
-
Tweets290
-
Followers621
-
Following214
-
Likes271

V4 is multimodal embeddings, but V4-GGUF wasn't—until now. We've finally cracked how to generate multimodal embeddings using llama.cpp & GGUF. We fixed two main issues. First, in the language model part, we corrected the attention mask in the transformer block so it properly…

mmBERT: Massively Multilingual BERT Trained on 3T+ tokens across 1,833 languages, mmBERT surpasses XLM-R on standard NLU and retrieval benchmarks and is competitive with English-only encoders; in throughput tests it runs 2–4× faster than prior multilingual encoders under…

mmBERT: Massively Multilingual BERT Trained on 3T+ tokens across 1,833 languages, mmBERT surpasses XLM-R on standard NLU and retrieval benchmarks and is competitive with English-only encoders; in throughput tests it runs 2–4× faster than prior multilingual encoders under… https://t.co/uJrWudnBnV

Today we're releasing jina-code-embeddings, a new suite of code embedding models in two sizes—0.5B and 1.5B parameters—along with 1~4bit GGUF quantizations for both. Built on latest code generation LLMs, these models achieve SOTA retrieval performance despite their compact size.…

We are at @qdrant_engine 's Vector Space Day 🚀 in Berlin on Sep 26. We'll talk about "Vision-Language Models: A New Architecture for Multi-Modal Embedding Models" and also share some insights and learnings we gained while training jina-embeddings-v4. 🎫 lu.ma/p7w9uqtz

Got a Mac with an M-chip? You can now train Gemma3 270m locally as a multilingual embedding or reranker model using our mlx-retrieval project. It lets you train Gemma3 270m locally at 4000 tokens/s on M3 Ultra - that's actually usable speed. We've implemented some standard…

Two weeks ago, we released jina-embeddings-v4-GGUF with dynamic quantizations. During our experiments, we found interesting things while converting and running GGUF embeddings. Since most of the llama.cpp community focuses on LLMs, we thought it'd be valuable to share this from…
I went together with @bo_wangbo to SIGIR this year, we wrote a blog post with our highlights and summaries of AI and neural papers that we found interesting at the conference jina.ai/news/what-we-l…
Our official MCP server with read, search, embed, rerank tools on mcp[at]jina[at]ai, where we optimized the embedding and reranker usage particularly for context engineering for LLMs.


