
Lorenz Kuhn @_lorenzkuhn
Reasoning Research @OpenAI | o1-preview through o3 Joined January 2014-
Tweets248
-
Followers1K
-
Following746
-
Likes964

1/n I’m really excited to share that our @OpenAI reasoning system got a perfect score of 12/12 during the 2025 ICPC World Finals, the premier collegiate programming competition where top university teams from around the world solve complex algorithmic problems. This would have…

IMO gold is a win for scaling ~nearly~ superhuman oversight on a fuzzy, hard-to-verify RL domain
IMO gold is a win for scaling ~nearly~ superhuman oversight on a fuzzy, hard-to-verify RL domain




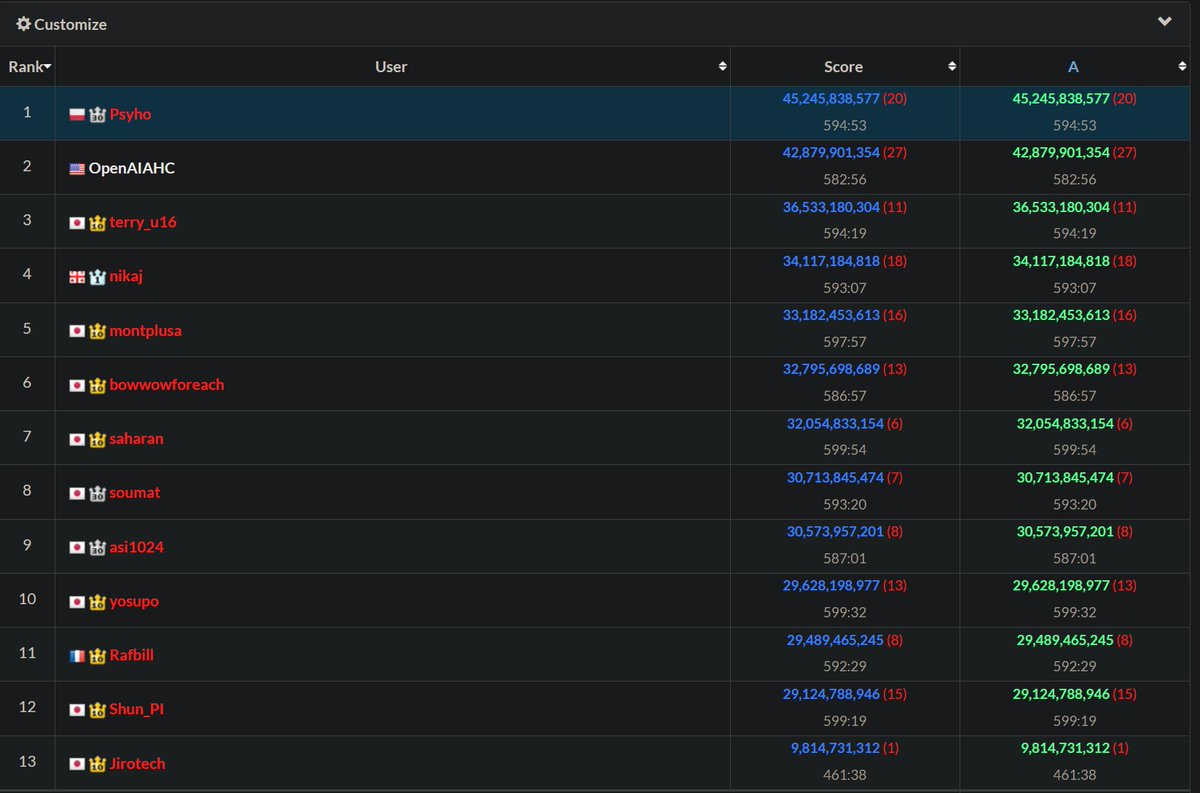
It was thrilling to watch AI compete against some of the best human competitive programmers at AtCoder World Finals Heuristics yesterday. Check out @andresnds ‘s thread on how the AI solutions improved throughout the 10h contest. Congrats to @FakePsyho on 1st place!
It was thrilling to watch AI compete against some of the best human competitive programmers at AtCoder World Finals Heuristics yesterday. Check out @andresnds ‘s thread on how the AI solutions improved throughout the 10h contest. Congrats to @FakePsyho on 1st place!


