
Let's talk about a detail that occurs during PyTorch 2.0's codegen - tiling. In many cases, tiling is needed to generate efficient kernels. Even for something as basic as torch.add(A, B), you might need tiling to be efficient! But what is tiling? And when is it needed? (1/13)

To explain tiling, we first need to understand hardware memory accesses. Memory doesn't transfer elements one at a time - it transfers large "chunks". That is, even if you only only need one element, the GPU will load that element... and the 31 elements next to it. (2/13)

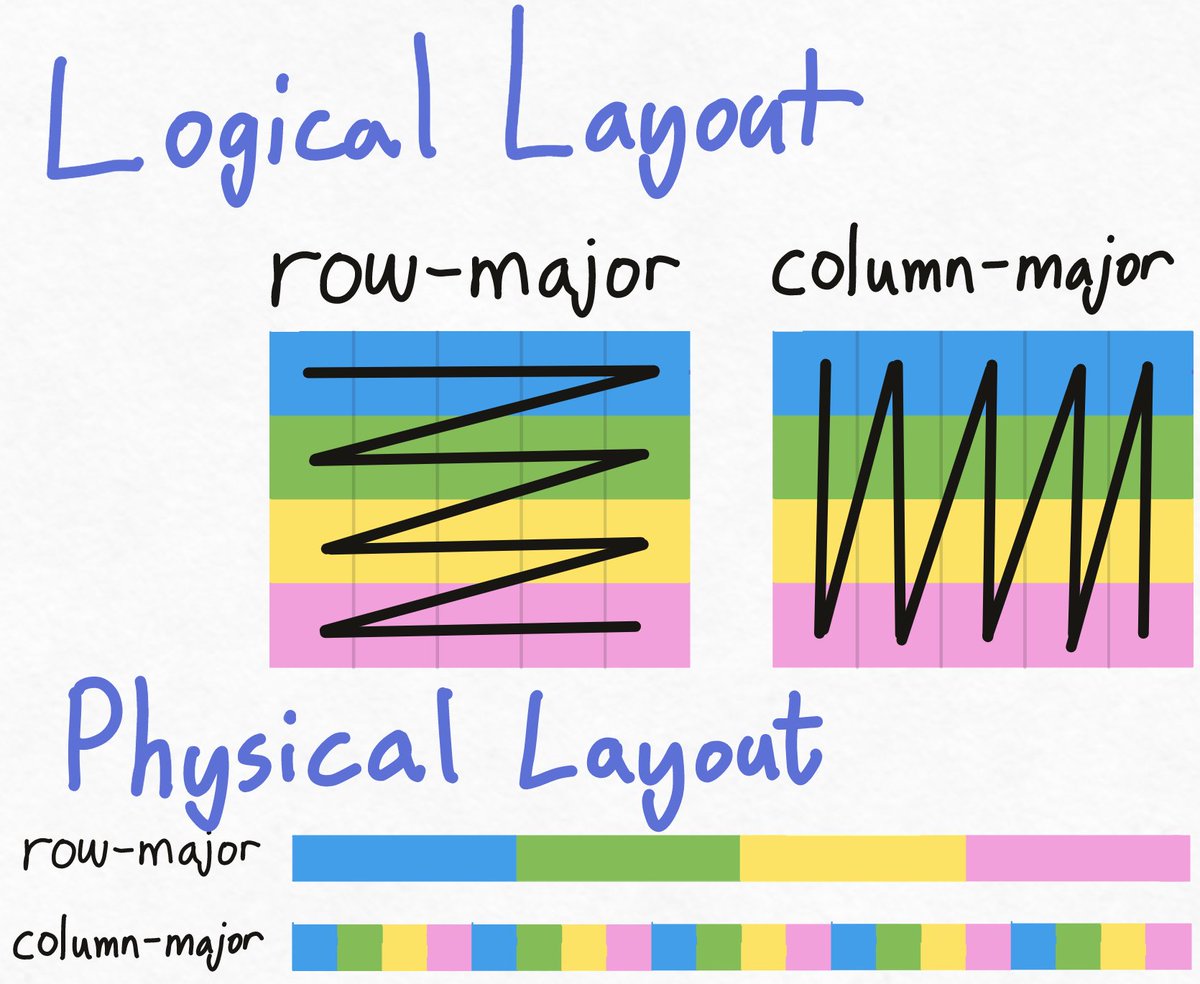
Your layout can affect what operations are efficient. For example, if you access all the blue-elements in the row-major layout, your hardware might only need one "load". OTOH, in the column-major layout, all the blue elements are spread out, requiring multiple loads. (3/13)
So, let's say our GPU loads 2 consecutive elements at a time. This is how calling A + B with two row-major tensors might look. We issue one load to A and one to B, which each load 2 blue values. Then, our compute adds those values. That's 2 loads for 2 values computed. (4/13)

But, what if we're adding two tensors with different layouts, like A + B.t()? For A, we still issue one load for 2 blues. But when we issue a load to B, the blues aren't next to each in memory. So we end up loading greens, which we aren't even computing! (5/13)


@cHHillee Good example! I was wondering why add would benefit from tiling, but the transposed add case is real and a lot easier to explain than a full matrix multiply.
@ID_AA_Carmack Thanks! Yeah, one thing that’s always bugged me about tiling explanations is that they typically use matmuls as the example, when matmuls are so complicated (broadcast *and* reduction??) and have so many more considerations than a simple add with transposed layouts.

@cHHillee @ID_AA_Carmack +1 very well chosen example. I think matmul is more commonly used because cs.utexas.edu/~flame/pubs/Go… but your A+B.T keeps the essence while removing the extras, I really like it and will definitely steal it in the future :)
@giffmana @ID_AA_Carmack Yeah it makes sense since matmul is *the* canonical HPC problem. I was also debating between whether to use A + B.T or just A.T as the example. A.T is even simpler but it's harder to compare against the non-transposed version (copy), and in PyTorch/Numpy transpose is free.