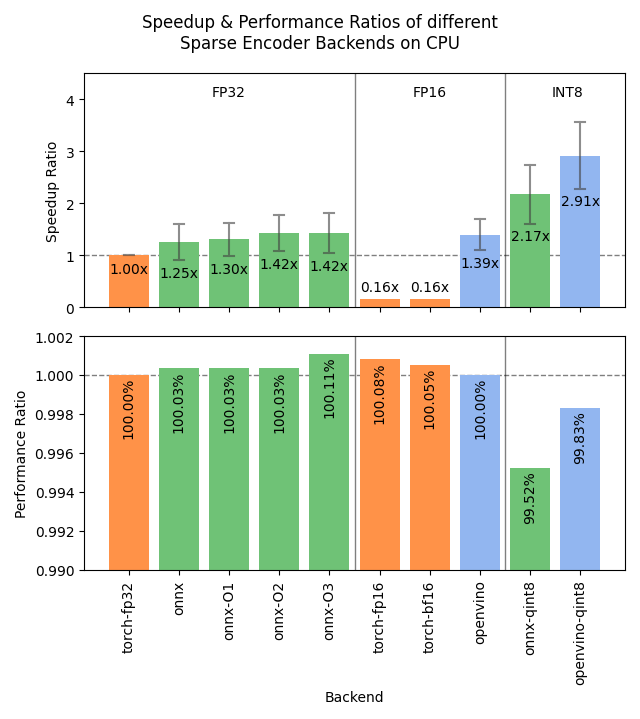
😎 I just published Sentence Transformers v5.1.0, and it's a big one. 2x-3x speedups of SparseEncoder models via ONNX and/or OpenVINO backends, easier distillation data preparation with hard negatives mining, and more! See 🧵for the deets:
Resolution is important for image embeddings - especially for visual document retrieval. jina-embeddings-v4 supports inputs up to 16+ MP (the default is much lower). We wrote a blog post about how resolution affects performance across benchmarks jina.ai/news/how-image…
Finally, a 45 page literature review of text embedding model, datasets, evaluation and training methods: arxiv.org/abs/2507.20783
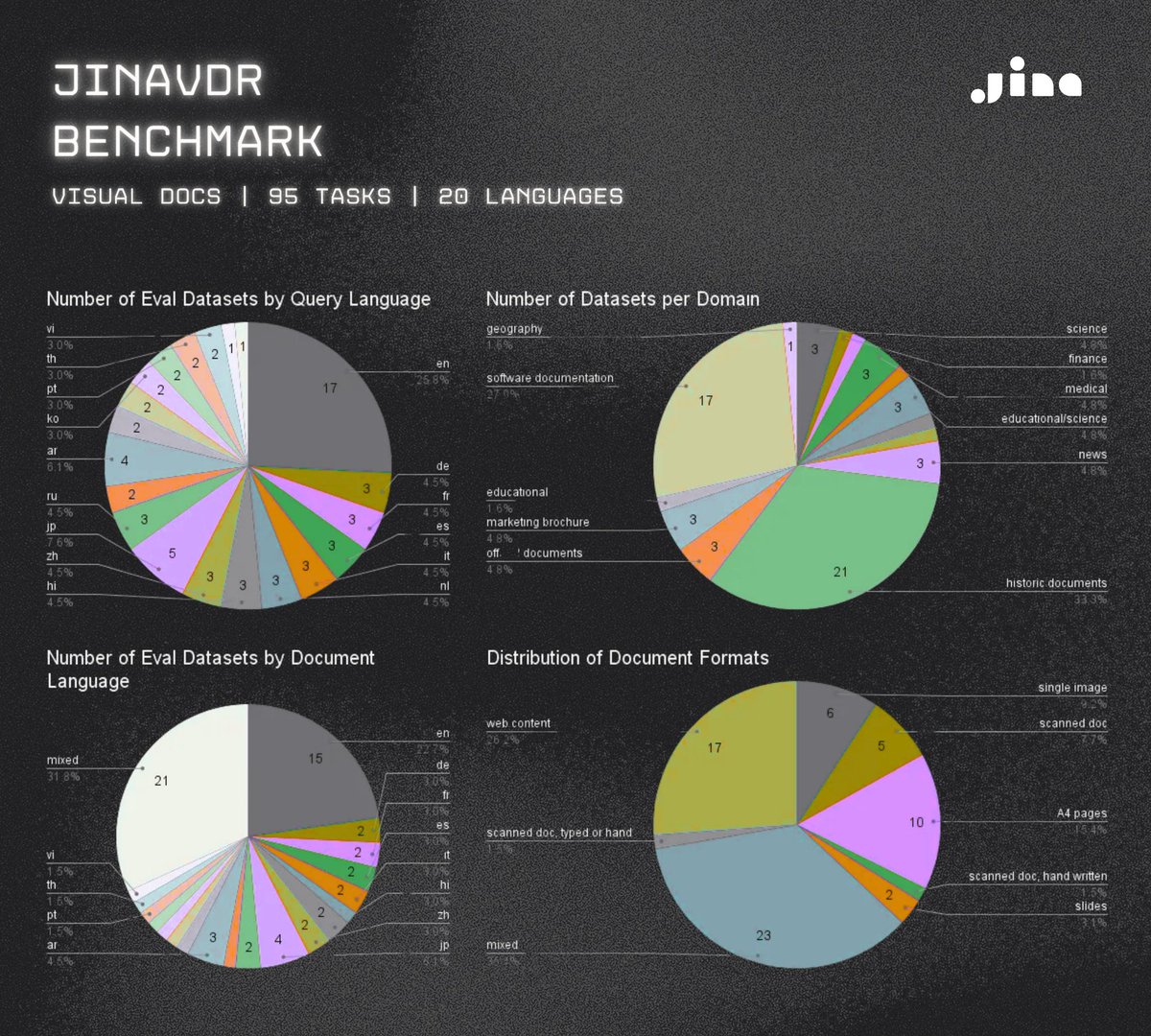
We created a new benchmark for visual document retrieval with diverse visually rich documents (more than linear paginated PDFs) and more query types than just questions github.com/jina-ai/jina-v…
We created a new benchmark for visual document retrieval with diverse visually rich documents (more than linear paginated PDFs) and more query types than just questions github.com/jina-ai/jina-v…