Congratulations @FakePsyho on a nail-biting performance! Great showings as well from @bminaiev, @andresnds, and @_lorenzkuhn representing OpenAI. It’s been fantastic sponsoring AtCoder World Finals @atcoder. We’re excited to share some of the model solutions with the world.

Congratulations @FakePsyho on a nail-biting performance! Great showings as well from @bminaiev, @andresnds, and @_lorenzkuhn representing OpenAI. It’s been fantastic sponsoring AtCoder World Finals @atcoder. We’re excited to share some of the model solutions with the world.
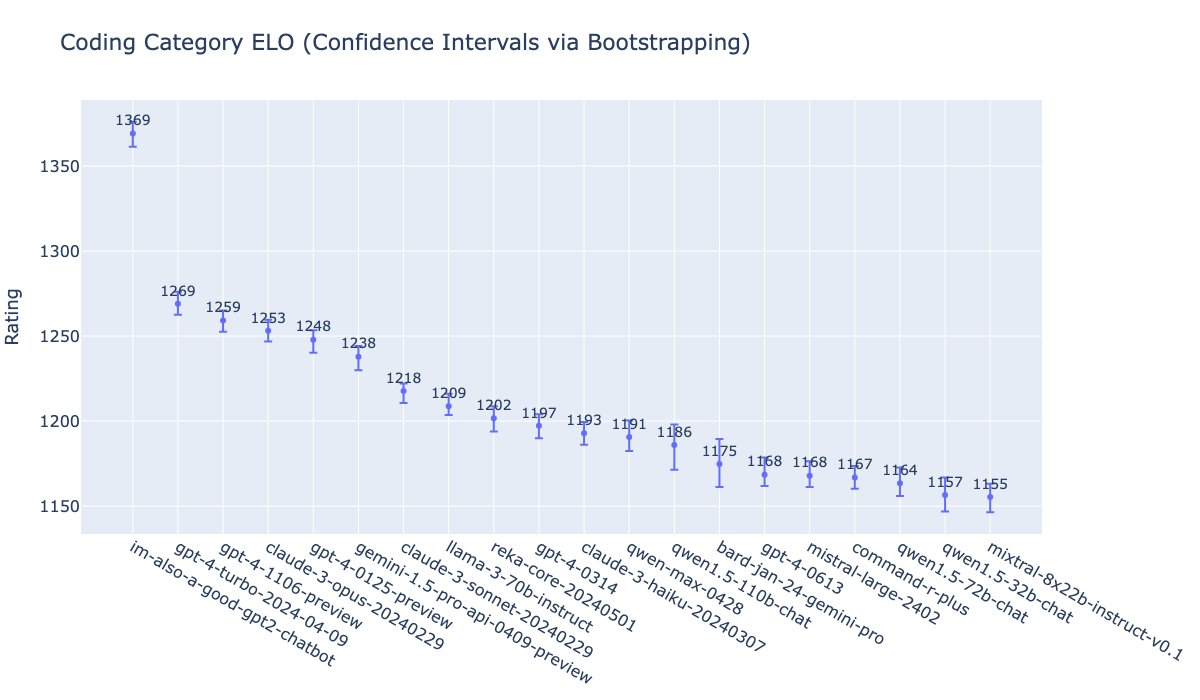
Two important points from our new technical report: 1. Scaling continues to work and the bitter lesson still holds 2. Recent AI models are strong at reasoning tasks and are rapidly becoming stronger — 4o was released less than a year ago, o1 less than six months ago
Two important points from our new technical report: 1. Scaling continues to work and the bitter lesson still holds 2. Recent AI models are strong at reasoning tasks and are rapidly becoming stronger — 4o was released less than a year ago, o1 less than six months ago


i generally feel super grateful that i get to work with such exceptionally skilled and kind people on reasoning research. the sprint for IOI in particular was special though. IOI 2024 gold @ 10k submissions; 49th percentile of competitors under real contest conditions

i generally feel super grateful that i get to work with such exceptionally skilled and kind people on reasoning research. the sprint for IOI in particular was special though. IOI 2024 gold @ 10k submissions; 49th percentile of competitors under real contest conditions
Today, I’m excited to share with you all the fruit of our effort at @OpenAI to create AI models capable of truly general reasoning: OpenAI's new o1 model series! (aka 🍓) Let me explain 🧵 1/

very excited about these models helping people solve hard problems and proud of the work we did. give the new models a try!

