
NebberCracker @NebberCrackker
Need Monte Carlo Simulation in life Joined October 2023-
Tweets68
-
Followers11
-
Following332
-
Likes4K



It's a bird. It's a plane. It's gaussian splatting. When @Framestore needed to bring Kryptonian tech to Earth, they turned to gaussian splatting. In the recently released Superman, every shot of Kal-El's parents is a dynamic splat. I spoke to the team at Framestore about…
Solving Triton Puzzles is such a fun activity !!


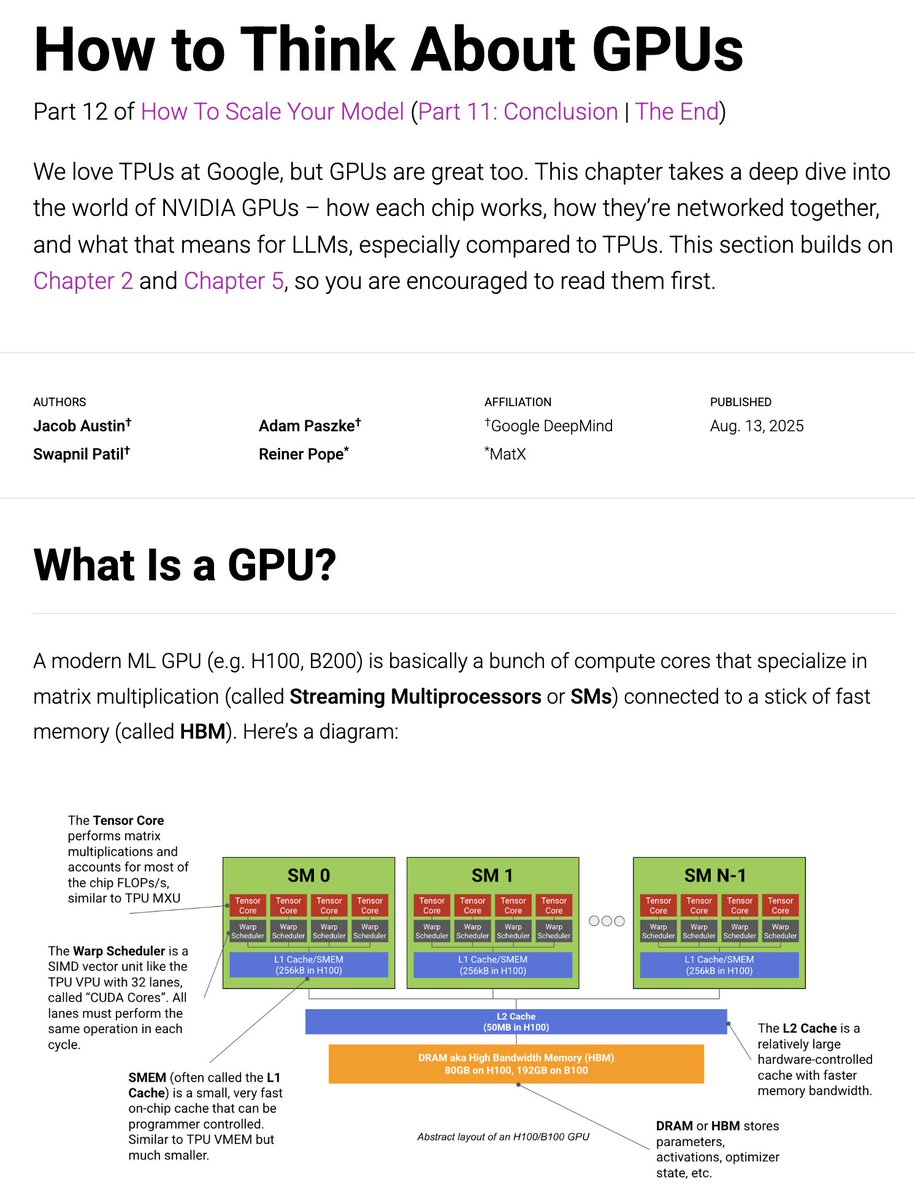
Today we're putting out an update to the JAX TPU book, this time on GPUs. How do GPUs work, especially compared to TPUs? How are they networked? And how does this affect LLM training? 1/n


for those curious about how 1M context model is even possible here is a 47min deep dive on the minimax-01 open model in it we cover the lightning linear attention mechanism the hybridization strategy to make it work and how to go beyond and make the model multimodal wild stuff

Yo chat... Check out my article on batching strategies in LLMs Inference.. open.substack.com/pub/bargav/p/b… Any feedback back is highly appreciated 🤘
Distributed Training.... I am coming to get ya.. !!


