-
Tweets92
-
Followers362
-
Following417
-
Likes2K

1/What does it mean for an LLM to “memorize” a doc? Exactly regurgitating a NYT article? Of course. Just training on NYT?Harder to say We take big strides in this discourse w/*Adversarial Compression* w/@A_v_i__S @zhilifeng @zacharylipton @zicokolter 🌐:locuslab.github.io/acr-memorizati…🧵

1/Let me tell you the dark secrets 🔮 behind developing *new* scaling laws that no one wants you to know. A tale of “Another day. Another (failed) Scaling Law”. Working through key design decisions, limited compute, and other difficulties🧵.
1/Let me tell you the dark secrets 🔮 behind developing *new* scaling laws that no one wants you to know. A tale of “Another day. Another (failed) Scaling Law”. Working through key design decisions, limited compute, and other difficulties🧵. https://t.co/5WoDSbmJsD
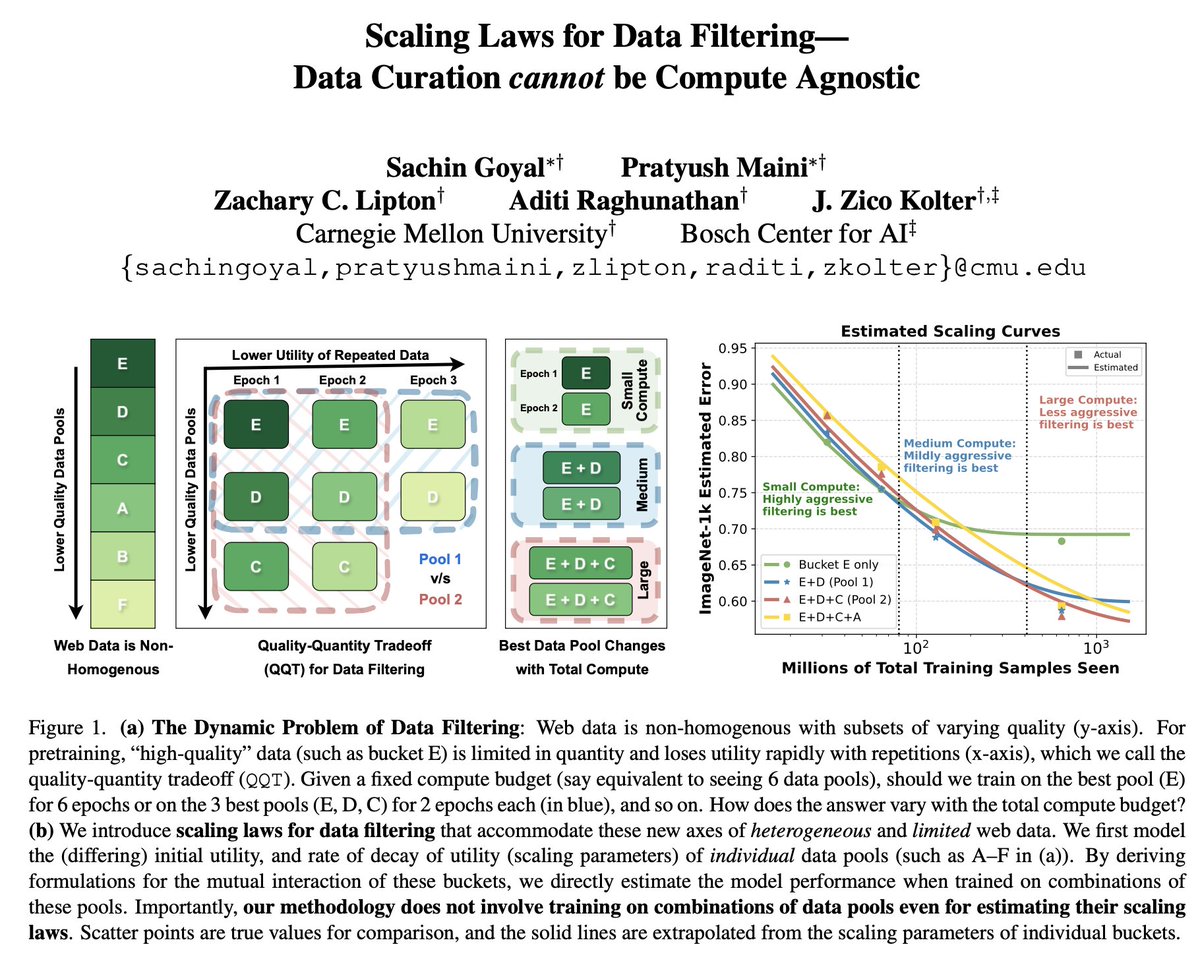
1/ 🥁Scaling Laws for Data Filtering 🥁 TLDR: Data Curation *cannot* be compute agnostic! In our #CVPR2024 paper, we develop the first scaling laws for heterogeneous & limited web data. w/@goyalsachin007 @zacharylipton @AdtRaghunathan @zicokolter 📝:arxiv.org/abs/2404.07177

Models with different randomness make different predictions at test time even if they are trained on the same data. In our latest ICLR paper (oral), we investigate how models learn different features, and the effect this has on agreement and (potentially) calibration. 1/