very excited about these models helping people solve hard problems and proud of the work we did. give the new models a try!
We trained a model and it is good in some things
But the ELO can ultimately become bounded by the difficulty of the prompts (i.e. can’t achieve arbitrarily high win rates on the prompt: “what’s up”). We find on harder prompt sets — and in particular coding — there is an even larger gap: GPT-4o achieves a +100 ELO over our prior…

Excellent post by @JacobSteinhardt trying to forecast the abilities of models that could be trained in 2030: bounded-regret.ghost.io/what-will-gpt-…
new preprint "ReLU to the Rescue: Improve your On-policy Actor-Critic with Positive Advantages" shockingly simple changes to A3C can give a cautious RL algorithm more effective than PPO in some settings, just adding a ReLU is enough! arxiv.org/abs/2306.01460


The Google DeepMind alignment team is looking for research scientists and research engineers to help us work towards safe AGI. I think this is a very pressing problem, and it's a nice place to work. Please apply and help take our work to the next level. boards.greenhouse.io/deepmind/jobs/…

With more powerful AI systems comes more responsibility to identify novel capabilities in models. 🔍 Our new research looks at evaluating future 𝘦𝘹𝘵𝘳𝘦𝘮𝘦 risks, which may cause harm through misuse or misalignment. Here’s a snapshot of the work. 🧵 dpmd.ai/novel-ai-risks

Mike Downey @mdowney
4K Followers 714 Following Product Leader. Built products at Microsoft, Adobe, Macromedia. Building now at DICK’s Sporting Goods. Tweets do not represent views of my employer.
e @e776675411527
0 Followers 124 Following

lori Mike @loriMike37298
7 Followers 1K Following
Kyle Marieb @kylemarieb
1K Followers 8K Following Profoundly deaf with cochlear implants 🦻🤖 YouTube Backend SWE 📺
Manqi Cai @Ccccmk88
1 Followers 124 Following

joey @Joey_dreame
4 Followers 295 Following

Jiale Chen @jialec00
2 Followers 74 Following 3rd-year PhD @ Stanford Algorithm design and analysis with a current focus on matching algorithms in various settings.

Tomasz Sternal @TomaszSternal
9 Followers 414 Following
Bala Subramanian @Bala2462000
70 Followers 2K Following


Anastasia Zik @nastiazik
3K Followers 420 Following Building and growing startups & helping others do the same
John @JohnKingJrLead
32 Followers 494 Following
Marco Salvi @marcosalvi
6K Followers 6K Following Computationally responsible deep learning and real-time graphics research @ NVIDIA. Personal opinions only.
Azad Md Abul Kalam @_akazad
80 Followers 664 Following PhD student, Computer and Information Science
Jasmine Arnold @jaydipsimh
157 Followers 327 Following CFP\IMC Proud American 🇱🇷 Great Supporter of Trump, Because he always says the truth. #Trump2024
vasudev anubrolu @vasudevanubrolu
92 Followers 2K Following ML enthusiast, Engineer. Sr. SE @koredotai. ex @deloitte @vmware. @bitspilaniindia 2015-20.
Kuang Lin @_Kuang_Lin
18 Followers 294 Following
Phill @Laz42
198 Followers 3K Following
Andrew Greene @agreene1818
41 Followers 1K Following
Shy Suspect @ShySuspect
5 Followers 326 Following

