @AlgayresR
96 Followers 164 Following Research Scientist at @mbzuai on LLM for biology. Formerly PhD at @ENS_ULM @Inria and gap year at @AIatMeta (FAIR) https://t.co/cvmsk7mbUs
Ognjen Todic @ognjen_todic
495 Followers 2K Following Entrepreneur & Engineer. Building on-device speech recognition solutions @ https://t.co/mrhEaR4f9O and organically growing the business.
Salah Zaiem @salah_zaiem
548 Followers 2K Following Research Scientist @GoogleDeepMind. Speech and Audio processing. Alumni @Polytechnique and @telecomparis
Raphaël Smagacz @RaphSma
179 Followers 221 Following 💼 Responsable communication France 3 Nouvelle-Aquitaine zone @F3PoitouChtes et #NoA // @comf3aqui

Malard Loic @LoicMalard70333
8 Followers 11 Following
Pourcel Julien @PourcelJulien
20 Followers 388 Following PhD student at @inria (@flowersinria team) | @ENS_ParisSaclay (MVA)
Amric Trudel @AmricTrudel
46 Followers 107 Following Consultant Data Scientist @ OCTO Technology // Alumni @ 42 Paris // Ancien président de 42-AI // Alumni @ McGill University
ANDREWS Roland @ANDREWSRoland1
32 Followers 260 Following phd Sierra + Willow . X2019-MVA deep learning, optimisation, diffusion
Shashs @Shashs4
8 Followers 155 Following
Lena Dupont @LenaDupont16
1 Followers 2 Following
Daniel Jack @Stritzer91
175 Followers 291 Following Netanyahou est un nazi, et leurs soutiens le sont tout autant. Mort au gouvernement israélien
Laura @Laura_Schoo
6 Followers 23 Following
Xavier @xavier_brt
323 Followers 490 Following

youm @youmgui
40 Followers 141 Following
Yixiao Zhang @Yixiao_Zhang_
640 Followers 284 Following Intern at @stabilityai, ex @sonyai_global @yamahamusic_jp @MSFTResearch intern; final year AI Music PhD student @c4dm and @apple. I am looking for full-time job
Leo Boytsov @srchvrs
7K Followers 2K Following Sr. Research Scientist @AWS Labs (ph-D @LTIatCMU) working on unnatural language processing, speaking πtorch & C++. Opinions sampled from MY OWN 100T param LM.
Xin Eric Wang @xwang_lk
7K Followers 1K Following Multimodal and Embodied AI Researcher / Professor @UCSC. Director of https://t.co/Y4swOBag21. AI for Humanity in the long run. he/him
Aurian @sound_au
4 Followers 37 Following PhD student at Telecom Paris in ADASP Group. Currently working on learning music representations.
Emmanouil Benetos @em.. @emmanouilb
1K Followers 635 Following Reader @QMEECS @c4dm @intelsensing @DERI_QMUL and Turing Fellow @turinginst - research on machine listening / audio analysis.
Annamaria Mesaros @AnnamariaMsros
193 Followers 64 Following Associate Professor, Tampere University, Finland
Hilde Kuehne @HildeKuehne
3K Followers 763 Following Professor for CS at @UniBonn and affiliated Professor at MIT-IBM Watson AI lab @MITIBMLab - Multimodal learning and video understanding



Elio Quinton @elio_elioo
780 Followers 536 Following AI - Audio - Music. VP of AI @UMG. Former @c4dm @qmul
Russ Salakhutdinov @rsalakhu
100K Followers 140 Following UPMC Professor of Computer Science at Carnegie Mellon University, ex-Director of AI research at @Apple, co-founder Perceptual Machines (acquired by Apple)
Hao-Wen (Herman) Dong.. @hermanhwdong
768 Followers 258 Following Incoming Assistant Professor at University of Michigan | PhD Candidate at UC San Diego | Generative AI for Music & Audio
ParisAI @parisai
1K Followers 109 Following #AI meetup for bluechips, startups & academics in Paris with a strong product focus. Run by @raffikamber @AlexCFlamant @nathanbenaich
Gaurav @mitts1910
1K Followers 234 Following Senior Researcher @ Microsoft working on Responsible AI and Multi-modal Content Understanding
Irina Rish @irinarish
9K Followers 994 Following prof UdeM/Mila; Canada Excellence Research Chair; AAI Lab head https://t.co/UzlrC7ZrGF; INCITE project PI https://t.co/0rV7szd7rH; CSO https://t.co/XDhj6MEtUj

