
combin8 @combin8or
GS-z13 Joined December 2021-
Tweets349
-
Followers46
-
Following369
-
Likes4K
That works out to a little more compute than the M4 Pro’s GPU: 4*2.147 TFLOPS = 8.588 TFLOPS vs 8.52 TFLOPS. The A19 Pro is a freaking monster. Congrats to @awnihannun as MLX gets some serious compute on so many devices!
That works out to a little more compute than the M4 Pro’s GPU: 4*2.147 TFLOPS = 8.588 TFLOPS vs 8.52 TFLOPS. The A19 Pro is a freaking monster. Congrats to @awnihannun as MLX gets some serious compute on so many devices!
Jack’s base model is now up on HF: huggingface.co/jxm/gpt-oss-20…

Jack’s base model is now up on HF: huggingface.co/jxm/gpt-oss-20…

#BestPaperAward #SIGGRAPH2025 One neural PDE model, hundreds of shapes — simulated at lightning speed. 🚀 Introducing Shape Space Spectra: first eigenanalysis across shapes. Come see ChangYue’s talk today 👉 changy1506.github.io
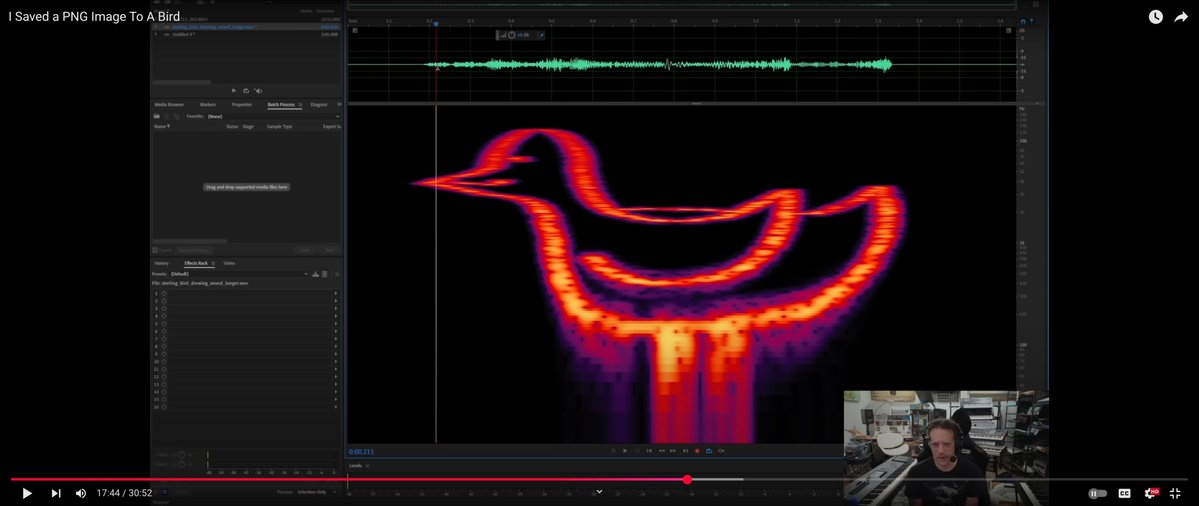
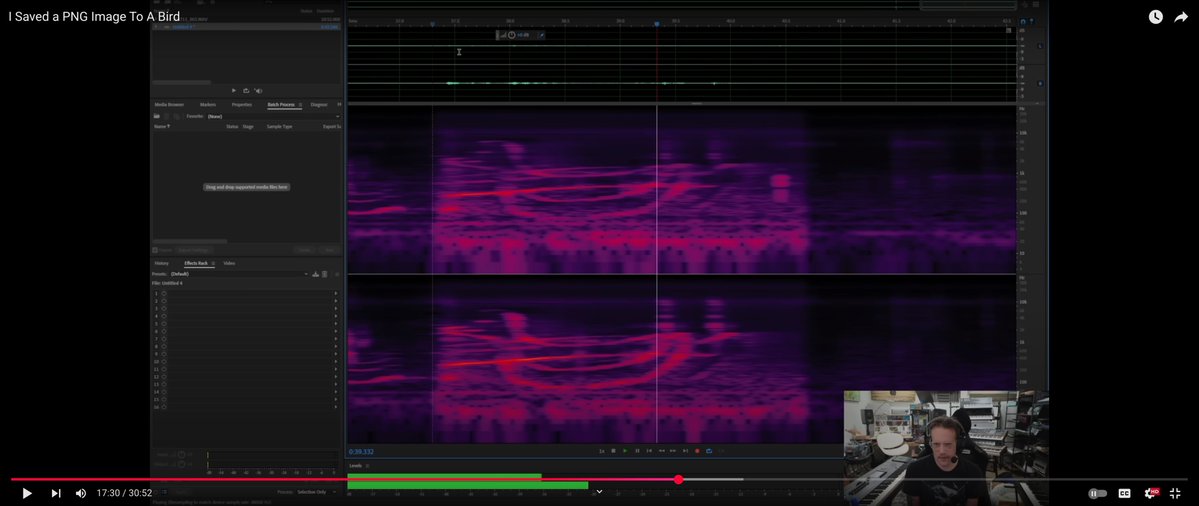
This is one of the craziest ideas I've ever seen. He converted a drawing of a bird into a spectrogram (PNG -> Soundwave) then played it to a Starling who sung it back reproducing the PNG. Using the birds brain as a hard drive with 2mbps read write speed. youtube.com/watch?si=HMtVd…