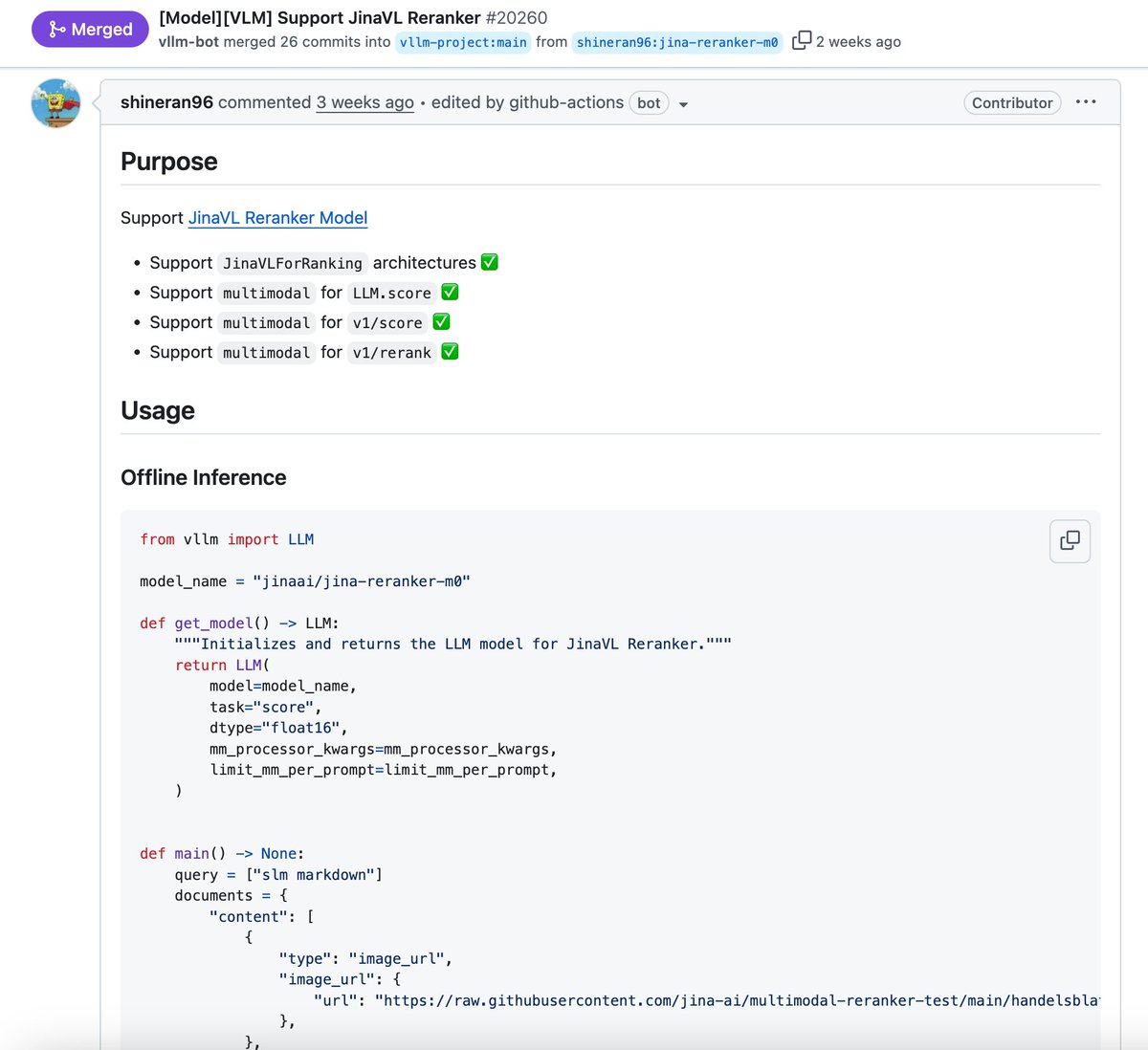
vLLM is finally supporting our multi-modal reranker jina-reranker-m0 huggingface.co/jinaai/jina-re… This is neat!