Sparsity can make your LoRA fine-tuning go brrr 💨 Announcing SparseLoRA (ICML 2025): up to 1.6-1.9x faster LLM fine-tuning (2.2x less FLOPs) via contextual sparsity, while maintaining performance on tasks like math, coding, chat, and ARC-AGI 🤯 🧵1/ z-lab.ai/projects/spars…

Me when I sing both parts of Luther



We know Attention and its linear-time variants, such as linear attention and State Space Models. But what lies in between? Introducing Log-Linear Attention with: - Log-linear time training - Log-time inference (in both time and memory) - Hardware-efficient Triton kernels

I think after Attention (learnt back in 2020), Flash-Attention is the only machine learning algorithm that gave me immense happiness once I cracked it. #MachineLearning #Llm

Spent last week building an #LLM completely from scratch — and I mean everything: BPE tokenizer (optimized), Linear, SWIGLU, RoPE attention, and full Transformer blocks, AdamW, cross_entropy, and top-p decoding etc.. and trained on children stories. github.com/bargav25/llm
wrapping up things in my current job to move to a new job. And the worst has come.... I've to document all my code now🥲
How much time do you think it takes to train a Byte Pair Encoding Tokenizer on corpus of 2M docs? Well.... I did it in 2 mins. Main Thanks to MultiThreading and hashmaps. 😉 bargav.substack.com/p/bpe-tokenize… github.com/bargav25/fast_… #LLM #ArtificialIntelligence #DeepLearning
I was one of them 🥲

Just published my blog on Pipeline Parallelism fundamentals! Learn how it works. Check it out: medium.com/@bargav25/dist… Feedback welcome! More deep learning content coming soon. #MachineLearning #LLMs #DistributedTraining
Hi! Our team is building a product for men's skincare. Could you please fill out this short form (2-3 minutes) to help us better understand what men are looking for? Thank you so much! #skincareroutine #skincare #ai #hackathon #ml #fashion forms.gle/3syFkLbbVhryWA…
I just published KeypointNeRF: A New Approach to 3D Motion Capture Using Neural Radiance Fields #3DComputerVision #NeuralRadianceFields #DeepLearning #ComputerVision link.medium.com/lkKcgVjHLPb

Orvrergief @Orvrergief6320
54 Followers 2K Following Like to talk Do not hold any investment products
Someone @aoslngeles
0 Followers 248 Following
Houpal @Houpal3323
45 Followers 478 Following
Tianyuan Zhang @tianyuanzhang99
2K Followers 935 Following PhDing in@MIT, towards general intelligence and lifelong machine M.S. in CMU, B.S. in PKU.
Yifei Wang @yifeiwang77
2K Followers 2K Following Postdoc @MIT_CSAIL. Self-supervised learning. Foundation Models. AI Safety. Prior BS+BA+PhD @PKU1898.
Vrarlief @Vrarlief354
44 Followers 1K Following
Ken Osinski-Goyette @GoyetteKen45098
102 Followers 3K Following
Robert Lombardi @robertlombardi_
288 Followers 1K Following I help struggling dropshipping stores achieve $50K+ monthly profit with proven optimization tactics.
Thiplur @ThiplurDwn
4 Followers 86 Following
Tytoa @TytoaR1qY
12 Followers 126 Following
Charoor/ai (e/acc) @charoori_ai
145 Followers 478 Following Building AI, looking to collab AI @ BostonU / Ex AI-dev @ Microsoft, Nvidia
Melissa Pan @melissapan
2K Followers 549 Following CS PhD @UCBerkeley Sky Lab 🐻 Systems & AI & Sustainability 🌍 Prev: @google, @ibm, @CarnegieMellon🐕🦺, @UofT🇨🇦