Beautiful! Also here’s the repo: github.com/apple/embeddin…

Beautiful! Also here’s the repo: github.com/apple/embeddin…



Huge computer science result: A Tsinghua professor JUST discovered the fastest shortest path algorithm for graphs in 40yrs. This improves on Turing award winner Tarjan’s O(m + nlogn) with Dijkstra’s, something every Computer Science student learns in college.

mech interp >> bar charts


Blackwell is detected and memory mapped. Next, bind @__tinygrad__ PyTorch code for NVIDIA to run on Apple Silicon with UT3G. 🤞

that guy who wanted to automate his house with claude code after he rejects claude's suggested changes too many times


that guy who wanted to automate his house with claude code after he rejects claude's suggested changes too many times https://t.co/zUSFU7g0Zo

The Case for Muon 1) We can descend 'faster' in non-Euclidean spaces 2) Adam/Shampoo/SOAP/etc. dynamically learn the preconditioner and, equivalently, the norm & space to descend in 3) Muon saves a lot of compute by simply letting the norm to vary within a fixed range
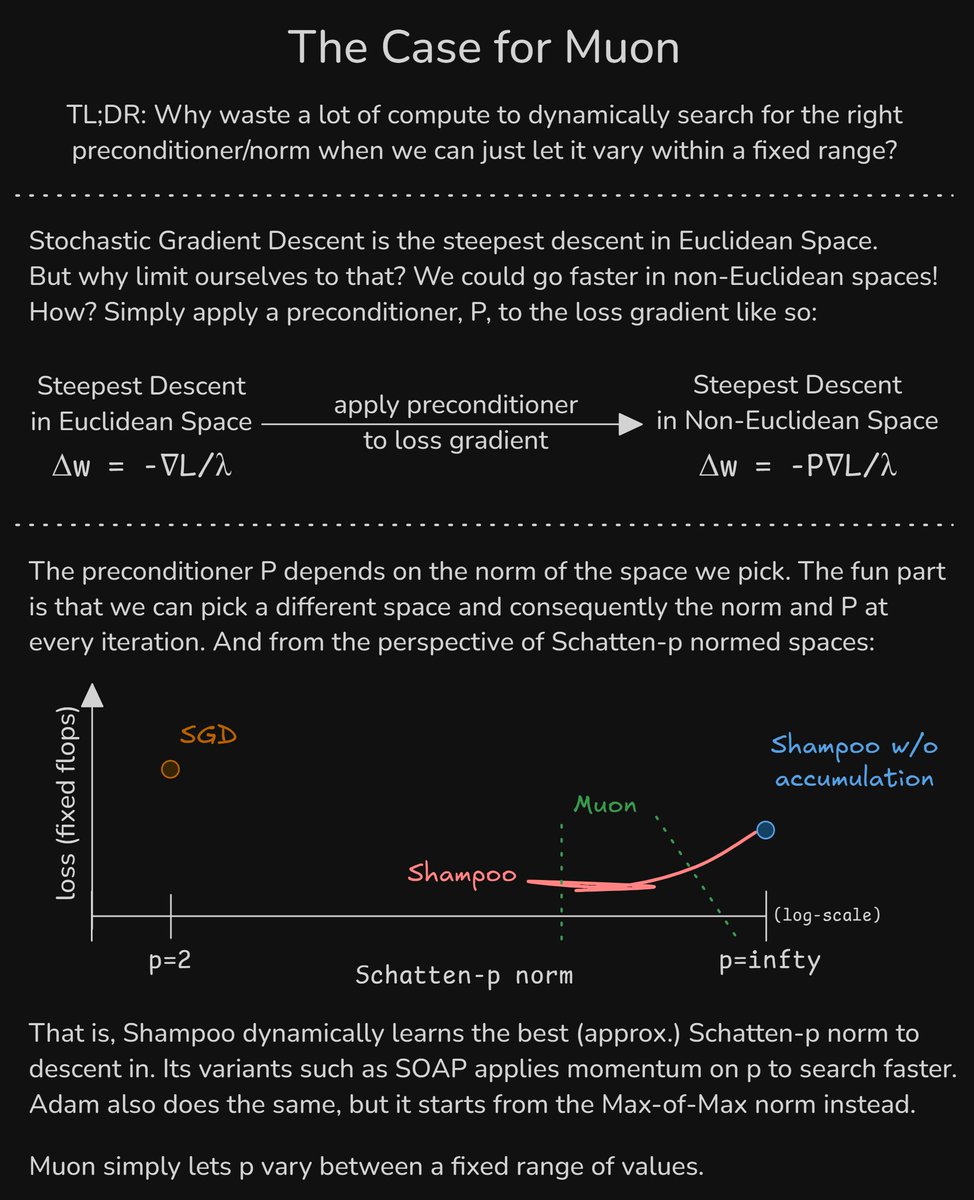
The Case for Muon 1) We can descend 'faster' in non-Euclidean spaces 2) Adam/Shampoo/SOAP/etc. dynamically learn the preconditioner and, equivalently, the norm & space to descend in 3) Muon saves a lot of compute by simply letting the norm to vary within a fixed range https://t.co/PKpXrKSYpT