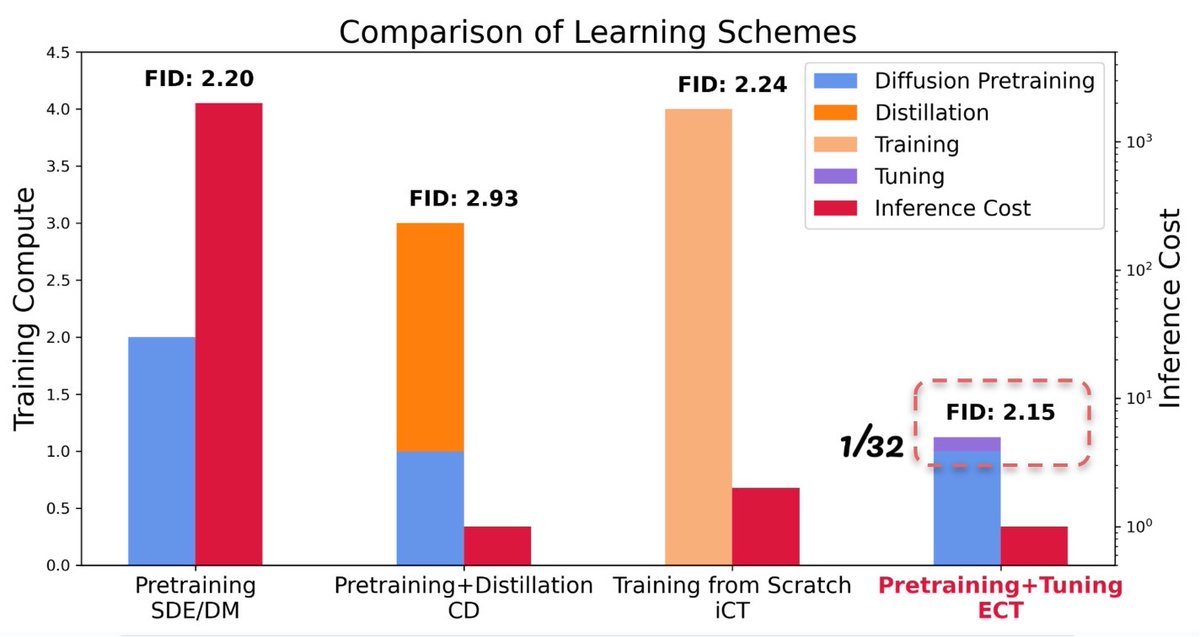
🚀Our latest blog post unveils the power of Consistency Models and introduces Easy Consistency Tuning (ECT), a new way to fine-tune pretrained diffusion models to consistency models. SoTA fast generative models using 1/32 training cost! 🔽 Get ready to speed up your generative…

Do LLMs really need to be so L? That's a rejected title for a new paper w/ @Andr3yGR, @kushal_tirumala, @Hasan_Shap, @PaoloGlorioso1 on pruning open-weight LLMs: we can remove up to *half* the layers of Llama-2 70B w/ essentially no impact on performance on QA benchmarks. 1/


Joint work with Kaiming He Check the paper for more! (non-)code: github.com/liuzhuang13/bi… arxiv: arxiv.org/abs/2403.08632 (Answer to the game: YFCC: 1, 4, 7, 10, 13; CC: 2, 5, 8, 11, 14; DataComp: 3, 6, 9, 12, 15)
Very excited to share one of the most interesting projects I've ever worked on, but first, a small game: Here are 15 images from three of the largest and most diverse modern image datasets: YFCC100M, CC12M and DataComp-1B. Can you guess which images are from which datasets?

Fascinating and insightful work from @_mingjiesun @liuzhuang1234, took a much deeper look at the "massive activations" inside LLMs, proposing hypothesis and verified them as "biases" for attention, and they can appear in ViTs too!
Fascinating and insightful work from @_mingjiesun @liuzhuang1234, took a much deeper look at the "massive activations" inside LLMs, proposing hypothesis and verified them as "biases" for attention, and they can appear in ViTs too!

LLMs are great, but their internals are less explored. I'm excited to share very interesting findings in paper “Massive Activations in Large Language Models” LLMs have very few internal activations with drastically outsized magnitudes, e.g., 100,000x larger than others. (1/n)
Diffusion models have achieved remarkable results in visual generation. We demonstrate it can also generate neural networks parameters, in our new paper: "Neural Network Diffusion" (1/n) x.com/_akhaliq/statu…

Diffusion models have achieved remarkable results in visual generation. We demonstrate it can also generate neural networks parameters, in our new paper: "Neural Network Diffusion" (1/n) x.com/_akhaliq/statu…
Unlabeled data is crucial for modern ML. It provides info about data distribution P, but how to exploit such info? Given a kernel K, our #ICLR2024 spotlight gives a general & principled way: Spectrally Transformed Kernel Regression (STKR). Camera-ready 👇 arxiv.org/abs/2402.00645
1/7 Super excited about my Apple Internship work finally coming out: Rephrasing the Web: A Recipe for Compute and Data-Efficient Language Modeling TLDR: You can train 3x faster and with upto 10x lesser data with just synthetic rephrases of the web! 📝 arxiv.org/abs/2401.16380

Apple presents Rephrasing the Web A Recipe for Compute and Data-Efficient Language Modeling paper page: huggingface.co/papers/2401.16… Large language models are trained on massive scrapes of the web, which are often unstructured, noisy, and poorly phrased. Current scaling laws show…

Diffusion models can do more than generation. Check out our new work on analyzing what's useful in diffusion models for visual representation learning! @endernewton @sainingxie
Diffusion models can do more than generation. Check out our new work on analyzing what's useful in diffusion models for visual representation learning! @endernewton @sainingxie

1/4 The Right to be Forgotten is knocking on the door. Yet, unlearning in LLMs has no clear task definition, no evaluation metrics or baselines. Introducing TOFU: Task of Fictitious Unlearning for LLMs 🌐 locuslab.github.io/tofu w/@A_v_i__S @zhilifeng @zacharylipton @zicokolter🧵

CMU presents TOFU A Task of Fictitious Unlearning for LLMs paper page: huggingface.co/papers/2401.06… Large language models trained on massive corpora of data from the web can memorize and reproduce sensitive or private data raising both legal and ethical concerns. Unlearning, or…

