
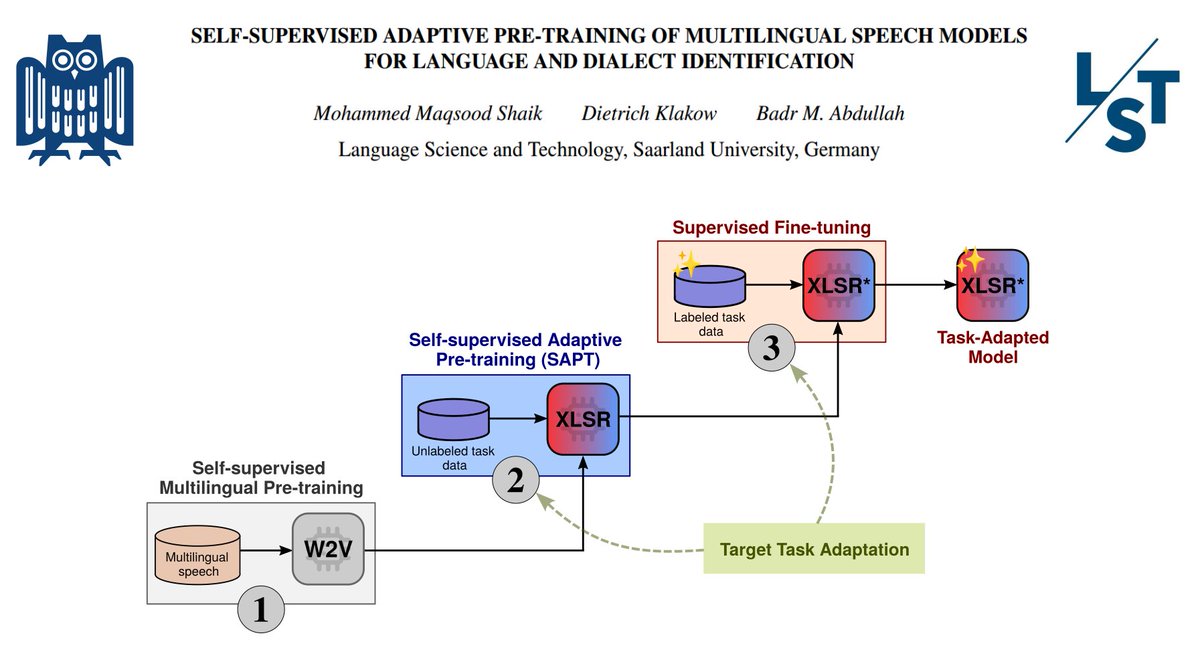
New paper in #ICASSP2024🔔 Self-supervised adaptive pre-training (SAPT) on task data (aka don't stop pre-training) is effective for NLP 🔤 & vision👁️ But... is this also true for speech models? 🤔 In our paper, we investigate this question 🔎 📜 arxiv.org/pdf/2312.07338… 1\🧵
1
11
39
5K
3
Download Image
Concretely, we investigate continual adaptive pre-training of the multilingual speech model XLS-R-128 for the spoken language identification (SLID) task through two experiments 1⃣ FLEURS benchmark, and2⃣ Few-shot learning on 4 different datasets for language & dialect ID 2\🧵