We've just release 100+ intermediate checkpoints and our training logs from SmolLM3-3B training. We hope this can be useful to the researcher working on mech interpret, training dynamics, RL and other topics :) Training logs: -> Usual training loss (the gap in the loss are due…

jina-embeddings-v4-GGUF is here with different quantizations github.com/jina-ai/jina-e… Unsloth-like dynamic quants is on the way.
Context engineering is curating the most relevant information to pack the context windows just right. Text selection and passage reranking are integral components of it. In part 2 of our Submodularity Series, we show that both text selection and passage reranking yield to…

We just arrived @SIGIRConf! If you're here or are interested in an internship @JinaAI_ on training the following search foundation models, feel free to reach out to me: - Embedding / Dense Retrieval Models - Rerankers - Small LMs (<2B) for document cleaning, extraction, etc.

Our paper "Late Chunking: Contextual Chunk Embeddings Using Long-Context Embedding Models" has been accepted at the Robust IR Workshop @ SIGIR 2025! 🌠 📅 I'll present it on July 17th 📝 Pre-print: arxiv.org/abs/2409.04701 🔗 Workshop: …-2025-workshop-on-robust-ir.github.io



Charan @leisure_daemon
4 Followers 109 Following AI & data enthusiast | Freelance ML tinkerer (experiments, HPO, datasets) Here to share thoughts, projects & random tech takes | DM open for freelance collabs
Peter Lorenz @cs_peter_lorenz
128 Followers 1K Following Post-Doc @NTUsg Past: @UniHeidelberg @OptML_MSU @MITIBMLab @TUGraz https://t.co/YUwZiCVWhv
Maniganda R @ManigandaR1
248 Followers 7K Following

RockyParadox @RockyParadox44
129 Followers 7K Following

Stoica Daniel @DanielDyonis
240 Followers 5K Following
Andrés Escárraga @aescarraga
1K Followers 2K Following Materials engineer & digital transformation project manager. Passionate about AI, Astronomy, History & Geopolitics 🌍

Joel Handwell @JoelHandwell
46 Followers 898 Following Kotlin Multiplatform, Neo4j, JetBrains, Github Copilot user Coding, Testing and Deploying Infrastructure as a #DevOps
Hoai @Hoai290401
16 Followers 575 Following
fairy intelligence @GoblineM60653
5 Followers 332 Following changing myself to me .🦚.NON TECHNICAL PERSON.A SIMPLE PERSON.JUST WANT TO GROW.🌿🌿🌿🌿🎯


Tom Hamer @tom_w_hamer
129 Followers 255 Following Founder & CEO @marqo_ai ($18m+ raised) | Visual search and agentic product discovery
Morgan McGuire @morgymcg
3K Followers 4K Following Applied AI @weights_biases | ex-Facebook Safety | https://t.co/a7i7G5dkLG | 🇮🇪 | Came for the bants, stayed for the rants
Martin Iulian Sobo @IulianSobo
75 Followers 586 Following Photonic CPU R&D | Java-trained developer | Founder @ SMITECHDEV OÜ (Estonia, Est. 2020, IT & Computer Services)

kaito⚡️ @Clinton_ai
1K Followers 1K Following Ml Engineer, love tech, philosophy, and the human mind.
protomachine @protomachine
77 Followers 735 Following Software engineer interested in generative AI, LLMs, and AI agents.
Muhammed Öztaş @MuhammedOztas_
98 Followers 3K Following
Kristian Tasevski @KristianTT
362 Followers 2K Following 👨💼 Principal Engineering Manager @ https://t.co/eoJvSlxoYw 🥷 Mobile + iOS + ML + AI (on-device edge AI/ML) 🇦🇺 Sydney, regular presenter at CocoaHeads
Savannah Williams @SavannahWi18954
71 Followers 274 Following
Bhavesh Patil @Bhavesh_tweeets
158 Followers 1K Following AI @TailoredAI_| Probably running, reading, building or searching enlightenment l Prev: @getcruxai, @sony, @DeutscheBank | alum: @iitbombay
Besher @mr_besher
39 Followers 547 Following
sebæ @lyffseba
162 Followers 1K Following
Drin @dringrayson
219 Followers 4K Following
Dua Rashid @dua_rashid71042
1 Followers 29 Following

Kareem Musleh @kareem_musleh
3 Followers 308 Following
谭欣 @tanxin357
1 Followers 69 Following