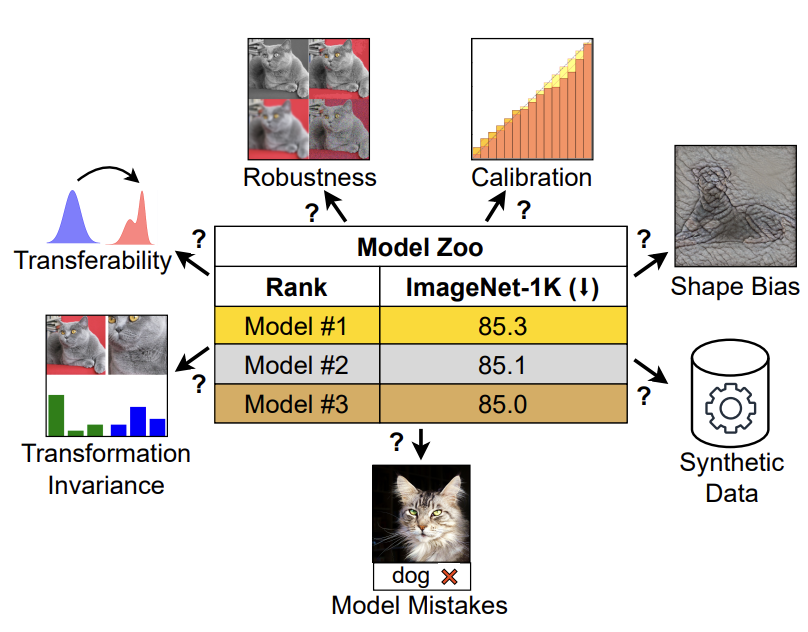
How to choose a vision model for your specific needs? How do ConvNet / ViT, supervised / CLIP models compare with each other on metrics beyond ImageNet? Our work comprehensively compares common vision models on "non-standard" metrics. (1/n)

Now that at NeurIPS is upon us shortly ... it's time to start planning for ICML😀! Thrilled to serve with @kat_heller @adrian_weller @nuriaoliver as PCs, and @rsalakhu as general chair. Call for papers is here: icml.cc/Conferences/20… Intro blog post: medium.com/@icml2024pc/we…

Simone Torrecillas @TorrecillaSimo
80 Followers 5K Following
Mairead Ostermann @MaireadOst47192
61 Followers 5K Following
Shesath @Shesath112966
0 Followers 123 Following Life itself is a journey, we are all worthy and should strive to travel to different lives.

Shaniqua Champeau @ShaniquChamp
75 Followers 5K Following
Melany Lopresto @LoprestoMe67565
55 Followers 5K Following
Flora Cardino @CardinoCardi
84 Followers 5K Following
Cecilia Donnan @CeciliaDon22588
52 Followers 5K Following
Van Sanipasi @VSanipasi87447
86 Followers 5K Following


Tianjian Li @tli104
137 Followers 267 Following phd student @jhuclsp, working on data engineering for language models.
Joe Rocca @rocca27
175 Followers 2K Following ml ∩ web ∩ vr, housing, social coordination, stable interfaces, alt proteins, wild animal suffering, ageing, etc

Daina Meisel @daina_mei
63 Followers 5K Following
Jeannette Brightman @JBrightm
26 Followers 5K Following
Livi Hamelinck @LHamelinck94261
80 Followers 5K Following
Saqib Azim @_saqib1707
62 Followers 853 Following @UCSanDiego | @Hitachi_Japan | @samsungresearch | @iitbombay | AI (machine learning, robot learning & computer vision) | Retweets are not endorsements
Jemma Buechner @BuechnerJe50639
19 Followers 3K Following

Sage Knochel @SaKnoche
75 Followers 5K Following

Mir Arfeen Hussain @MiArfeen56
134 Followers 4K Following Just received some exciting news and I can't wait to share it with everyone! Stay tuned for updates. 🎉✨
Keshav Ramji @KeshavRamji
75 Followers 325 Following BS/MS Student @CIS_Penn and @Wharton | AI Intern @IBMResearch
Karush Suri @karush_
405 Followers 670 Following Meta Learner @Theteamatx in @GoogleAI swimmer & comic fan Past @borealisai @eceuoft

Hilda Lacrosse @lacros_hi
49 Followers 5K Following
Lula Mirick @LulaMiric
47 Followers 5K Following
Ariel Larocca @LaroccAri
81 Followers 5K Following
Keila Brandeland @KBrandelan30091
52 Followers 5K Following
GPT Maestro @GptMaestro
61 Followers 388 Following curator of the LLMpedia (Illustrated Large Language Model Encyclopedia)

Blessing Kriege @BlessiKrie
43 Followers 5K Following

Brandy Frisbie @BraFrisbi
71 Followers 5K Following
Latisha Mcpheeters @LatishaMcp16214
67 Followers 5K Following
Christina Fogal @ChristinFog
29 Followers 5K Following
Mairi Beeman @BeemanMair84101
60 Followers 5K Following



Jeanine Schwarzenbach @jeanine_jeani
57 Followers 5K Following
Sahar Truby @tr_saha
53 Followers 5K Following
zhuai @guo0914
66 Followers 270 Following

