
-
Tweets62
-
Followers384
-
Following168
-
Likes92
Excited to announce that SqueezeLLM and LLMCompiler have been accepted to ICML 2024! 🎉 SqueezeLLM addresses massive outliers in LLMs, through a dense-and-sparse decomposition. The massive outliers are efficiently isolated through in the sparse part, and the remainder is…

Apple's recent OpenELM is very interesting and showcases that a layer-wise scaling technique can be more optimal, at least for small language model regime. Some insights: - Adopts Transformer modifications from the DeLight paper: starts with narrower, then wider blocks…

What to do if you don’t have enough data to fine-tune an LLM? Fine-tuning is a very promising method for specializing LLMs but it often requires a non-trivial number of data points. But in many cases it is very hard to obtain enough data. LLM2LLM addresses this by utilizing a…
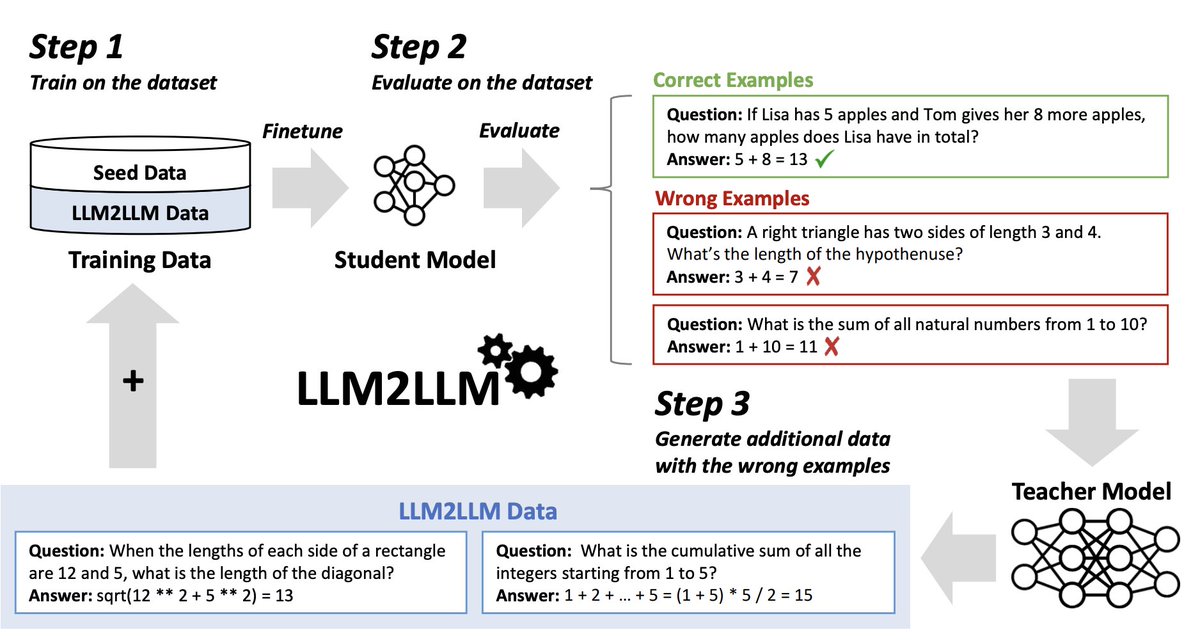
LLM2LLM: Boosting LLMs with Novel Iterative Data Enhancement Significantly enhances the performance of LLMs in the low-data regime, outperforming various baselines (e.g. up to 24.2% improv. on GSM8K) arxiv.org/abs/2403.15042

Will LLMs disrupt modern e-commerce and web navigation? 🤖🛍️ We recently tested LLMCompiler on WebShop dataset and it outperformed ReAct by 20% higher accuracy. So we decided to test this on a real website. We asked LLMCompiler to buy an On running shoe, and gave it browser…
I think this will mark an important milestone for Gen AI. The spotlight has been on the capabilities of LLMs (scaling laws, leaderboards, etc). But it's now clear that LLM performance alone will be meaningless. You will need a Compound AI system to get the best performance out of…