Jakub @AbrahamOdra
15 Followers 357 Following Mathematics and computer science enjoyer. Deep learning deep learning
GourdBoi @NereusZ
31 Followers 564 Following
Yuriy Kagan @YuriyKagan
94 Followers 1K Following Writer Product @Substack, previously @ScaleAI and @Facebook
Amadou Gueye Physika @APhysika
7 Followers 177 Following
Chris Klaus @cklaus1
3K Followers 5K Following CEO of Fusen. Connecting students with mentors, investors, and funding opportunities through our Fusen accelerators. @cklaus.bsky.social on Bluesky.
Son @dualboot404
19 Followers 835 Following 21 TOTAL RESTART. learning from base 0. trying to be useful
Khaled Rouissi @krouissi_
4 Followers 598 Following
Mihir Agarwal @mihir1710
11 Followers 102 Following Research Fellow @MSFTResearch | EE @IITGandhinagar
Oz @GencOzzie54171
6 Followers 426 Following
Syntax Studio @syntaxstudiodev
117 Followers 69 Following We are a digital agency that helps companies build digital products that advance industries.
Raymond Weitekamp @raw_works
885 Followers 2K Following building tools for builders | founder @polySpectra | cofounder @cyprismaterials | cohort 1 @activatefellows @berkeleylab | PhD @caltech | AB @princeton | #rwri


Todd Branchflower @toddbranch
492 Followers 2K Following Building Investing, Autos and Real Estate search @google. Former @usairforce officer.
aditya emmadishetty @adityaemmadish1
0 Followers 17 Following
Aditya Makkar @AdityaMakkar000
248 Followers 159 Following post-training & reasoning @cohere | CS @ uwaterloo
ARITRA KOLAY @AritraKola76666
39 Followers 680 Following
SophisticatedMorris @Pr50264329
7 Followers 265 Following Part-time software engineer, full-time shitposter
H @HasBeenWrong
93 Followers 1K Following ...and his remorse and better judgment arrives late, as usual!

Ahmad Beirami @abeirami
10K Followers 4K Following sth new // ex Gemini RL+Inference @GoogleDeepMind // Chat AI @Meta // RL Agents @EA // ML+Information Theory @MIT+@Harvard+@GeorgiaTech // زن زندگی آزادی


David Dohan @dmdohan
12K Followers 2K Following reducing perplexity @openai | past: probabilistic programs, proteins, science & reasoning @ google brain 🧠
Ishaan Singal @IshaanSingal
382 Followers 217 Following Research at @OpenAI. Hit me up for ice cream and/or coffee anytime.

Phillip Guo @phuguo
425 Followers 486 Following Preparedness researcher @ OpenAI. Previously jailbreak researcher @ Grayswan, trading intern @ Jane Street, robustness research @ MATS


Hanson Wang @hansonwng
754 Followers 277 Following @OpenAI Codex // previously cofounder @arcwisedata
Dan Roberts @danintheory
6K Followers 697 Following RL Scientist @OpenAI. Prev. co-founder @diffeo, acquired by @salesforce // co-authored The Principles of Deep Learning Theory // studied gravity.
will depue @willdepue
51K Followers 2K Following (taking time off) RL posttraining @openai, past: sora 1 & 2, applied research
Miles Wang @MilesKWang
3K Followers 1K Following Researcher @OpenAI. Beneficial and safe AGI. Prev @Harvard
Manas Joglekar @ManasJoglekar
248 Followers 289 Following
Santiago Hernández @santiaghini
2K Followers 2K Following 1% smarter (models) every day. reasoning @openai. retired child actor
Aaditya Singh @Aaditya6284
820 Followers 345 Following Doing a PhD @GatsbyUCL with @SaxeLab, @FelixHill84 on learning dynamics, ICL, LLMs. Prev. at: @GoogleDeepMind, @AIatMeta (LLaMa 3), @MIT. https://t.co/ZOmBWCvbIK


Jerry Tworek @MillionInt
23K Followers 702 Following Berry farmer @ OpenAI | o3, o1, GPT4, ChatGPT, Codex, Solved Rubik’s cube with robotic hand | cautious AI optimist



Ashvin Nair @ashvinair
1K Followers 3K Following Research scientist working on RL @openai. Prev: 9 years learning to poke by poking at UC Berkeley
Andre Saraiva @andresnds
3K Followers 140 Following o1-preview, o1-mini, o1, o3-mini,o4-mini, o3... Reasoning Researcher at OpenAI. Ex-DeepMind.