Milin Bhade @MilinBhade
56 Followers 1K Following Post Grad Student at IISc, Bangalore Masters in Computer Science & Automation
Jiahao Wang @JiahaoWANG48297
0 Followers 24 Following
Yu Bai @yubai01
3K Followers 2K Following Sr Research Scientist @SFResearch. PhD @Stanford. Researcher on foundation models, RL/games, deep learning, uncertainty quantification, and their theory.
Ethan Mollick @emollick
211K Followers 551 Following Professor @Wharton studying AI, innovation & startups. Democratizing education using tech Book: https://t.co/CSmipbJ2jV Substack: https://t.co/UIBhxu4bgq
Philipp Schmid @_philschmid
16K Followers 651 Following Tech Lead and LLMs at @huggingface 👨🏻💻 🤗 AWS ML Hero 🦸🏻 | Cloud & ML enthusiast | 📍Nuremberg | 🇩🇪 https://t.co/l1ppq3q3hk
Laurens van der Maate.. @lvdmaaten
653 Followers 1K Following Distinguished Research Scientist at Meta AI. t-SNE. DenseNet. Web-scale weakly supervised vision. CrypTen. Currently herding Llamas.
/MachineLearning @slashML
121K Followers 1 Following
François Fleuret @francoisfleuret
31K Followers 456 Following Prof. @Unige_en, Adjunct Prof. @EPFL_en, Research Fellow @idiap_ch, co-founder @nc_shape. AI and machine learning since 1994. I like reality.
Simo Ryu @cloneofsimo
3K Followers 383 Following #KAIST RAI Lab (ML engineering #Naver) Interested in robotics, RL, math (but you might know me for t2i diffusion) [email protected]
Sam Whitmore @sjwhitmore
12K Followers 2K Following building @newcomputer. not a cat (or a man) in real life. I like to run a lot! @kensho @harvard @StuyNY
Karush Suri @karush_
405 Followers 670 Following Meta Learner @Theteamatx in @GoogleAI swimmer & comic fan Past @borealisai @eceuoft
Burny — Effective O.. @burny_tech
14K Followers 6K Following Transhuman engineer in singularity! Lover of AI & omnidisciplionary metamathemagics! Hypercuriousia! Omniperspectivity! Shapeshifting metafluid! Freedom 4 all!
Microsoft Research @MSFTResearch
553K Followers 2K Following We advance science and technology to benefit humanity. https://t.co/kz0nARXbwT Register for Microsoft Research Forum on June 4 ⬇️ Get our newsletter
xAI @xai
997K Followers 36 Following
Jonathan Frankle @jefrankle
16K Followers 685 Following Chief Scientist, Neural Networks @Databricks via MosaicML. PhD @MIT_CSAIL. BS/MS @PrincetonCS. DC area native. Making AI efficient for everyone at @DbrxMosaicAI
AI Breakfast @AiBreakfast
167K Followers 209 Following The latest rumors and developments in the world of artificial intelligence. DM to include your AI project in the newsletter.

Nancy Pelosi Stock Tr.. @PelosiTracker_
560K Followers 223 Following Highlighting Politicians' trades so we can invest alongside Goal: get them banned from trading Powered by @joinautopilot_
VALORANT Leaks & News @VALORANTLeaksEN
333K Followers 46 Following Content Creator // #VALORANT Contact: [email protected] Backup account: @valorantleaksv2
Beth Kindig @Beth_Kindig
130K Followers 5K Following Investor with higher returns than Wall Street's Old Boys Club. Audited portfolio, automated hedge and free weekly analysis.
Evan @StockMKTNewz
420K Followers 384 Following Free Stock Market News that is FAST, ACCURATE, CONSISTENT, and RELIABLE | Not Just Stock News | Check out my Linktree ⬇️
Andrei Bursuc @abursuc
7K Followers 1K Following Research scientist @valeoai | Teaching @Polytechnique @ENS_ULM | Alumni @upb1818 @Mines_Paris @Inria @ENS_ULM

Chuang Gan @gan_chuang
4K Followers 457 Following Faculty Member at UMass Amherst; Principal researcher at MIT-IBM Watson AI Lab; Homepage: https://t.co/oXP6pqXCpo

Jim Cramer @jimcramer
2.1M Followers 698 Following Host of @madmoneyoncnbc and I run the CNBC Investing Club. Follow along and join my mailing list at https://t.co/MiPnDUwQ8r…
sarah guo // convicti.. @saranormous
91K Followers 3K Following startup investor and builder, founder @w_conviction. accelerating AI adoption, interested in progress. tech podcast: @nopriorspod
unusual_whales @unusual_whales
1.7M Followers 2K Following Stocks/Options/Crypto/Market News +Tools. Not advice 🐳 who changed 🏛️. Get $50-$5000 to trade: https://t.co/wGf2ZdlXpw Discord: https://t.co/0xJ9e0ZYYG More: https://t.co/nsxZlPV0pC
Yu Bai @yubai01
3K Followers 2K Following Sr Research Scientist @SFResearch. PhD @Stanford. Researcher on foundation models, RL/games, deep learning, uncertainty quantification, and their theory.

Tong Wu @TongWu_Pton
207 Followers 981 Following Princeton; Robust ML, Domain Adaptation; https://t.co/nZOwnTVXkM

Ekaterina Lobacheva @KateLobacheva
301 Followers 204 Following Independent Researcher, PhD in CS, Collaboration with https://t.co/tB7QL7Sw3a and https://t.co/JN95AWiNhB Like to explain unexpected behavior of neural nets 🤯
Gary Marcus @GaryMarcus
145K Followers 7K Following “A beacon of clarity”. Spoke at US Senate AI Oversight committee. Founder/CEO Geometric Intelligence (acq. by Uber). Rebooting AI & Taming Silicon Valley.
Anna Bair @annaebair
119 Followers 374 Following CMU PhD student in machine learning https://t.co/3vzZEGbXc4
Conference on Languag.. @COLM_conf
2K Followers 6 Following https://t.co/GhGCMEoa4A Abstract submission: March 22, 2024
Kirill Vishniakov @kirill_vish
80 Followers 367 Following AI Researcher @G42_Healthcare | prev MSc in Computer Vision at @mbzuai
trevordarrell @trevordarrell
2K Followers 127 Following EECS, BAIR, UC Berkeley. Director, BAIR Commons Program.
Micah Goldblum @micahgoldblum
5K Followers 690 Following 🤖Postdoc at NYU with @ylecun / @andrewgwils. All things machine learning🤖 🚨On the faculty job market this year!🚨
Jiawei Yang @JiaweiYang118
244 Followers 215 Following USC PhD student | Student Researcher@Google Researcher | ex-Intern @ Nvidia Research
Victor.Kai Wang @VictorKaiWang1
252 Followers 255 Following Ph.D. student at NUS, focus on data centric ai and its applications.
Jeremy Howard @jeremyphoward
222K Followers 5K Following 🇦🇺 Co-founder: @AnswerDotAI & @FastDotAI ; Hon Professor: @UQSchoolITEE ; Digital Fellow: @Stanford
Shenao Zhang @ShenaoZhang
274 Followers 964 Following PhD student @NorthwesternU | Student Researcher @MSFTResearch. Ex-intern @MSFTReserch, ByteDance, and Tencent AI | Previously @GeorgiaTech. LLM, RL, agent.
Kyla Scanlon @kylascan
168K Followers 918 Following wrote a book called "in this economy?" | (almost) daily economic videos | writing, podcast, and youtube 👻
Devendra Chaplot @dchaplot
8K Followers 365 Following Building next-gen AI at @MistralAI. Past: Research Scientist at Facebook AI Research. Ph.D. @SCSatCMU, BTech @iitbombay CS.
Alex Nichol @unixpickle
8K Followers 388 Following Code, AI, and 3D printing. Opinions are my own, not my computer's...for now. Husband of @thesamnichol. Co-creator of DALL-E 2. Researcher @openai.