Nathan Chen @nathancgy4
2K Followers 600 Following understanding models @tilderesearch, (hardware-aligned) ml & open-source, 16

Dan Fu @realDanFu
7K Followers 221 Following Incoming assistant professor at UCSD CSE in MLSys. Currently recruiting students! Also running the kernels team @togethercompute.
Maithra Raghu @maithra_raghu
20K Followers 513 Following Cofounder and CEO @Samaya_AI. Formerly Research Scientist Google Brain (@GoogleAI), PhD in ML @Cornell.
Anne Ouyang @anneouyang
7K Followers 928 Following Building @Standard_Kernel, CS PhD student @Stanford | prev: cuDNN @Nvidia, M.Eng, B.S. in CS @MIT | efficient scalable self-improving AI systems | 🌽KernelBench
Azalia Mirhoseini @Azaliamirh
15K Followers 528 Following Asst. Prof. of CS at Stanford, Google DeepMind. Prev: Anthropic, Google Brain. Co-Creator of MoEs, AlphaChip, Test Time Scaling Laws.
Vitaliy Chiley @vitaliychiley
3K Followers 1K Following LLM Reasearch @ Meta. ex @DataBricks (@DBRXMosaicAI), @CerebrasSystems

Philipp Schmid @_philschmid
46K Followers 1K Following AI Developer Experience @GoogleDeepMind | prev: Tech Lead at @huggingface, AWS ML Hero 🤗 Sharing my own views and AI News 🧑🏻💻 https://t.co/7IosdlNz22
OpenMMLab @OpenMMLab
6K Followers 132 Following From MMDetection to AI Exploration. Empowering AI research and development with OpenMMLab. Discord:https://t.co/BWaz5KtF5e
João Gante @joao_gante
3K Followers 628 Following ML @huggingface 🤗, making text generation users happy. 🇵🇹
Woosuk Kwon @woosuk_k
6K Followers 628 Following @thinkymachines | @vllm_project | PhD-ing @Berkeley_EECS
Jeffrey Wang @jeffreygwang
5K Followers 1K Following Researcher @OpenAI, working on pretraining & reasoning. Previously (and perhaps again) CS/Math/English @Harvard.
Sharon Zhou @realSharonZhou
25K Followers 0 Following Building & teaching AI | VP of AI, @AMD | Prev: Founder & CEO, Lamini. CS Faculty & PhD @Stanford. @Google. @Harvard | @MIT 35 under 35. Angel investor.
Feng Liu @AlexFengLiu1
438 Followers 572 Following Machine Learning Researcher | Senior Lecturer (US Associate Professor) @UniMelb. Visiting Scientist @RIKEN_AIP_EN. Focusing on Statistical Trustworthy ML.
Selene Horiuchi @selenemiyu
574 Followers 247 Following Founder @CrackedFounders | COO @ Capy | Toyota Full-Ride Scholar, 3D Food printing stuff
Jason Lee @jasondeanlee
18K Followers 4K Following Associate Professor at UC Berkeley. Former Research Scientist at Google DeepMind. ML/AI Researcher working on foundations of LLMs and deep learning.
Barret Zoph @barret_zoph
22K Followers 1K Following CTO & Co-Founder Thinking Machines Lab (@thinkymachines) Past: - VP Research (Post-Training) @openai - Research Scientist at Google Brain
Joe Fioti @joefioti
2K Followers 372 Following it's not possible, it's necessary. building a compiler @luminal_ai to make models go really fast.
richard @richardzphotoz
17K Followers 2K Following 18, tech media | prev. @forbesweb3 @cluely @joinaviato
Arpit Bhayani @arpit_bhayani
100K Followers 1K Following databases • staff engg @googlecloud memorystore (prev dataproc, ads) • creator @TheDiceDB • sold @profile_fyi, prev @unacademy, amazon
Nano Banana @NanoBanana
44K Followers 1 Following Nano Banana 🍌 the world's most powerful image editing and generation model! Try it for free in the @GeminiApp