I think this will mark an important milestone for Gen AI. The spotlight has been on the capabilities of LLMs (scaling laws, leaderboards, etc). But it's now clear that LLM performance alone will be meaningless. You will need a Compound AI system to get the best performance out of…
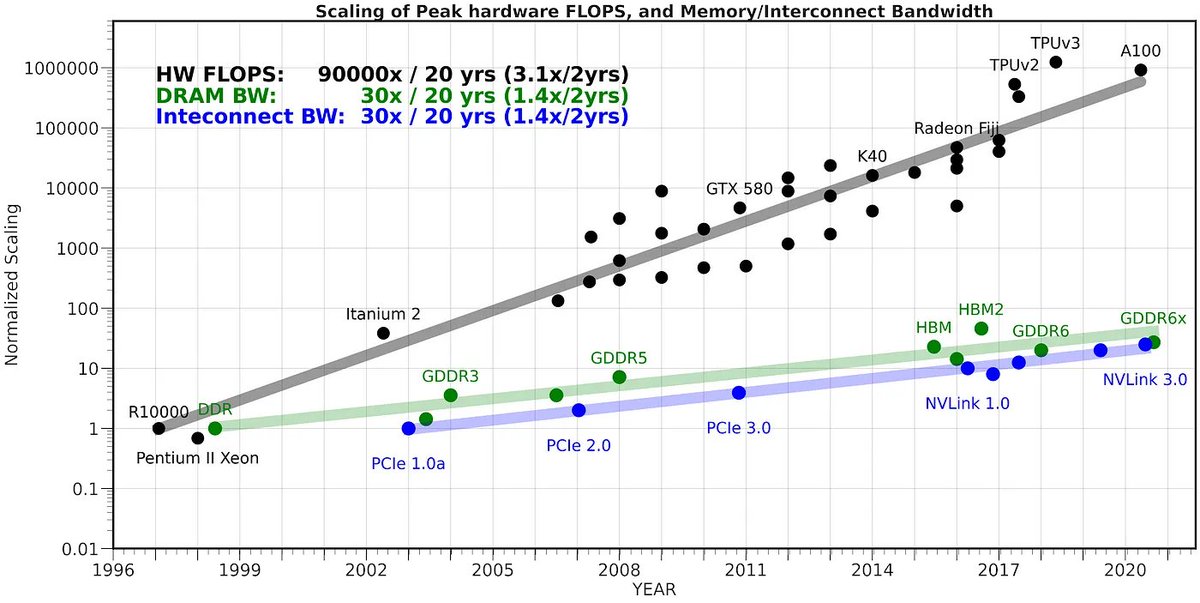
And this chart makes me wonder if the next trillion dollar valuation hardware company is a memory technology innovator!

What is blocking LLMs from allowing long context inputs? 🚨Introducing KVQuant which allows serving LLaMA-7B with 1M context length on a single A100! 🔥 Current largest model is Claude-2.1 which is limited to 200K tokens. What is the challenge for increasing this? Two key…


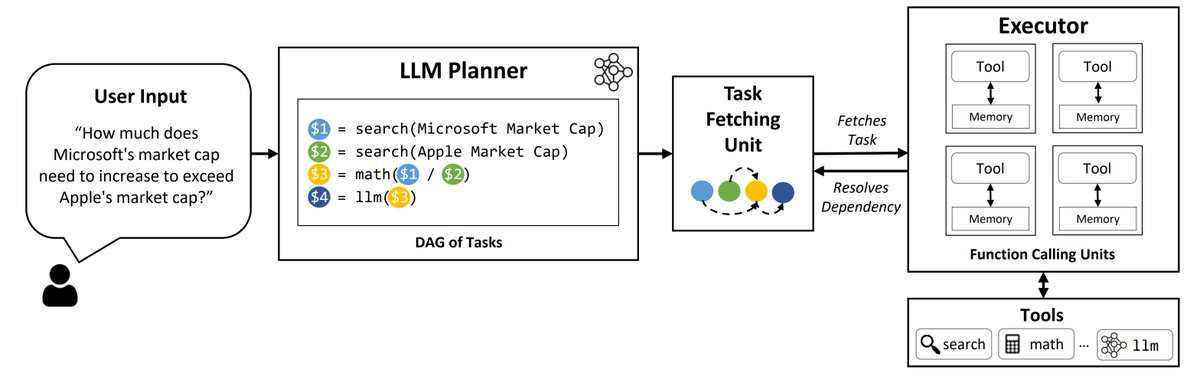
Here are 7 challenges that AI engineers must solve in order to build large-scale intelligent agents (“LLM OSes”): 1️⃣ Improving Accuracy: Make sure agents can solve hard tasks well 2️⃣ Moving beyond serial execution: identify parallelizable tasks and run them accordingly 3️⃣…