Yangsibo Huang @YangsiboHuang
1K Followers 726 Following PhD candidate @Princeton. Prev: @GoogleAI @AIatMeta.
Brooke LeBlanc @brookeleblanc
20K Followers 1K Following Founder @joinedgeapp. 3.5 years sober. 9x half 3x marathon. Training for CHI NY ‘24
Sarah Frier @sarahfrier
84K Followers 2K Following In charge of big tech coverage at Bloomberg. Author of NO FILTER: The Inside Story of Instagram, from @simonschuster.
Cian Eastwood @CianEastwood
596 Followers 610 Following Machine learning PhD student @InfAtEd and @MPI_IS

Maggie Appleton @Mappletons
37K Followers 1K Following Design @elicitorg. Makes visual essays about UX, programming, and anthropology. Adores digital gardening 🌱, end-user development, and embodied cognition1/What does it mean for an LLM to “memorize” a doc? Exactly regurgitating a NYT article? Of course. Just training on NYT?Harder to say We take big strides in this discourse w/*Adversarial Compression* w/@A_v_i__S @zhilifeng @zacharylipton @zicokolter 🌐:locuslab.github.io/acr-memorizati…🧵

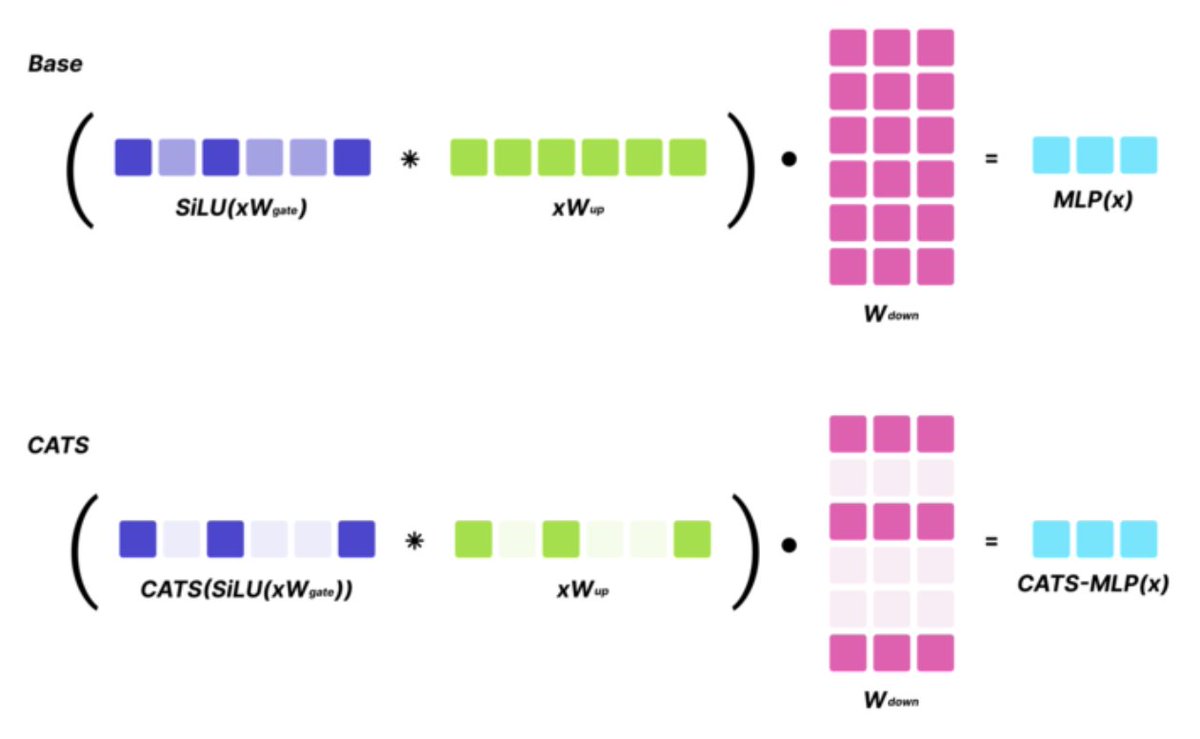
SoTA LLMs typically exhibit 99%+ non-zero activations, but it turns out that they are still intrinsically quite sparse! We introduce CATS, a simple post-training technique that achieves 50% activation sparsity for MLP layers with almost no drop in downstream evals, while…