Damek @damekdavis
6K Followers 1K Following Optimization and ML, Prof @Wharton Stats, Prev: Prof @Cornell, PhD @uclamath, https://t.co/bfOIEx0lHj, (not quite a) blog: https://t.co/RFKUB4qDKF

Nadav Timor @NadavTimor
1K Followers 8K Following AI inference, speculative decoding, open source. Built novel decoding algorithms – default in Hugging Face Transformers (150+ ⭐). Making AI faster + cheaper
Mike Bilodeau @mj_bilodeau
697 Followers 547 Following Time and Tide | Telling AI Stories @Basetenco
Jiantao Jiao @JiantaoJ
2K Followers 124 Following Director of Research & Distinguished Scientist at @NVIDIA, Professor at UC Berkeley EECS and Statistics. Building AGI/ASI
Aleksa Gordić (水�... @gordic_aleksa
26K Followers 229 Following getting us to singularity with friends computers can be understood: https://t.co/doHE1Qv2Sj x @GoogleDeepMind @Microsoft tensor core maximalist
NVIDIA AI Developer @NVIDIAAIDev
83K Followers 324 Following All things AI for developers from @NVIDIA. Additional developer channels: @NVIDIADeveloper, @NVIDIAHPCDev, and @NVIDIAGameDev.
Unsloth AI @UnslothAI
32K Followers 459 Following Open source LLM fine-tuning & RL! 🦥 https://t.co/2kXqhhvLsb
Daniel Han @danielhanchen
28K Followers 2K Following Building @UnslothAI. Faster RL / training. LLMs bug hunter. OSS package https://t.co/aRyAAgKOR7. YC S24. Prev ML at NVIDIA. Hyperlearn used by NASA.

Rohan Varma @rvarm1
1K Followers 486 Following Research Eng @ @jumptrading | prev @ Meta Superintelligence, @PyTorch
Alex Zhang @a1zhang
13K Followers 598 Following phd student @MIT_CSAIL, ugrad @Princeton, 🫵🏻 go participate in the @GPU_MODE kernel competitions!
Julia Turc @juliarturc
5K Followers 443 Following Explaining AI on YouTube • YC S24 Founder • Ex-Google Research • Eastern-European nihilist & American optimist
Sewon Min @sewon__min
14K Followers 819 Following Assistant professor @Berkeley_EECS @berkeley_ai || Research scientist at @allen_ai || PhD from @uwcse @uwnlp
Hieu Pham @hyhieu226
34K Followers 25 Following @openai | ex: @xai, @augmentcode, @GoogleBrain, @LTIatCMU, @Stanford, ACM ICPC, IMO🥈 Opinions are my own.

Asuka🎀Redpanda @VoidAsuka
20K Followers 4K Following senior sde, junior ai research enginee, backed by God. share something useful or fun.
Susan Zhang @suchenzang
34K Followers 680 Following @ Google Deepmind. Past: @MetaAI, @OpenAI, @unitygames, @losalamosnatlab, @Princeton etc. Always hungry for intelligence.
Emmanuel Ameisen @mlpowered
10K Followers 236 Following Interpretability/Finetuning @AnthropicAI Previously: Staff ML Engineer @stripe, Wrote BMLPA by @OReillyMedia, Head of AI at @InsightFellows, ML @Zipcar
Joshua Batson @thebasepoint
4K Followers 675 Following trying to understand evolved systems (🖥 and 🧬) interpretability research @anthropicai formerly @czbiohub, @mit math
Ai2 @allen_ai
74K Followers 410 Following Breakthrough AI to solve the world's biggest problems. › Join us: https://t.co/MjUpZpKPXJ › Newsletter: https://t.co/k9gGznstwj
Joelle Pineau @jpineau1
15K Followers 446 Following Chief AI Officer, @cohere Professor of Computer Science, @mcgillu Core academic member, @Mila_Quebec Ex-Meta (FAIR team)
Max ⛅ @maxisawesome538
3K Followers 3K Following sup nerds @DbrxMosaicAI @CohereForAI @SF_Battery @maxdoesresearch for purely research tweetsTrends for United States
You might like



















