How much does an LM depend on information provided in-context vs its prior knowledge? Check out how @vesteinns, @niklas_stoehr, @JenniferCWhite, @AaronSchein, @ryandcotterell + I answer this by measuring a *context's persuasiveness* and an *entity's susceptibility*🧵
LMs often need to integrate information from context and prior knowledge (e.g. for in-context learning, RAG, etc). But to judge how reliable LMs are at this, a first step is understanding *exactly how much does the LM depend on info given in-context vs its prior knowledge*? (1/n)
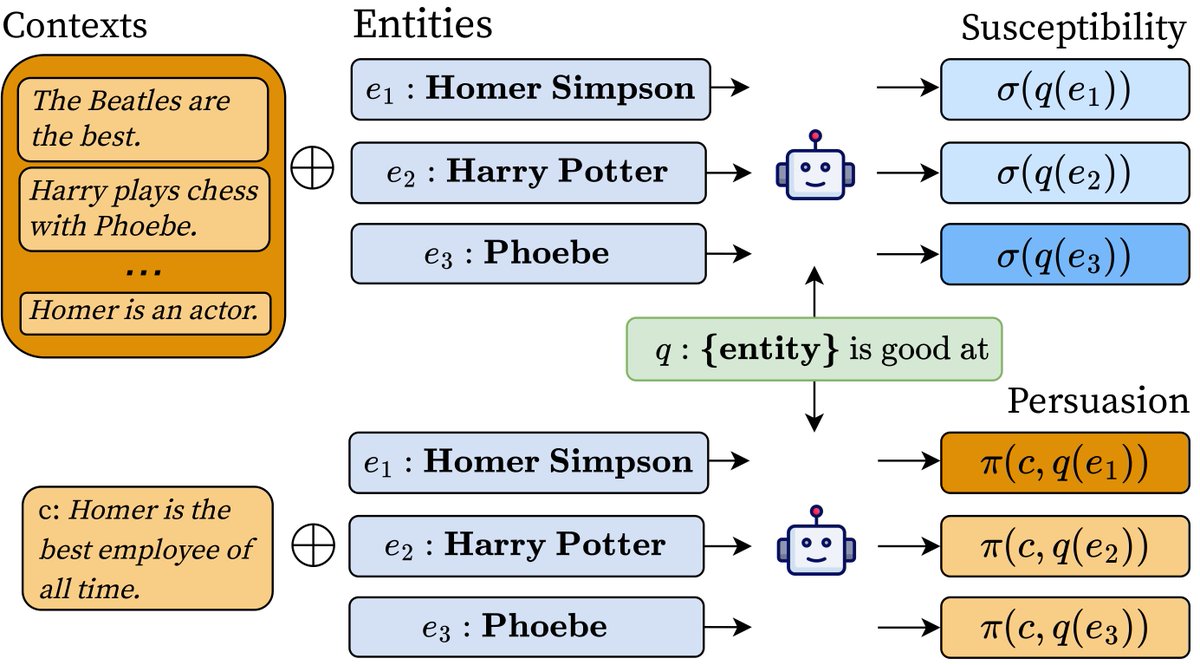
To answer this, we introduce measures based on mutual information for the *persuasiveness* of a context and the *susceptibility* of an entity. Intuitively, a context's *persuasion score* is how much a model's answer distribution to a query changes when provided the context. (2/n)
An entity's *susceptibility score* says, in an info-theoretic sense, how much the model’s answer depends on context for that entity. It's the mutual information btwn answer & context, conditioned on the entity (and also the expected p-score over all contexts for the entity) (3/n)
We build a dataset of queries, entities, & contexts using 122 relations from a knowledge graph and use our measures to analyze model behavior (what kinds of contexts are more persuasive? what makes an entity susceptible?) across 6 model sizes in the Pythia suite (4/n)
So, what makes a context persuasive? Across 122 relations (e.g., alumniOf, capitalOf, highestPoint), we find some general patterns: being relevant to the queried entity is more important than being assertive for all model sizes (5/n)
and assertive contexts are relatively more persuasive to medium-sized models (2.8b) than smaller/larger ones, especially for yes-no questions (6/n)
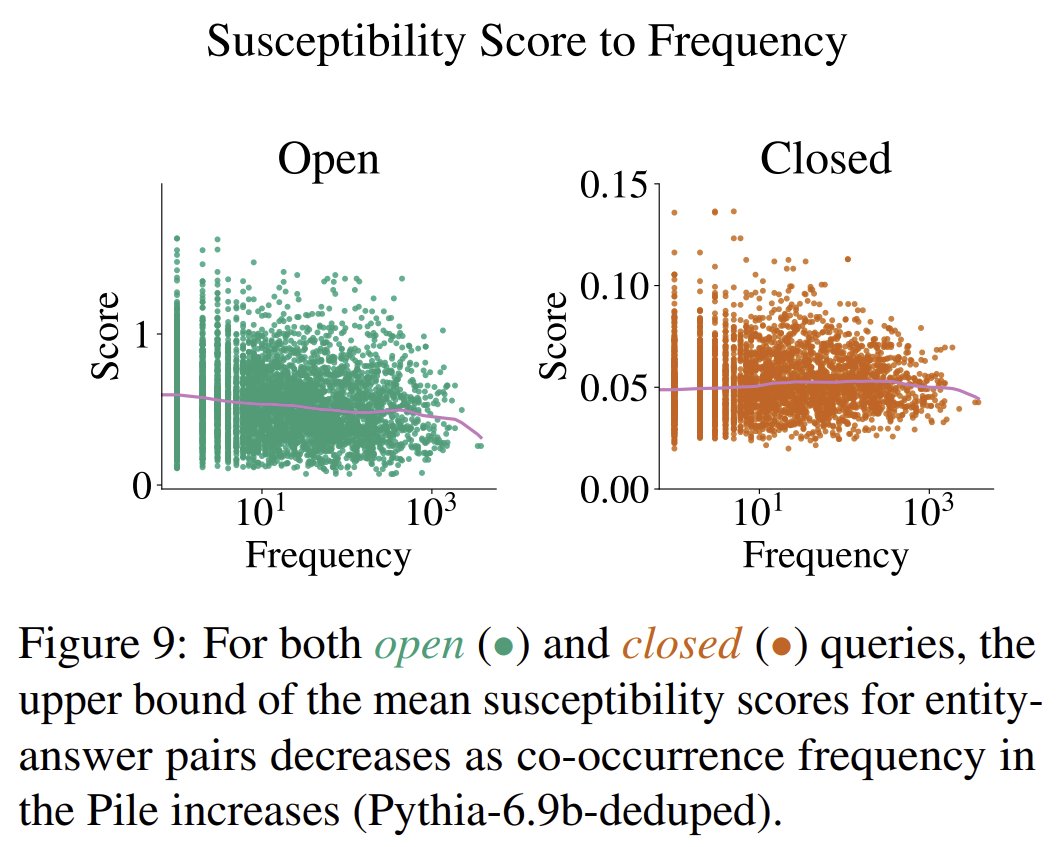
What makes an entity susceptible? We show a relationship between the susceptibility score of an entity and BOTH frequency statistics in its training data AND degree in a knowledge graph. Also, as models get bigger, real entities are less susceptible than fake unknown ones (7/n)