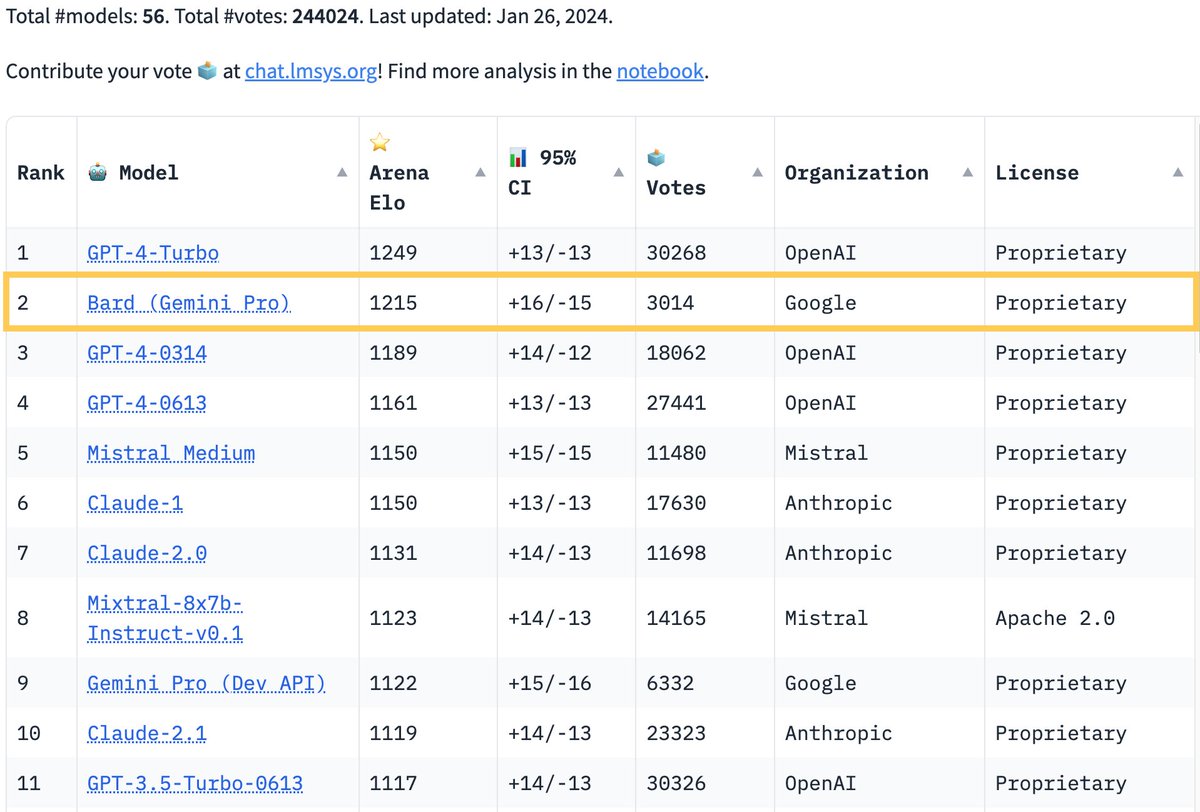
🔥Breaking News from Arena Google's Bard has just made a stunning leap, surpassing GPT-4 to the SECOND SPOT on the leaderboard! Big congrats to @Google for the remarkable achievement! The race is heating up like never before! Super excited to see what's next for Bard + Gemini…
Our first webinar of 2024 explores how to efficiently, performantly build agentic software 🎉 We’re excited to host @sehoonkim418 and @amir__gholami to present LLMCompiler: an agent compiler for parallel multi-function planning/execution. Previous frameworks for agentic…


🚨LLMCompiler is now available on @llama_index 🦙. Check this out! How to use: llamahub.ai/l/llama_packs-… Notebook example: github.com/run-llama/llam…
🚨LLMCompiler is now available on @llama_index 🦙. Check this out! How to use: llamahub.ai/l/llama_packs-… Notebook example: github.com/run-llama/llam…