State space models have struggled to learn to do things like copying and associative recall 🟢 -- things that self-attention learns easily 🟠... But it turns out we just needed to change SSM initialization a bit 🔵. Our init helps a lot, and even makes state space layers *look*…


chipwise.tech/our-portfolio/… We took apart the iPhone 16 & 16pro. This resulted in clear die shots of the A18 & A18pro SoC. Have a look in this article.

SAM & SAM-2 are great but depend on costly annotations. Can we 'segment anything' without supervision?🤔 Yes! Check out UnSAM @NeurIPS24—an unsupervised segmenter that achieves SAM-level results! 🎉 Even better—UnSAM+ beats SAM with +6.7% AR & +3.9% AP, using just 1% labels!💪

I just read up on RAFT. Retrieval-augmented finetuning. Here is how it works: • generate q&a dataset • gather documents for each q&a pair • specify "golden" vs. "distractor" docs • finetune LLM to pick "golden" doc In RAFT, "golden" documents contain the answer to a q&a…


This is a major medical breakthrough—almost the holy grail of stem cell therapy! What makes it personally very thrilling is that the lead scientist of the study, Hongkui Deng, is my close friend & worked together @nyulangone NYU Medical School as postdoc nature.com/articles/d4158…

1/n Introducing SOAP (ShampoO with Adam in the Preconditioner's eigenbasis): A deep learning optimization algorithm that applies Adam in Shampoo's eigenbasis. SOAP outperforms both AdamW and Shampoo in language model pretraining.