Willow Williams @williams_w27622
1 Followers 88 Following
Deepak Y @Bleed_Blue_I
208 Followers 7K Following Machine Learning Practitioner, Interested in Equity Research, Physics, Sports and Space.
Tea @SilagavaTea
5 Followers 103 Following
Scaleborg @scaleborg
3 Followers 421 Following

Max @MAnfilofyev
658 Followers 2K Following CPO @ DR | AI scaling care 8× | 15 yrs fixing US health incentives | Systems takes on trade, talent & fertility | ex-CPA, Hopkins
canis Lupus🐦�... @canisLupus9219
80 Followers 489 Following
Kaival Shah 🤔 @kaivalss
280 Followers 1K Following Robot Dexterity Research 🤖 | Math & CS @NorthwesternU

NeuralNetNinja @DeepLearnQuest
23 Followers 602 Following curious. documenting my deep learning journey.

Mayank Kejriwal @MayankKejriwa13
15 Followers 369 Following
นันทวัฒ... @nnthwthnnx20682
4 Followers 229 Following
Sky Lee @SkyLee010101010
4 Followers 98 Following
Amélie Chatelain @AmelieTabatta
83 Followers 148 Following Head of Knowledge and Search @LightOnIO | PhD in physics of the universe 💫. Interested in IR, Evals & synthetic data. I also like gaming 🎮 and lifting 🏋️♀️.
Xueguang Ma @xueguang_ma
851 Followers 665 Following PhD student at @uwaterloo. Working on encoding the world into vectors. Prev. intern at @Meta, @MSFTResearch, @amazon

Nathan Lambert @natolambert
57K Followers 857 Following Figuring out AI @allen_ai, open models, RLHF, fine-tuning, etc Contact via email. Writes @interconnectsai Wrote The RLHF Book Mountain runner
Piero Molino @w4nderlus7
2K Followers 511 Following CEO @ Studio Atelico | Chief Scientist @ Predibase | Ex-UberAI, Stanford
Omar Khattab @lateinteraction
25K Followers 3K Following Asst professor @MIT EECS & CSAIL (@nlp_mit). Author of https://t.co/VgyLxl0oa1 and https://t.co/ZZaSzaRaZ7 (@DSPyOSS). Prev: CS PhD @StanfordNLP. Research @Databricks.
Antonio Mallia @antonio_mallia
1K Followers 3K Following Senior Research Scientist @ Pinecone Previously, Applied Scientist @ Amazon & PhD @ New York University

Sebastian Weisshaar @SVWeisshaar
20 Followers 264 Following
Lorenz Rumberger @JLrumberger
184 Followers 2K Following Co-Founder | CTO https://t.co/kCjS2Dqfcd Computer Vision Researcher MDC-Berlin
Isaac Flath @isaac_flath
2K Followers 68 Following Teaching AI Assisted Coding at https://t.co/Yisgsz91iH
Bowen Jin @BowenJin13
3K Followers 699 Following Ph.D. @UofIllinois. Search-R1. Apple AI/ML PhD Fellow. Research intern @Apple @GoogleAI @MSFTResearch @AmazonScience. LLMs, Agents, Reasoning, Graphs.
Reza Sayar @iamRezaSayar
672 Followers 4K Following 👨🏻🎓Life-long Learner👨🏻🎓 Kindness❤️, Helpfulness🫂 , AI🧠, Robotics🦾 & Reggaetón💃🏻

Antaripa Saha @doesdatmaksense
15K Followers 399 Following cooking @specstoryai 👩🍳 consulting companies in applied ai | doing maths in my free time

Alexander Doria @Dorialexander
19K Followers 4K Following Reasoning models to come. Co-founder @pleiasfr
Epsilla, Inc @epsilla_inc
172 Followers 119 Following Ship Production-Ready AI Agents on Day 1 Discord: https://t.co/x9hLYR23P8 LinkedIn: https://t.co/fdP1xNvDAQ
JHU CLSP @jhuclsp
7K Followers 6K Following Center for Language and Speech Processing at @JohnsHopkins #NLProc #MachineLearning #AI https://t.co/6IXR5OSQtw @[email protected]
dinos @din0s_
2K Followers 784 Following i tweet about neural IR, model evals, and lifting weights. incredibly optimistic about the future
Sarah Eslami @ESL_Sarah
257 Followers 660 Following PhD candidate @HPI_DE | prev @JinaAI_ @sap | Multimodal LLMs, embeddings

