
Here is a meta-review we got for third submission of a paper that aims to study text-understanding capacities of LLMs, focusing on very simple, if not trivial, cases where they systematically fail. We see every stated weakness as a strength, and they are all by design.
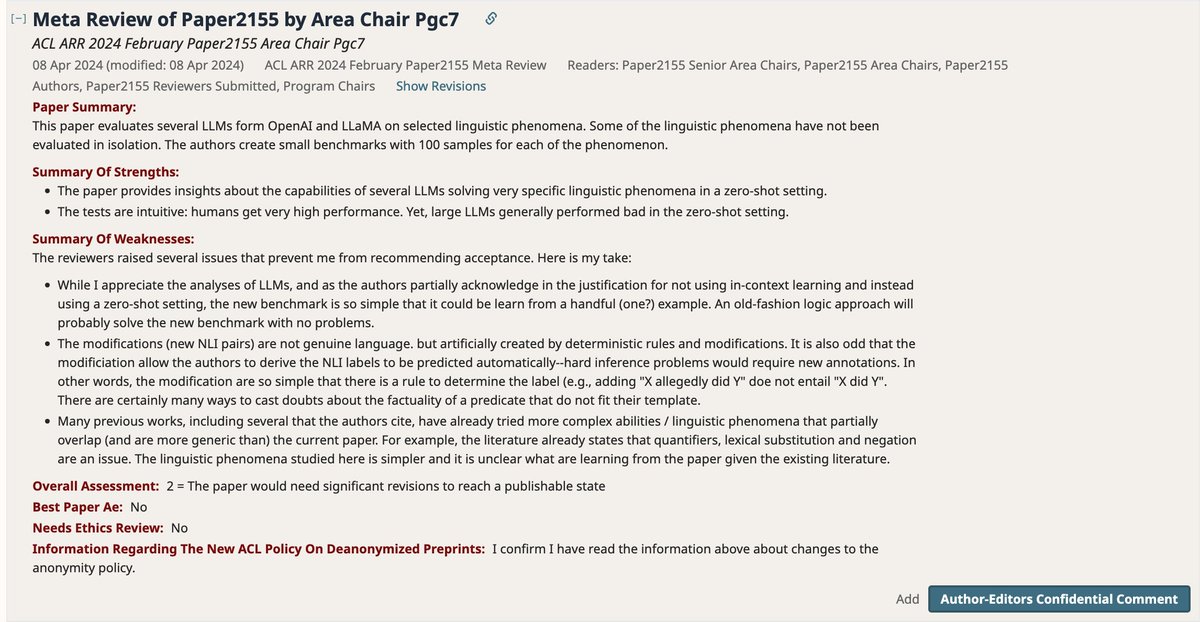
"the new benchmark is so simple that it could be learn from a handful (one?) example. An old-fashion logic approach will probably solve the new benchmark with no problems." YES! and yet the models did not learn it in their massive pre-training. Isn't this noteworthy?

@yoavgo Maybe it's so unusual that you need to spell it out, like "The capabilities of LLMs are bounded by the most complex problems that they can solve, and the simplest problems that they can't. While the former limits are well studied..."