Hongyu Ren @ren_hongyu
23K Followers 693 Following research @meta superintelligence. CS PhD @stanford. prev @openai, led the development of o3-mini and o1-mini.
Chelsea Sierra Voss @csvoss
12K Followers 1K Following currently in nyc! engineeress ✨ Member of Technical Staff @openai. serious play // notice your curiosity
Scott Gray @scottgray76
9K Followers 794 Following GPU Geek at @OpenAI. I have a long standing interest in neuroscience and its application to machine learning. He/Him.
Alexander Wei @alexwei_
24K Followers 195 Following Reasoning @OpenAI. Co-built CICERO @MetaAI | @Berkeley_AI PhD '23 | @Harvard '20
Gilbert Strang @GilStrangMIT
7K Followers 20 Following Professor of Mathematics @MIT | PhD @UCLA | Linear Algebra Wizard | parody
Noam Brown @polynoamial
92K Followers 860 Following Researching reasoning @OpenAI | Co-created Libratus/Pluribus superhuman poker AIs, CICERO Diplomacy AI, and OpenAI o3 / o1 / 🍓 reasoning models
Nat McAleese @__nmca__
15K Followers 358 Following Research @AnthropicAI. Previously @OpenAI, @DeepMind. Views my own.
Conor Nolan @conor_draws
57K Followers 875 Following Freelance illustrator and comic artist. (he/him) https://t.co/UfM4oSFXYs
Lisa Wehden @lisawehden
19K Followers 117 Following building @plymouthstreet — fast U.S. work visas for technologists | @sequoia scout | @join_ef @oxfordunion immigrant 🇬🇧🇩🇿🇺🇸
chokudai(高橋 直�... @chokudai
64K Followers 16K Following 競技プログラミングの会社の社長です! AtCoder(株)代表取締役社長/競プロ世界ランカー(GoogleHashCode優勝、ICFPC優勝7回等)/たこやき/ぷよぷよ/ブルアカ(ホシノ推し)/チュウニズム虹レ/筑駒中高→慶應SFC卒/NewsPicksプロピッカー/sub:@chokudai_s

Eric @ericmitchellai
9K Followers 562 Following co-lead @openai post-training frontiers team w/ the great @yanndubs; I like ai and music and some other things
Robin @Ro_slash_bin
10 Followers 192 Following

Yo Shavit @yonashav
7K Followers 964 Following policy for v smart things @openai. Past: CS PhD @HarvardSEAS/@SchmidtFutures/@MIT_CSAIL. Tweets my own; on my head be it.
Niklas Stoehr @niklas_stoehr
1K Followers 785 Following Research Scientist @GoogleDeepMind and PhD from @ETH ⭕️ Gemini Post-Training ⭕️
Clare Lyle @clarelyle
3K Followers 444 Following RL researcher who sometimes blogs at https://t.co/aqIlg3lANW. Formerly @OATML_Oxford, now DeepMind.
Lawrence H. Summers @LHSummers
375K Followers 712 Following Charles W. Eliot University Professor and President Emeritus at Harvard. Secretary of the Treasury for President Clinton and Director of NEC for President Obama
William Fedus @LiamFedus
29K Followers 1K Following Co-Founder of @periodiclabs Past: VP of Post-Training @OpenAI; Google Brain
Sholto Douglas @_sholtodouglas
28K Followers 2K Following Scaling RL @AnthropicAI, ex @DeepMind - working towards intelligence too cheap to meter
Joshua Achiam @jachiam0
22K Followers 1K Following Freedom, flourishing, and abundance. Head of Mission Alignment at @openai. Main author of https://t.co/cKuSh21yaz


Scott Johnston @wampiter
19 Followers 104 Following


Alexis Conneau @alex_conneau
35K Followers 190 Following Co-founder and CEO https://t.co/efv72CKpAG (@WaveFormsAI) - Ex @OpenAI GPT-4o/AVM Audio Research Lead - #Her #TARS - Ex @AIatMeta, @Polytechnique (X11)Trends for United States
You might like