Timothy Gowers @wtgow.. @wtgowers
45K Followers 188 Following Mathematician. Professeur titulaire de la chaire Combinatoire au Collège de France. Also fellow of Trinity College Cambridge.
Huck Yang @huckiyang
569 Followers 528 Following Sr. Research Scientist @NVIDIAAI Generative Error Correction | Ph.D. @GeorgiaTech | Past: @GoogleAI @AmazonScience | 🗣️ education
Wei Ping @_weiping
783 Followers 220 Following Principal Research Scientist @NVIDIA. Working on large language models and generative models. Views are my own.
Rafael Valle @RafaelValleArt
941 Followers 179 Following Research Manager and Scientist at NVIDIA. UC Berkeley alumn. Love, music and motorcycles!


Peeters Geoffroy @GeoffroyPeeters
909 Followers 209 Following Full professor at Telecom Paris, Institut Polytechnique de Paris (audio signal processing, deep learning, music information retrieval)

Sanjeel Parekh @SanjeelParekh
17 Followers 37 Following Research Scientist at Meta Reality Labs Research
Javier Nistal @latentspaces
825 Followers 507 Following Researcher @SonyCSLMusic. Former PhD @TelecomParis_ | @MIDASconsoles | Intern @JukedeckRandD, @SoundCloud. Exploring deep generative models for sound and music
Eduardo Fonseca @edfonseca_
1K Followers 558 Following Research Scientist @GoogleAI. Sound Understanding. Previously @mtg_upf. He/him.
Amirhossein Habibian @amir_habibian
911 Followers 290 Following Research Scientist (Director) @Qualcomm AI Research
Alon Ziv @lonziks
313 Followers 52 Following PhD Student @ The Hebrew University of Jerusalem; ex Research Scientist Intern @ Meta AI (FAIR); ex DL Researcher @ Mobileye.

Seungwhan Shane Moon @shane_moon
584 Followers 197 Following | Research Scientist @ Facebook | | PhD @ LTI SCS, CMU |
Djamé.. @zehavoc
6K Followers 3K Following Associate professor in NLP, engaged citizen. Tweeting about work, life and stuffs that I care about. All my tweets can be used freely. Personal account.
DCASE Challenge @DCASE_Challenge
641 Followers 29 Following Challenge on Detection and Classification of Acoustic Scenes and Events https://t.co/j9544Zu0yJ https://t.co/cQqlshpkU7…

Mathieu Fontaine @MathieuFontai19
160 Followers 226 Following Assistant Professor at Telecom Paris. Working on machine listening.


Vivek Kumar @vivek_kumar
2K Followers 614 Following Senior Manager, Sound Understanding at @googleai. Ex @Dolby & @Broadcom. Talks and Investments 👉🏽 https://t.co/Iqmk4l7YMF

Sepp Hochreiter @HochreiterSepp
10K Followers 395 Following Pioneer of Deep Learning and known for vanishing gradient and the LSTM. I mostly tweet about random ArXiv papers which sparked my interest.
Alaa El-Nouby @alaa_nouby
521 Followers 302 Following Research Scientist at @Apple. Previous: @Meta (FAIR), @Inria, @MSFTResearch, @VectorInst and @UofG . Egyptian 🇪🇬 Deprecated twitter account: @alaaelnouby
Victor Sanh @SanhEstPasMoi
9K Followers 2K Following Dog sitter by day, Scientist at @huggingface 🤗 by night
Nando de Freitas 🏳.. @NandoDF
97K Followers 659 Following I research intelligence to understand it and to harness it wisely. Part of AlphaGo tuning, AlphaCode, learning to learn, Lyria, Imagen2, Gato, rGemma

Polina Kirichenko @polkirichenko
3K Followers 1K Following PhD student at New York University, Visiting Researcher at @MetaAI FAIR Labs 🇺🇦
Elena Georgieva 🎶 @elenatheodora1
588 Followers 619 Following PhD Candidate @nyuMARL. Former lecturer & M.A.'19 @Stanford @CCRMA I do music/AI research, audio engineering, and vocals. she/her
Natalie Schluter @natschluter
5K Followers 486 Following #NoJusticeNoPeace-- Machine Learning Researcher at Apple MLR-- All tweets/opinions my own
Magdalena Fuentes @mfu3ntes
791 Followers 265 Following Assistant Professor of Music Technology and Integrated Design & Media at @nyuMARL and @IdmNyuIf you ever actually looked at these benchmarks, the model predictions, and what the claimed "human performance" means, you would know. Hint: it's unrelated to intelligence. Looks like many people, especially more prominent ones, are commenting and opining blindly.