@aaron_defazio yeah how do we know it’s not just a reflection-70b wrapper?

Andrea @morrow_andrea89
241 Followers 3K Following
criss sun @CrissSun37484
0 Followers 86 Following
A.M.T @AMAT__2000
66 Followers 1K Following
Benjamin @ben_nicodemus
93 Followers 2K Following
Søren Bramer Schmidt @sorenbs
3K Followers 1K Following Founder and CEO of Prisma. If you are building for a global audience, you should give @prisma a try. DMs open - please reach out.
chris.eth @undefinedza
2K Followers 4K Following Founder @summerstonexyz @graphopsxyz. Council @graphprotocol. Deep in the trenches of data, DeFi and web3 infrastructure.


eoeduo @eoeduo
6 Followers 338 Following

Geosh @Geoshh
102 Followers 1K Following Embodied A.I. | Socioaffective Alignment | Systems Biology & Interpersonal Neurobiology | @UChicago | @EuroGradSchool |healing,science,technology,connection
Zach Mueller @TheZachMueller
13K Followers 605 Following Let's make billions of parameters go brr https://t.co/rUxXIfNpwh
Ofluutac @Ofluutac14748
82 Followers 2K Following
Paul Marin @paulmarin90
330 Followers 2K Following Was meant to be a shape rotator. Rebelled and became a wordcel. Now stuck with Grok and Qwen. To rotate some shapes again.

Ivan Fioravanti ᯅ @ivanfioravanti
17K Followers 933 Following Co-founder and CTO of @CoreViewHQ GenAI/LLM addicted, Apple MLX, Microsoft 365, Azure, Kubernetes, Investor in innovation and Mensa member.

wat @namexyzwastaken
0 Followers 750 Following
Jonas @oh_no_y_me
57 Followers 340 Following

jiyeon kim @jiyeonkimd
134 Followers 214 Following Ph.D. student at KAIST AI previous: economist at Bank of Korea
Florian Fervers @FlorianFervers
7 Followers 91 Following
neo @stankneo
945 Followers 5K Following Cyberpunk Metamodernism. Aspiring hyperwrangler. Searching for lcm(∞-axia). CS ∪ CogSci ∪ Complex Systems.
David van Dijk @david_van_dijk
5K Followers 4K Following Assistant Professor @Yale @YaleMed @YaleCSDept | ML/AI comp bio
Alex Cheema - e/acc @alexocheema
38K Followers 2K Following Building @exolabs | prev @UniOfOxford We're hiring: https://t.co/UlkApFndnH

Luka @lukabos6
107 Followers 574 Following
Victor Veitch 🔸 @victorveitch
4K Followers 1K Following AI | University of Chicago / Google DeepMind

Sophia Xu @thesophiaxu
4K Followers 3K Following applied epistemology | language machines languaging

BD @BDavis631
285 Followers 5K Following
bryanblackbee @bryanblackbee
119 Followers 243 Following What I read, what I saw, what I built, and what I wrote. Marketplace Data Science. All tweets are my own.
Jordi Pons @jordiponsdotme
4K Followers 952 Following Music and AI research at @StabilityAI. Previously at @Dolby and @MTG_UPF.
Michael Timothy Benne... @MiTiBennett
11K Followers 5K Following award winning ai researcher (2 awards so far) | just completed cs phd thesis | author how to build conscious machines | musician | @bennettsrazor @agi_society
Grace (cross posting ... @kindgracekind
5K Followers 2K Following ideonomist, ai navel gazer, skyborg https://t.co/UGyhDIKCaj
neurallambda @neurallambda
1K Followers 510 Following * reasoning: the ability to know true things without having learned them * building homoiconic AI and opensourcing it
Fahad Shah @sfahad
947 Followers 7K Following @Leadership @DataScience @HP @AzureML @Happily Married 😊
SJ @_Shubham_Jha
287 Followers 5K Following I'm an Engineer, so to save time let's just assume I'm always right
MMM @MMM1897775
9 Followers 3K Following
daniel wilson @geoframeai
1K Followers 2K Following founder and CEO of https://t.co/0aZ2rQCOYy | PhD | linguist | AI will speak every language, and we will teach it

