
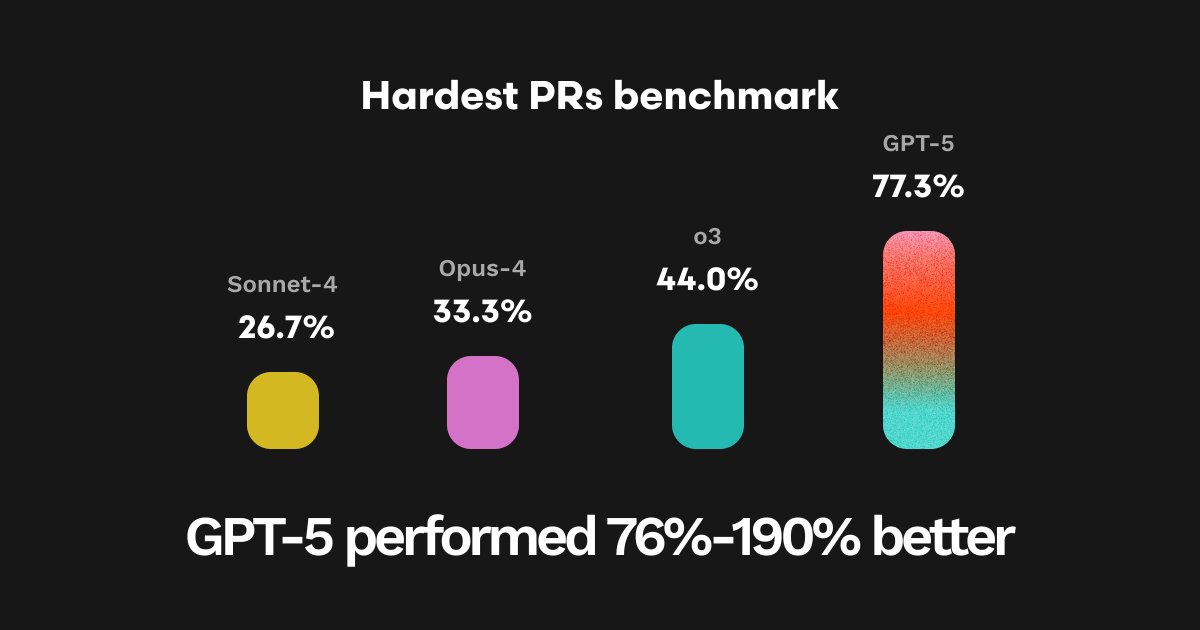
The wait is over! As the leading AI code review tool, CodeRabbit was given early access to OpenAI's GPT-5 model to evaluate the LLM's ability to reason through and find errors in complex codebases! Our evals found GPT-5 performed up to 190% better than other leading models!
29
69
472
92K
114
Download Image
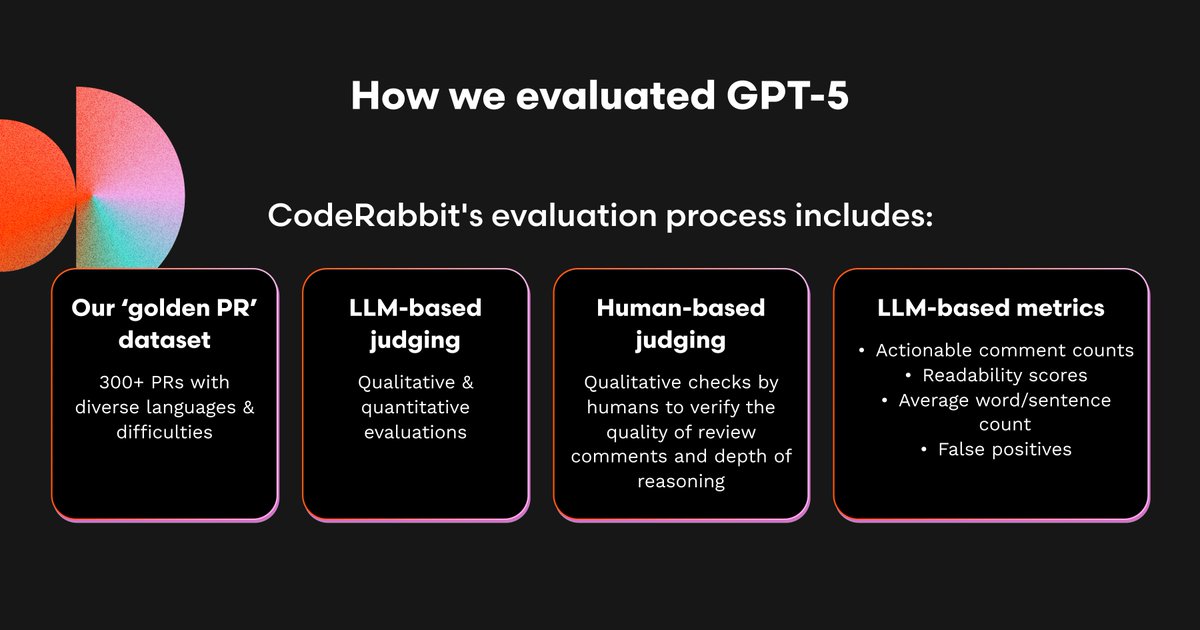
As part of our GPT-5 testing, we conducted extensive evals to uncover the model’s technical nuances, capabilities, and use cases around common code review tasks using over 300 carefully selected PRs.
Across the whole dataset, GPT-5 outperformed Opus-4, Sonnet-4, and OpenAI's O3 on a battery of 300 varying difficulty, error diverse pull requests – representing a 22%-30% improvement over other models