Interesting how in all these domains AI is asymptoting at roughly human performance - where's the AI zooming past us to superintelligence that Kurzweil etc. predicted/feared?

Audio Dialoges is finally out! It describes how we leveraged pre-trained LMs and joint audio and language embeddings to produce a dataset that gives Audio LLMs the ability to have multi-turn dialogues with users. arxiv.org/abs/2404.07616
Hello Twitter! A few weeks ago, I defended my PhD thesis (Title below). I want to thank everybody that joined, or helped along the way and especially my supervisors, jury members and colleagues. I joined since the Google Deepmind team here in Paris. Good things ahead (I hope 🤞!)

Hello Twitter, I am happy to announce that I will be defending my PhD thesis next week! 👨🎓🔔 🕞When? Monday, March 25th, 15h30. 📗Title: Informed self-supervised speech representation learning. 🏫Where? @telecomparis Feel free to DM me for a Zoom link or for details to join!

There is a commonly held belief that Transformers have no inductive bias and that this bias is learned throughout the training process. This is not true. Transformers have very strong inductive biases.

People saying "Hollywood is over" remind me of those who were saying "Google is over" one year ago. Same intellectual caliber.

many say now "to do video gen well, the system must learn a world model and understand the physics" but to me *the* big lesson from LLMs is how much impressive performance can be faked *without* underlying model and semantic understanding, just by mimicking observed patterns.

R2: While the results are impressive, this is a simple combination of diffusion transformer (ICCV 2023) and latent diffusion model (CVPR 2022). Limited novelty. Weak reject.

Introducing Sora, our text-to-video model. Sora can create videos of up to 60 seconds featuring highly detailed scenes, complex camera motion, and multiple characters with vibrant emotions. openai.com/sora Prompt: “Beautiful, snowy…

If you need $7 trillion to build the chips and the energy demand equivalent to the consumption of the United Kingdom, then - with a high-level of confidence - I assure you that you have the wrong architecture.