Loss Landscape @LandscapeL26502
338 Followers 575 Following PhD Student | ML/AI | Medical Imaging | searching for global optima
aiexplorations @aiexplorations
940 Followers 2K Following AI/ML engineering leader. Learning, exploring and reasoning about AI and the use and development of technology every day. Broad interests. Views are personal.
Haotian Zhang @HaotianZhang4AI
830 Followers 491 Following Research Scientist @ Apple. Ex-Research Intern @ MSR AI. Ph.D. @ UW. Be Borderless.
Sanjeev Arora @prfsanjeevarora
25K Followers 100 Following Director, @PrincetonPLI and Professor @PrincetonCS. Seeks math/conceptual understanding of deep learning and large AI models. Also on the "other" social network
Akanksha @akankshanc
2K Followers 753 Following Passionately in love with Science, mostly Altruistic, Engineer, Amateur Astronomer & Critical thinker. Current Research focus: ▫️Mechanistic Interpretability▫️

Simon Willison @simonw
117K Followers 6K Following Creator @datasetteproj, co-creator Django. PSF board. Hangs out with @natbat. He/Him. Mastodon: https://t.co/t0MrmnJW0K Bsky: https://t.co/OnWIyhX4CH
Gaurav Ghosal @gaurav_ghosal
248 Followers 183 Following Ph.D. Student @mldcmu | Former Undergraduate Student @berkeley_eecs and Researcher @berkeley_ai |
Ziqian Zhong @fjzzq2002
632 Followers 470 Following AI interp & alignment @CSDatCMU, prev @MIT @pika_labs
Zeyuan Allen-Zhu, Sc.... @ZeyuanAllenZhu
21K Followers 466 Following physics of language models @ Meta (FAIR, not GenAI, not TBD) 🎓:Tsinghua Physics — MIT CSAIL — Princeton/IAS 🏅:IOI x 2 — ACM-ICPC — USACO — Codejam — math MCM

Pratyush Maini @pratyushmaini
3K Followers 473 Following Data Quality x Privacy | PhD @mldcmu | Founding Team @datologyai | BTech @iitdelhi
Aditi Raghunathan @AdtRaghunathan
3K Followers 31 Following Assistant professor at CMU @SCSatCMU @CSDatCMU | Machine learning
Grad @Grad62304977
7K Followers 2K Following

Vijay V. @vijaytarian
699 Followers 479 Following Grad student at CMU. I do research on applied NLP. he/him

Songlin Yang @SonglinYang4
14K Followers 3K Following research @MIT_CSAIL @thinkymachines. work on scalable and principled algorithms in #LLM and #MLSys. in open-sourcing I trust 🐳. she/her/hers
Liu Liu @liuliu
2K Followers 269 Following Maintains https://t.co/VoCwlJ9Eq0 / https://t.co/bMI9arVwcR / https://t.co/2agmCPOZ2t. Wrote iOS app Snapchat (2014-2020). Founded Facebook Videos with others (2013). Sometimes writes at https://t.co/Gyt4J9Z9Tv
Ivan Krstić @radian
12K Followers 869 Following Head of Security Engineering+Architecture (SEAR) at Apple. I don’t speak for my employer.
Oscar Balcells Obeso @OBalcells
970 Followers 433 Following
Lari @Lari_island
736 Followers 224 Following LLM personality research (digging things up), game theory, agentic behavior. Sometimes discovering unexpected beauty
Ashish Vaswani @ashVaswani
26K Followers 2K Following