How can we make LLM agents work together efficiently on complex tasks at a large scale? 🚨Introducing LLMCompiler🦙🛠️, a tool that compiles an effective plan for executing multiple tasks in parallel. It helps create scalable LLM applications, identifies tasks for parallel…
2-Year Update on AI and Memory Wall: New hardware data shows that memory is increasingly becoming the main bottleneck and not compute! Some observations: * The peak compute available in Flagship HW has been increasing at a rate of 3.0x/2yrs. In contrast, both the DRAM and…


@karpathy Very interesting post. Deepmind released their paper concurrent to our work on "Big Little Transformer Decoder", which exploits this opportunity. But we also found that it is better to use a *dynamic fallback policy* instead of always falling back after generating a fixed number…
Very interesting post by @karpathy (also thanks for sharing our blogpost). Based on this we have also recently designed a more efficient compression called dense-and-sparse quantization to reduce memory traffic. This will be added to llama.cpp soon github.com/SqueezeAILab/S…

Very interesting post by @karpathy (also thanks for sharing our blogpost). Based on this we have also recently designed a more efficient compression called dense-and-sparse quantization to reduce memory traffic. This will be added to llama.cpp soon github.com/SqueezeAILab/S…

If you're seeking to understand how Transformers work and where to make them better, there is no better paper to read than "Full Stack Optimization of Transformer Inference: a Survey" by Kim and Hooper with @KurtKeutzer and @amir__gholami arxiv.org/abs/2302.14017

I hit a bug in the Attention formula that’s been overlooked for 8+ years. All Transformer models (GPT, LLaMA, etc) are affected. Researchers isolated the bug last month – but they missed a simple solution… Why LLM designers should stop using Softmax 👇 evanmiller.org/attention-is-o…


hal9000 @hal9696
19 Followers 239 Following

Jeremy Cohen @deepcohen
4K Followers 869 Following PhD student in machine learning at Carnegie Mellon. The goal of my research is to turn deep learning into a real engineering discipline.

Zhewei Yao @yao_zhewei
90 Followers 88 Following Working on AI at @snowflakedb, @MSFTDeepSpeed core-contributor, @UCBerkeley Ph.D.
Zhaoyang Wang @wangwan83764204
348 Followers 4K Following CS PhD student at Uni of Birmingham in the United Kingdom. Research interests: Automated Machine Learning (BayesianOp), and Reinforcement Learning
Aditya Kusupati @adityakusupati
3K Followers 2K Following 🔬PhD.. @uwcse: @RAIVNLab; Been places..... Done things....

Ionut-Vlad Modoranu @ionutmodo
15 Followers 71 Following PhD student at Institute of Science and Technology Austria
Tina Yang @TinaYan5G
743 Followers 1K Following
Lisa Chayma @ChaymaLisa22801
0 Followers 5 Following
Doug @IAmDougLewis
762 Followers 3K Following He/Him, Staff Software Engineer. Current: eBay. Former:CNN, Voatz, ADP

Gyuwan Kim @kgwmath
695 Followers 1K Following Ph.D. student @ucsbcs and @ucsbNLP working on machine learning for #NLProc. Previously, @Apple MLR, @MSFTResearch, @ClovaAiLab, and @SNUnow.
Sunny Sanyal @SunnySanyal9
332 Followers 803 Following PhD student @UTexasECE| Former @AmazonScience | Member of @MLfoundations and @wncg_UT, studied at 🇮🇳🇨🇳🇺🇲
OMïD @its_omeed
65 Followers 89 Following
Junyuan Hong @hjy836
647 Followers 2K Following Postdoc @VITAGroupUT @UTAustin @MLFoundations. Ph.D @michiganstateu . Ex @SonyAI_global intern. Interests: trustworthy ML, federated learning, privacy, LLM
mengwang @poker901115
34 Followers 942 Following

Mark Huang @markatgradient
515 Followers 145 Following @Gradient_AI_ Democratizing Large Models. Former Quant. Waiting for AGI. https://t.co/ZC0c6oBk3S
Piter @Abasking1991
8 Followers 42 Following
Svetly @svetly
213 Followers 451 Following
bousejin @bousejin
79 Followers 132 Following