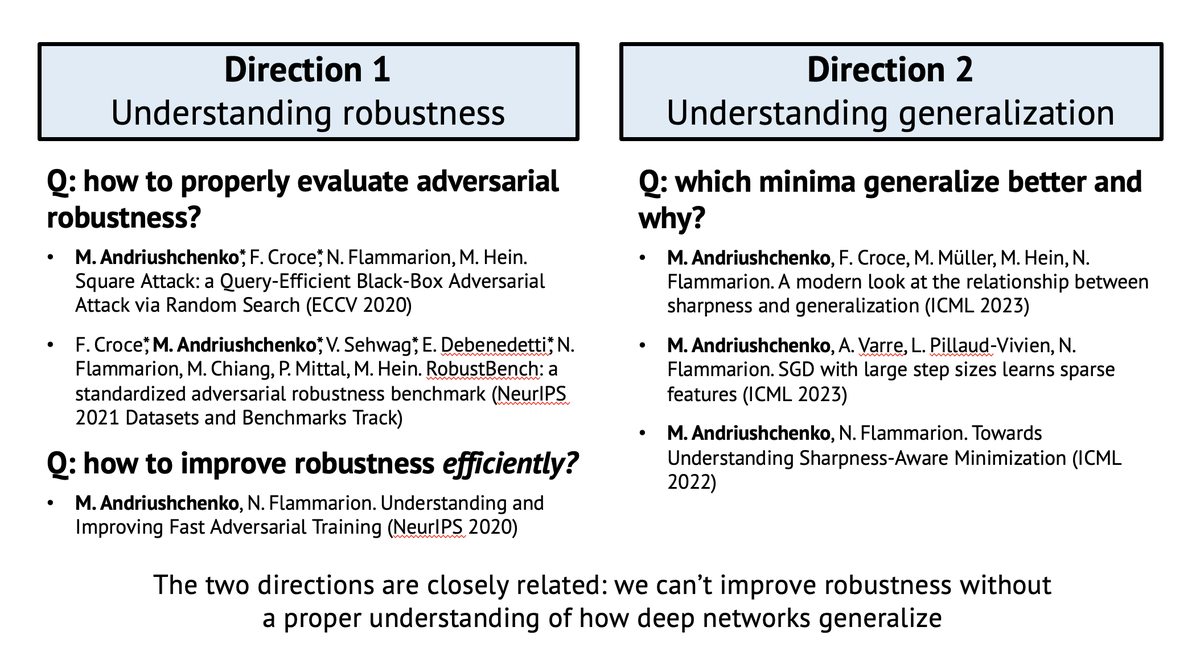
Super excited to share that I successfully defended my PhD thesis "Understanding Generalization and Robustness in Modern Deep Learning" today 👨🎓 A huge thanks to the thesis examiners @SebastienBubeck, @zicokolter, and @KrzakalaF, jury president Rachid Guerraoui, and, of course,…

What is blocking LLMs from allowing long context inputs? 🚨Introducing KVQuant which allows serving LLaMA-7B with 1M context length on a single A100! 🔥 Current largest model is Claude-2.1 which is limited to 200K tokens. What is the challenge for increasing this? Two key…


Llama 3 is about to be released with a 8B and a 70B models. Just saw this on Replicate: replicate.com/pricing


Coding is the frontier of AI. Excited to push the two frontiers of AI coding: 1. SWE(-bench/agent) 2. Olympiad programming (this tweet) Introduce USACO benchmark: * inference methods (RAG/reflect) help a bit: 9->20% * human feedback helps a lot: 0->86%! princeton-nlp.github.io/USACOBench/


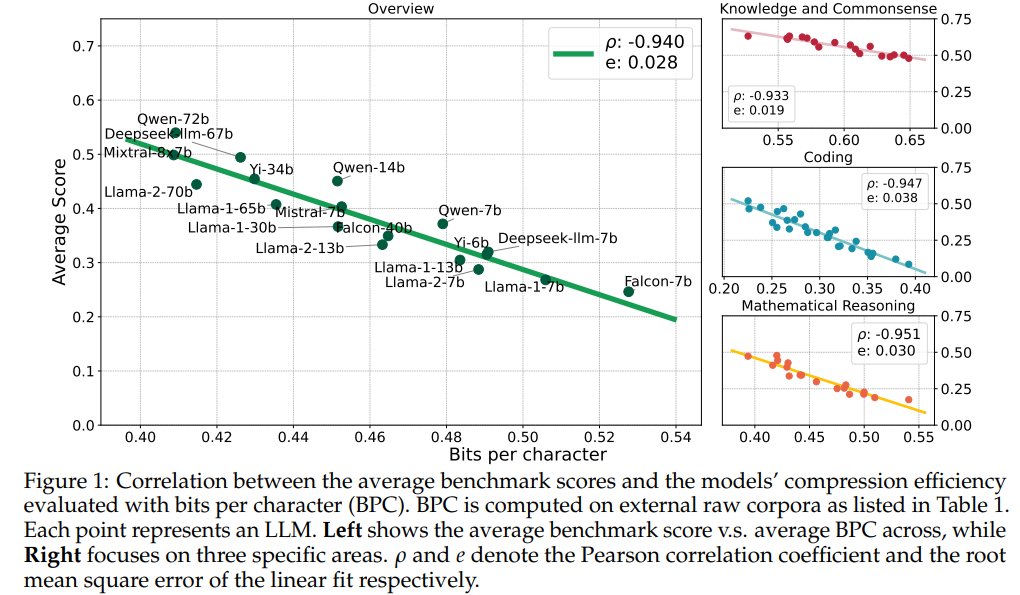
Compression Represents Intelligence Linearly LLMs' intelligence – reflected by average benchmark scores – almost linearly correlates with their ability to compress external text corpora repo: github.com/hkust-nlp/llm-… abs: arxiv.org/abs/2404.09937

