
We have just released 🍷 FineWeb: 15 trillion tokens of high quality web data. We filtered and deduplicated all CommonCrawl between 2013 and 2024. Models trained on FineWeb outperform RefinedWeb, C4, DolmaV1.6, The Pile and SlimPajama!
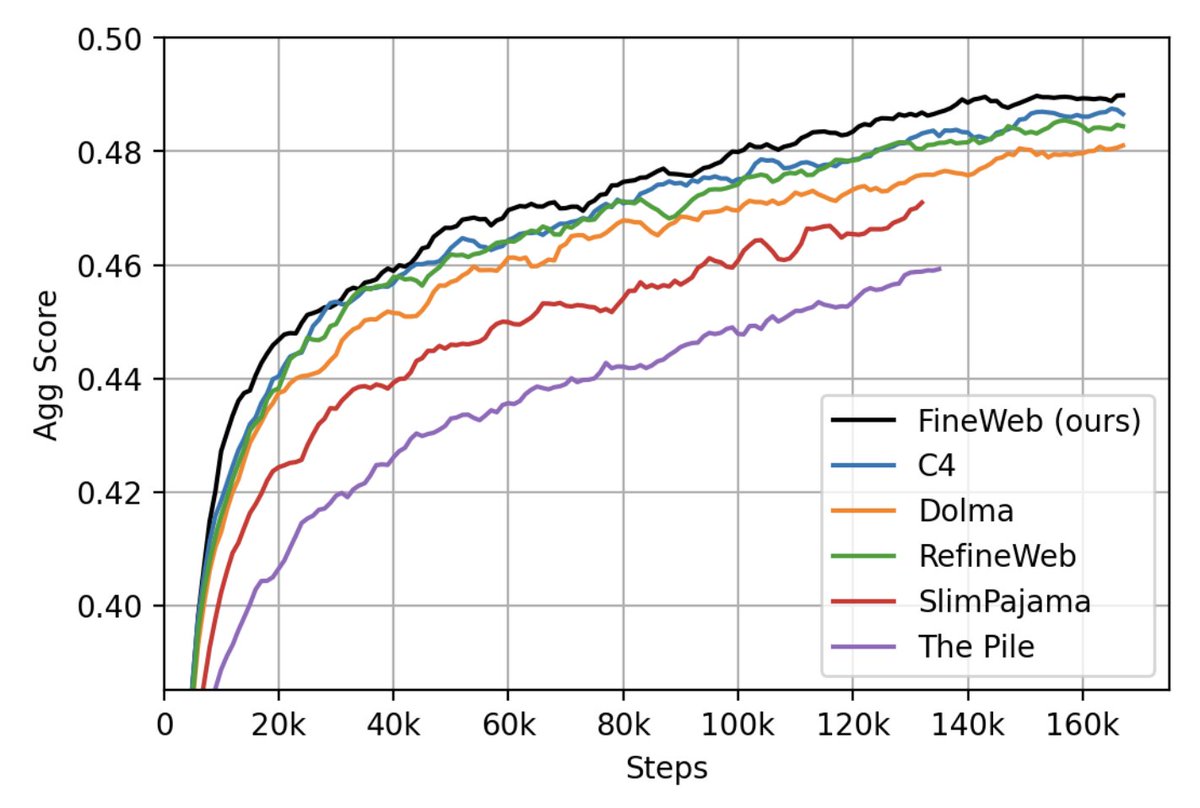
We trained 200+ ablation models to validate our processing decisions, and we share all the code you need to reproduce our setup, along with our dataset comparison ablation models checkpoints! Find out all abut 🍷 FineWeb on the 🤗 model page: huggingface.co/datasets/Huggi…

@gui_penedo Awesome work! When are we going to get dataset with synthetic coding and math data?

@gui_penedo I'm stupid, how understand what inside? (Like can I start to segment and search for any parts of the data in any meaningful way? Like semantic query?

@gui_penedo curious why are some months seem missing?

@gui_penedo Do you anneal the learning rate before downstream task evaluation from each of the checkpoints ? Or just evaluate the checkpoint as is ?

@gui_penedo Do you have a token length histogram laying around maybe? (Compared to c4 and dolma maybe?)