I am getting a bit confused by the benchmarks / leaderboard for LLMs. Every 5 min there is a tweet about a company I never heard about whose 1b model crushes whatever 30b model was the king 5 min before. We need a TL;DR of the LLM landscape.
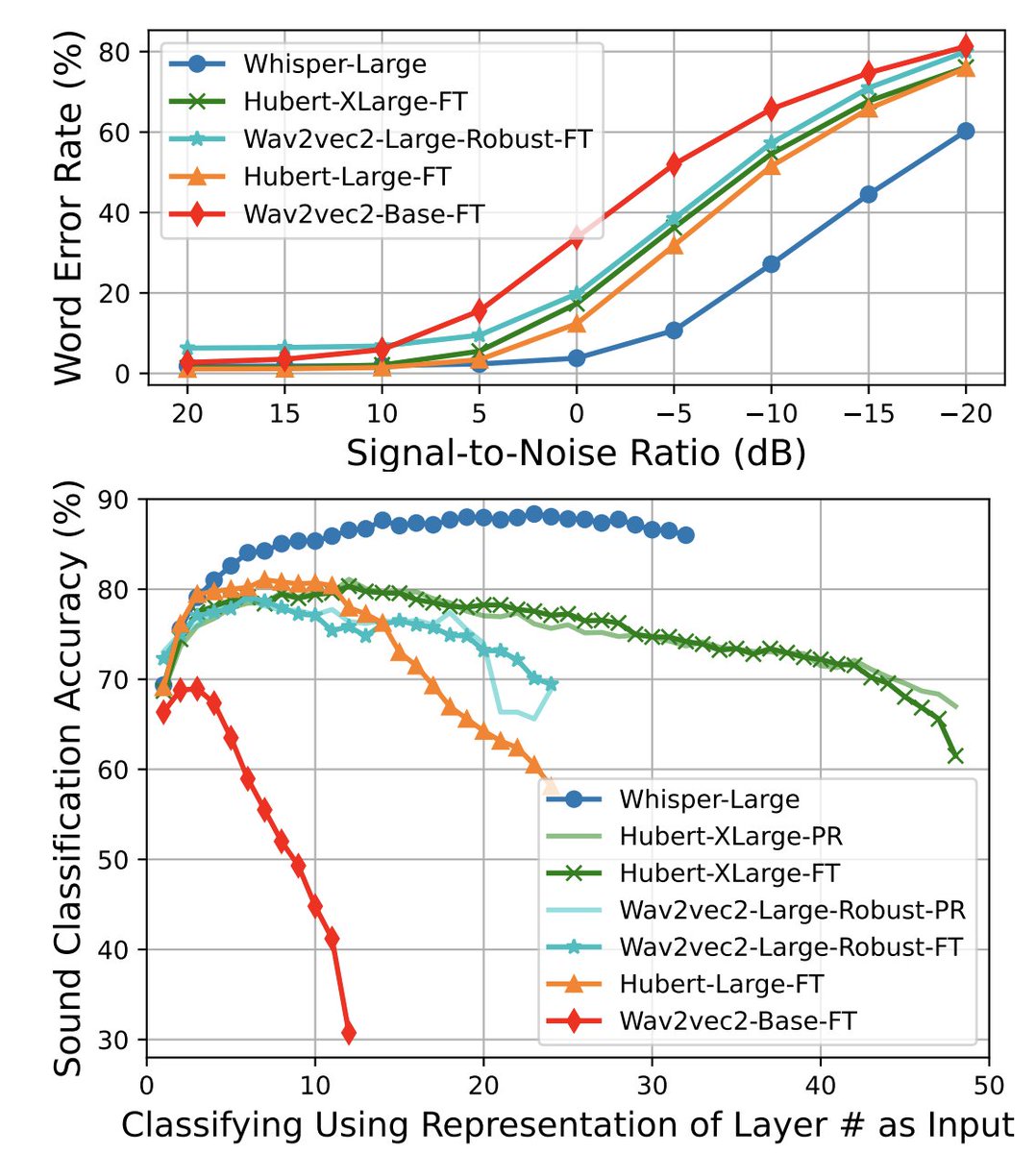
Nvidia presents Audio Flamingo A Novel Audio Language Model with Few-Shot Learning and Dialogue Abilities paper page: huggingface.co/papers/2402.01… Augmenting large language models (LLMs) to understand audio -- including non-speech sounds and non-verbal speech -- is critically…
Happy to share MAGNeT 🧲! pages.cs.huji.ac.il/adiyoss-lab/MA… A single non-autoregressive model, for text-to-music and text-to-sound generation, with quality on par with SOTA models, while being 7x faster. We open-sourced our code (including training) on audiocraft! + a Gradio demo. [0/6]
Proud to announce that I successfully defended my PhD yesterday at @ecolenormalesup! 👩🎓 🥳 I'm so grateful to have been accompanied throughout by the two best directors Emmanuel Dupoux (@CoML_ENS) and Guillaume Wisnewski, who even agreed to pose for a quick post-defence picture📸


By the way, to the Dr. 3/10 reviewer from any typical ML conference: speech is not a "narrow" field. ML conferences explicitly call for papers dealing with Audio.

@geoffreyhinton I'd like to respectfully point out that the logic in this argument is based on a flawed model for how scientists think. Scientists don't just take a weighted average of others' opinions to form their own. A good scientist takes as input lots of data, including others' opinions,…

Thrilled to share #Lyria, the world's most sophisticated AI music generation system. From just a text prompt Lyria produces compelling music & vocals. Also: building new Music AI tools for artists to amplify creativity in partnership w/YT & music industry deepmind.google/discover/blog/…

I have a secret for you... #manufacturedoutrage


Will releasing the weights of large language models grant widespread access to pandemic agents? Turns out, yes, probably. 1/5


1/6 We updated “Implicit variance regularization in non-contrastive SSL,” by @manu_halvagal and @AxelLaborieux with new results for NeurIPS camera-ready: arxiv.org/abs/2212.04858 neurips.cc/virtual/2023/p…

We have a second accepted paper at #EMNLP2023 (with @adiyossLC) on Generative Spoken Language Modelling (textless NLP). We managed to generate clean speech sentences using continuous units instead of the discrete HuBERT. @CoML_ENS
Given a number of ASR models of different sizes, how can I allocate an audio sample to the smallest one that will be good enough ? @Mldhug worked on this question during his internship, and ended up with interesting conclusions you will find in our paper !
The preprint of our work (with @salah_zaiem and @AlgayresR) on sample dependent ASR model selection is available on arXiv! In this paper we propose to train a decision module, that allows, given an audio sample, to use the smallest sufficient model leading to a good transcription
Trends for United States
You might like