A few new CUDA hacker friends joined the effort and now llm.c is only 2X slower than PyTorch (fp32, forward pass) compared to 4 days ago, when it was at 4.2X slower 📈 The biggest improvements were: - turn on TF32 (NVIDIA TensorFLoat-32) instead of FP32 for matmuls. This is a…
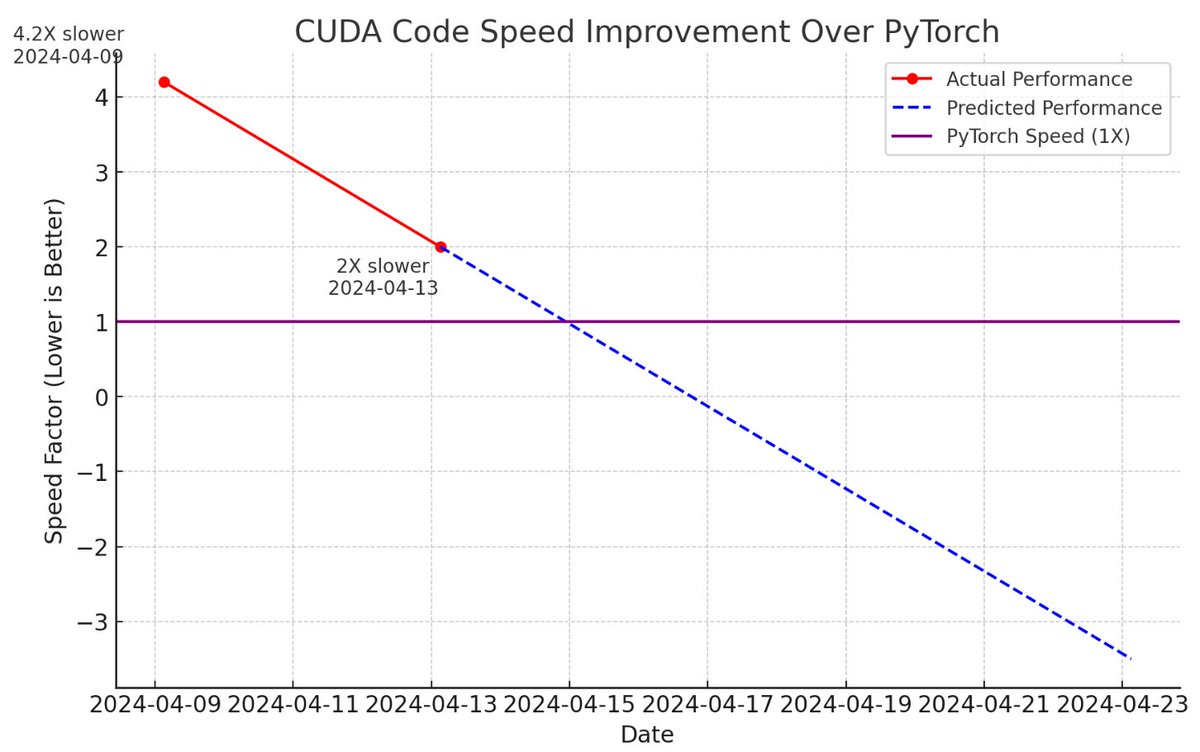
1/Let me tell you the dark secrets 🔮 behind developing *new* scaling laws that no one wants you to know. A tale of “Another day. Another (failed) Scaling Law”. Working through key design decisions, limited compute, and other difficulties🧵.
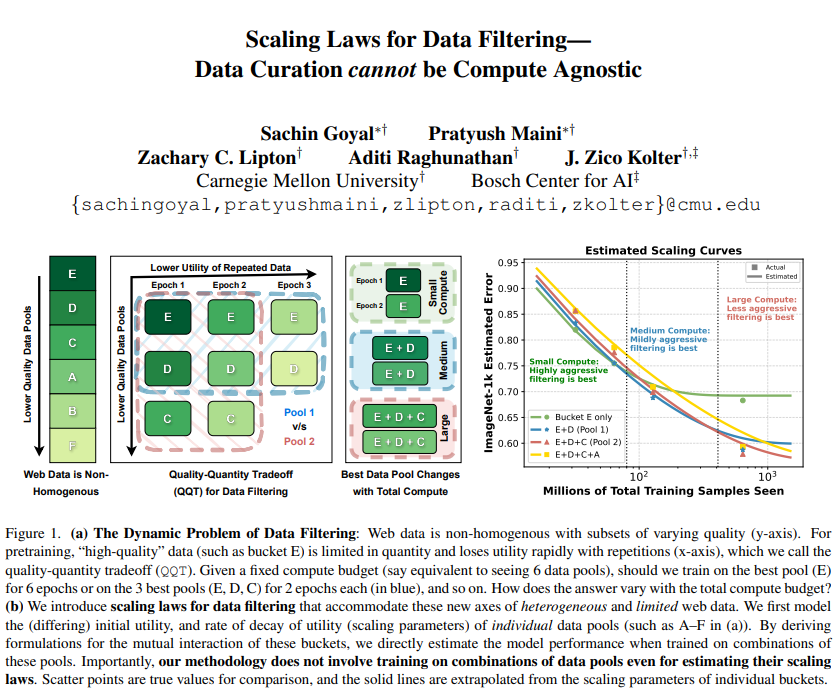
1/ 🥁Scaling Laws for Data Filtering 🥁 TLDR: Data Curation *cannot* be compute agnostic! In our #CVPR2024 paper, we develop the first scaling laws for heterogeneous & limited web data. w/@goyalsachin007 @zacharylipton @AdtRaghunathan @zicokolter 📝:arxiv.org/abs/2404.07177
@lateinteraction Yeah I've been wondering about this too. So many people totally misunderstood what LLMs can do and how they do it, which is resulting in people trying to use them for the wrong thing -- so they then end up disappointed.

I worry about a bubble burst once people realize that no AGI is near—no reliably generalist LLMs or “agents”. Might seem less ambitious but it's far wiser to recognize: LLMs mainly create opportunities for making *general* progress for building AIs that solve *specific* tasks.
JetMoE Reaching Llama2 Performance with 0.1M Dollars Large Language Models (LLMs) have achieved remarkable results, but their increasing resource demand has become a major obstacle to the development of powerful and accessible super-human intelligence. This report introduces