In A Maze || inamazen.. @InAMazeNFT
2K Followers 758 Following The original hand drawn #NFT maze collection exclusively minted on #Hedera. Each one is unique, scaleable, solvable and decorative.
Sestertius @RealSestertius
2 Followers 202 Following

jchill043 @jchill043
44 Followers 164 Following
Vincent Koc @koconder
6K Followers 3K Following Technologist and Futurist | Artificial Intelligence Engineering | Data Leadership | Lecturer @MIT | Ex @Qantas | #buildinpublic Views are my own

Moha @SeriousPhantom
732 Followers 1K Following Amadeus | Master of Serendipity | Trying to learn appreciation
Xtian @MindThe0ry
139 Followers 1K Following
Move it move it @totolaricot1
67 Followers 524 Following

Arash Bakhtiari @arashb
103 Followers 607 Following HPC/DL Research SDE, Working on making DL models fast
Sudeep Pillai @sudeeppillai
2K Followers 3K Following Co-founder / CEO @autonomi_ai | Founder Fellow @southpkcommons | Ex-ML Engineering Lead @ToyotaResearch | CS PhD @MIT #girldad
ismail benalla @ismail_ben_alla
0 Followers 88 Following
Schanz Park @SchanzPark
120 Followers 542 Following
Tianqi Chen @tqchenml
15K Followers 973 Following AssistProf @mldcmu and @CSDatCMU. Chief Technologist @OctoML. Creator of @XGBoostProject, @ApacheMXNet, @ApacheTVM. Member https://t.co/QYyfjQNp4p, @TheASF.

Jayoo Hwang @JayooHwang
90 Followers 882 Following Independent deep learning researcher (LLMs, multimodal, agents) @ml_collective, BSc UCalgary


吴学东 @wxudng2
63 Followers 2K Following
Nariman Madani @MadaniNari14591
0 Followers 1 Following
Mkmn @mkmnma
3 Followers 2K Following
Mizael Xavier @mizaelxav
237 Followers 1K Following Little by little, changing the world. 🌍 @brasilcloser @voicefybrasil

Jonathan Frankle @jefrankle
16K Followers 684 Following Chief Scientist, Neural Networks @Databricks via MosaicML. PhD @MIT_CSAIL. BS/MS @PrincetonCS. DC area native. Making AI efficient for everyone at @DbrxMosaicAI
Sergey Levine @svlevine
80K Followers 122 Following Associate Professor at UC Berkeley Co-founder, Physical Intelligence
Crux @getcruxai
113 Followers 29 Following Crux is an AI Co-pilot that enables super-fast decision-making for enterprises assisted by LLM agents having full business context
Andrew Ng @AndrewYNg
1.0M Followers 914 Following Co-Founder of Coursera; Stanford CS adjunct faculty. Former head of Baidu AI Group/Google Brain. #ai #machinelearning, #deeplearning #MOOCs
vLLM @vllm_project
812 Followers 11 Following A high-throughput and memory-efficient inference and serving engine for LLMs

andrew chen @andrewchen
285K Followers 12K Following 🇺🇸 General Partner @ a16z. Investing at the intersection of TECH x GAMES.
Christopher De Sa @chrismdesa
411 Followers 24 Following
Tianqi Chen @tqchenml
15K Followers 973 Following AssistProf @mldcmu and @CSDatCMU. Chief Technologist @OctoML. Creator of @XGBoostProject, @ApacheMXNet, @ApacheTVM. Member https://t.co/QYyfjQNp4p, @TheASF.


Raja Koduri @RajaXg
41K Followers 2K Following makaradhwaja rajabali is my full name. my interests are graphics, computing, math, movies and music.
Nous Research @NousResearch
18K Followers 29 Following The AI Accelerator Company. https://t.co/vrD0aDJeto

Jerry Liu @jerryjliu0
45K Followers 1K Following co-founder/CEO @llama_index Careers: https://t.co/EUnMNmbCtx Enterprise: https://t.co/Ht5jwxSrQB
Simon Mo @simon_mo_
342 Followers 303 Following Working on System for ML @ucbrise. Happy to get in touch: https://t.co/ACIbL2HqBr at https://t.co/FWFXdUDDMp (ex-@anyscalecompute)
Ying Sheng @ying11231
4K Followers 489 Following PhD student @Stanford. Large Language Models and Programs. | Do it anyway
Maxime Labonne @maximelabonne
12K Followers 437 Following Author of Hands-On Graph Neural Networks https://t.co/Q8victWUmR • Machine Learning Scientist
Tereza Tizkova @tereza_tizkova
3K Followers 1K Following DevRel @e2b_dev | Mathematics Graduate | Prague & San Francisco