Antoine Chaffin @antoine_chaffin
2K Followers 590 Following 28, French CS Engineer 💻, PhD in ML 🎓🤖 — Guiding generative models for better synthetic data and building multimodal representations @LightOnIO — 🇫🇷🇬🇧
Ian Maurer 🧬 @imaurer
1K Followers 1K Following CTO @GenomOncology #genomics #precisiononcology #nlp
Liran Ringel @liranringel
178 Followers 422 Following CS PhD @TechnionLive | ML Research | Intern @GoogleResearch
Manuel Faysse @ManuelFaysse
2K Followers 408 Following NLP Research, interning at FAIR @AIatMeta + PhD Candidate @CentraleSupelec Prev: @imperialcollege, @epfl


Pierre Vannier @pierre_vannier
4K Followers 6K Following CEO @flint_company | Podcast “IA pas que la Data” https://t.co/wZ0okajiX7 | Chief Vibe Coding Officer, Breaker of things | France AI ambassador
Charles Pierse @cdpierse
500 Followers 584 Following ML @weaviate_io | Occasional maker of things, regular breaker of things.
T Ay. @ayedtay
655 Followers 308 Following ml x data @runwayml | prev. photoroom - - - I only speak for myself

Uwe Crenze @UweCrenze
130 Followers 143 Following seit 1978 in der IT. Geschäftsführender Gesellschafter der interface projects GmbH.
The AI Timeline @TheAITimeline
24K Followers 1 Following covering the latest AI & LLM research /// see "highlights" for all previous weekly threads /// building the best AI paper search engine @findmypapersai
cohere @cohere
108K Followers 4 Following Cohere builds secure, scalable, and private enterprise-grade AI solutions for real-world business problems. Join us: https://t.co/Yb2xItMObl
Rohan Paul @rohanpaul_ai
97K Followers 8K Following Compiling in real-time, the race towards AGI. The Largest Show on X for AI. 🗞️ Get my daily AI analysis newsletter to your email 👉 https://t.co/6LBxO8215l
Hugging Face @huggingface
567K Followers 210 Following The AI community building the future. https://t.co/VkRPD0Vclr


Ahmed Masry @Ahmed_Masry97
509 Followers 760 Following PhD Student @YorkUniversity, Visiting Researcher @Mila_Quebec | Ex-@ServiceNowRSRCH. Multimodality, Document & Chart Understanding, and Vision-Language Models.
aakanksha @____aakanksha
726 Followers 109 Following mts @cohere, previously intern @AmazonScience ms cs @nyuniversity
Prime Intellect @PrimeIntellect
48K Followers 28 Following find compute. train models. contribute to open superintelligence. https://t.co/ZRZOsRRbwr
Evgenii Nikishin @nikishin_evg
4K Followers 936 Following Researcher @OpenAI working on RL & Reasoning. Past: PhD @Mila_Quebec, Intern @GoogleDeepMind #StopWar 🇺🇦
Prompt @engineerrprompt
2K Followers 1K Following Creator of localGPT | Building something cool! Generative AI, Tech, Arts, Life!
Prateek Yadav @prateeky2806
4K Followers 2K Following pre-training @AlatMeta, prev: part-time @GoogleDeepMind, PhD at @unccs
Daniel Williams @drdannywilliams
335 Followers 87 Following Weaviate | Machine Learning Engineer | PhD in machine learning/statistics | He/Him
Maria Khalusova @mariaKhalusova
6K Followers 765 Following Always growing. LLM whisperer, RAG tinkerer, tech generalist, course author. She/her. 🥑 at @UnstructuredIO, previously @huggingface, @DVCorg, @JetBrains
Victoria Slocum @victorialslocum
8K Followers 555 Following learning cool stuff, machine learning engineer at @weaviate_io 💙
Jack Morris @jxmnop
46K Followers 992 Following research @cornell // language models, information theory, science of AI
Simon Suo @disiok
2K Followers 1K Following co-founder @llama_index. prev: research @Waabi_ai @Uber_ATG, PhD ML @UofTTrends for United States
You might like