Microsoft presents Rho-1: Not All Tokens Are What You Need RHO-1-1B and 7B achieves SotA results of 40.6% and 51.8% on MATH dataset, respectively — matching DeepSeekMath with only 3% of the pretraining tokens. repo: github.com/microsoft/rho abs: arxiv.org/abs/2404.07965
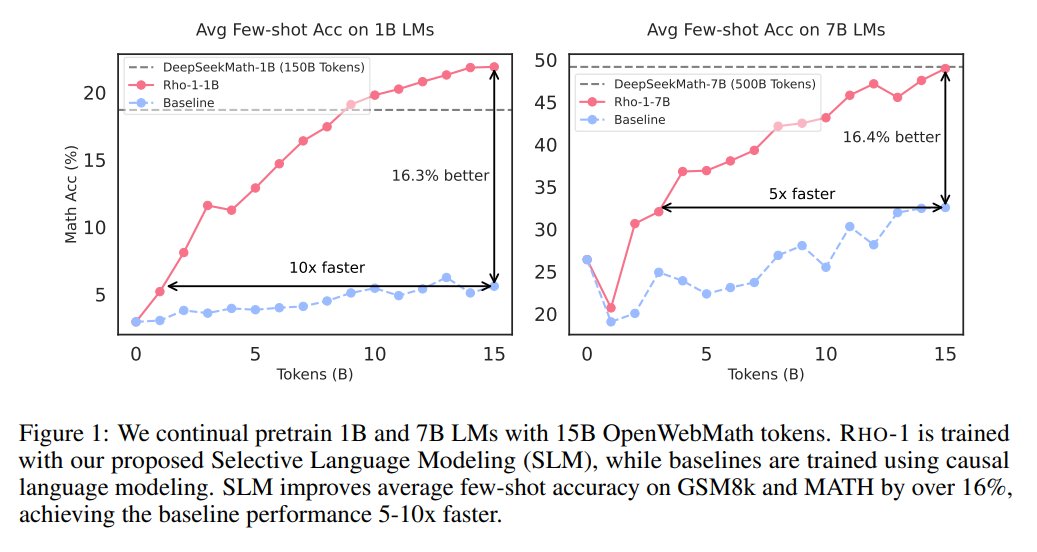
How do you balance repeat training on high quality data versus adding more low quality data to the mix? And how much do you train on each type? @pratyushmaini and @goyalsachin007 provide scaling laws for such settings. Really excited about the work!
1/ 🥁Scaling Laws for Data Filtering 🥁 TLDR: Data Curation *cannot* be compute agnostic! In our #CVPR2024 paper, we develop the first scaling laws for heterogeneous & limited web data. w/@goyalsachin007 @zacharylipton @AdtRaghunathan @zicokolter 📝:arxiv.org/abs/2404.07177
1/ 🥁Scaling Laws for Data Filtering 🥁 TLDR: Data Curation *cannot* be compute agnostic! In our #CVPR2024 paper, we develop the first scaling laws for heterogeneous & limited web data. w/@goyalsachin007 @zacharylipton @AdtRaghunathan @zicokolter 📝:arxiv.org/abs/2404.07177
Scaling Laws for Data Filtering -- Data Curation cannot be Compute Agnostic Argues that data curation cannot be agnostic of the total compute that a model will be trained for repo: github.com/locuslab/scali… abs: arxiv.org/abs/2404.07177
Finding Visual Task Vectors Find task vectors, activations that encode task-specific information, which guide the model towards performing a task better than the original model w/o the need for input-output examples arxiv.org/abs/2404.05729

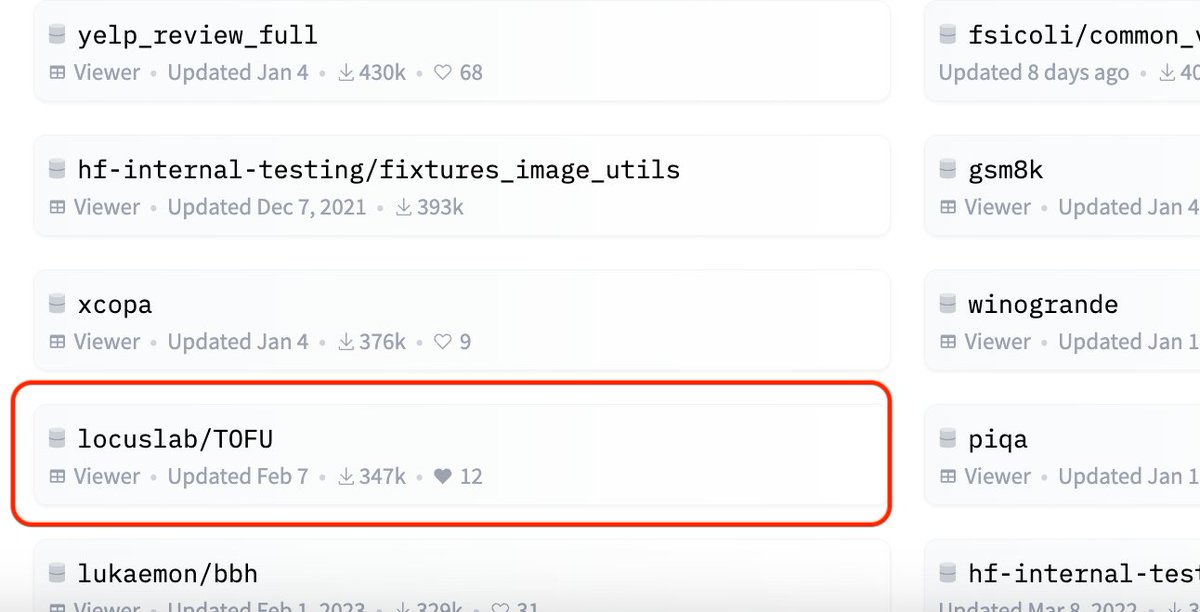
🤯The TOFU dataset (locuslab.github.io/tofu) had 300k+ downloads last month, and is in Top 20 most downloaded datasets on @huggingface📈. This is crazy given how small the LLM unlearning community is compared to, say, LLM evals (for GSM8k). Excited to see what y'all are building!
Will visit @agihouse_org for the first time this Saturday and talk about SWE-agent, Agent-Computer Interface (ACI), and answer questions😃

SWE-agent is our new system for autonomously solving issues in GitHub repos. It gets similar accuracy to Devin on SWE-bench, takes 93 seconds on avg + it's open source! We designed a new agent-computer interface to make it easy for GPT-4 to edit+run code github.com/princeton-nlp/…

Trends for United States
You might like