Shiyi Cao @shiyi_c98
404 Followers 362 Following PhD student @UCBerkeley, MSc @ETH, B.S @sjtu1896, systems, ml, and hpc
fern 🌱 @fernwuzhere
245 Followers 186 Following Growing @narada_ai - building proactive AI // and we’re back @savvydatinggame
niki parmar @nikiparmar09
10K Followers 780 Following
Ashish Vaswani @ashVaswani
19K Followers 2K Following
Asim Shrestha @asimdotshrestha
12K Followers 729 Following Cofounder, @ReworkdAI YC S23. Working on multi-modal agents
Zizheng Tai @zizhengtai
14 Followers 132 Following
Arian Adeli @arianadeliii
2K Followers 249 Following Founder @Evernomic. Writer @Entrepreneur. Beyond boundaries.
Justin Wong @justinwong8314
92 Followers 174 Following CS PhD Student at UC Berkeley advised by Joseph Gonzalez and Sanjit Seshia.
Narada AI @Narada_AI
55 Followers 5 Following Narada is the first generative AI assistant that lets you chat with your everyday tools! Learn more at https://t.co/o4nOXhmhn5


Banghua Zhu @BanghuaZ
2K Followers 805 Following PhD @Berkeley_EECS, statistics, info theory, LLM, RL, Human-AI Interactions.
Suhong Moon @snrpsnr
35 Followers 155 Following

Ryan Tabrizi @ryan_tabrizi
92 Followers 216 Following research @berkeley_ai @callaunchpad | prev. @NASAJPL @insitro, @forai_ml | he/him
elvis @omarsar0
189K Followers 486 Following Building with LLMs @dair_ai • Prev: Meta AI, Galactica LLM, PapersWithCode, Elastic, PhD • Creator of the Prompting Guide (~4M learners)
Alex Graveley @alexgraveley
31K Followers 936 Following I’m Alex Graveley, creator of GitHub Copilot, AI Tinkerers, Dropbox Paper, MobileCoin, and Hackpad. Building @ai_minion Hiring https://t.co/nsHar8OLPC
Coleman Hooper @coleman_hooper1
14 Followers 0 Following
Zhewei Yao @yao_zhewei
90 Followers 88 Following Working on AI at @snowflakedb, @MSFTDeepSpeed core-contributor, @UCBerkeley Ph.D.
Avi @AviSchiffmann
77K Followers 3K Following
Robert Scoble @Scobleizer
505K Followers 68K Following Follow me on my new podcast with AI startups, Unaligned. Tech industry color commentator since 1993. Author/Blogger. Former strategist @Microsoft.
Dan Siroker @dsiroker
33K Followers 3K Following Co-Founder & CEO of @LimitlessAI: a personalized AI powered by what you’ve seen, said, or heard. Formerly @RewindAI. Co-Founder of @Optimizely (sold for $300M).
Zongheng Yang @zongheng_yang
2K Followers 713 Following Building SkyPilot @skypilot_org | PhD from @Berkeley_EECS, AI & Systems
Naveen Rao @NaveenGRao
29K Followers 788 Following VP GenAI @Databricks. Former CEO/cofounder MosaicML & Nervana/IntelAI. Neuro + CS. I like to build stuff that will eventually learn how to build other stuff.
Logan Kilpatrick @OfficialLoganK
92K Followers 2K Following Lead product for @Google AI Studio and working on the Gemini API, helping developers build with AI, my views!
Takeoff AI @TakeoffAI
8K Followers 2 Following The best place on the internet to learn AI skills. Preorder for 25% off and early access through August 1st, 2025.
Conor D. Bradshaw @conorbradd
420 Followers 201 Following Venture Capital @BrexHQ | Irish 🇮🇪 Big signup bonus: https://t.co/QW8nCVGzLS
Theofanis Karaletsos @Tkaraletsos
4K Followers 2K Following Head of AI @cziscience | probabilistic and deep MLTrends for United States
You might like