Gheorghe Iuga @gheorgheiuga
1K Followers 470 Following Helping teams build AI-augmented systems that actually work | ai & ml explorer | tech optimist | industry-to-tech translator | ex-EPCM PM
Jessy Lin @realJessyLin
3K Followers 889 Following PhD @Berkeley_AI, visiting researcher @AIatMeta. Interactive language agents 🤖 💬
Zach Mueller @TheZachMueller
13K Followers 605 Following Let's make billions of parameters go brr https://t.co/rUxXIfNpwh
Muyu He @HeMuyu0327
1K Followers 227 Following Post-training @CollinearAI | Trying to be an expert of mixtures

Cat @CatOrman1
20K Followers 3K Following going fast @AstroMechanica 🇺🇸 cofounder @flybyrobotics prev @yale
Lucas Beyer (bl16) @giffmana
110K Followers 524 Following Researcher (now: Meta. ex: OpenAI, DeepMind, Brain, RWTH Aachen), Gamer, Hacker, Belgian. Anon feedback: https://t.co/xe2XUqkKit ✗DMs → email

Sam Paech @sam_paech
3K Followers 201 Following Evals @LiquidAI_ Maintainer of EQ-Bench https://t.co/Jy56OlHrP5 https://t.co/oRApPQwvWS
Jason Wei @_jasonwei
99K Followers 641 Following ai researcher @meta superintelligence labs, past: openai, google 🧠
shreya rajpal @ShreyaR
8K Followers 950 Following ML, systems, and everything in between. Building @guardrails_ai. Previously founding eng @predibase, @Apple SPG, @driveai_, @IllinoisCS, @iitdelhi.

Nicolás Alvarez @nicolas09F9
2K Followers 582 Following I'm now at @[email protected] or https://t.co/t8GFVx5ZFl
Unknownz21 🌈 @URedditor
11K Followers 30 Following Legacy iOS / Mac Enthusiast, Jailbreaker, atheist, #AppleInternal researcher 😄 Discoveries featured by @MacRumors, @Forbes, @Vice, @9to5Mac 🏳️🌈
John Schulman @johnschulman2
65K Followers 1K Following Recently started @thinkymachines. Interested in reinforcement learning, alignment, birds, jazz music
Maziyar PANAHI @MaziyarPanahi
9K Followers 512 Following AI x Healthcare | Creator of @OpenMed_AI | Open-Source AI Advocate ❤️ | e/acc 🇫🇷🇪🇺
Johannes Hagemann @johannes_hage
8K Followers 2K Following co-founder/cto @PrimeIntellect | open superintelligence infra, longevity, techno-optimism


shira @shiraeis
14K Followers 2K Following ai startup. prev: ai @uchicago @mit @intel @cdcgov and a few other places. I personally think I’m quite funny.
Sebastian Raschka @rasbt
359K Followers 1K Following ML/AI researcher & former stats professor turned LLM research engineer. Author of "Build a Large Language Model From Scratch" (https://t.co/O8LAAMRzzW).
Peter Yichen Chen @peterchencyc
625 Followers 410 Following Assistant Prof @UBC | PhysAI Lab Alum: @MIT, @Columbia, @UCLA, @RealityLabs, @weta_digital
Grace Li @grx_xce
2K Followers 408 Following Building @designarena_ai (hiring, dm) / prev cs + neuro @harvard / swe @apple / made in the 51st state apparently
Luca Soldaini 🎀 @soldni
11K Followers 1K Following I like tokens! I lead the OLMo data team at @allen_ai w/ @kylelostat. Open source is fun 🤖☕️🍕🏳️🌈 Opinions are sampled from my own stochastic parrot
Feng Yao @fengyao1909
1K Followers 661 Following Ph.D. student @UCSD_CSE | Intern @Amazon Rufus Foundation Model Ex. @MSFTResearch @TsinghuaNLP
Mira Murati @miramurati
372K Followers 574 Following Now building @thinkymachines. Previously CTO @OpenAI

Sterling Crispin 🕊... @sterlingcrispin
43K Followers 6K Following Artist + Software Developer / Married to @Helen_Crispin_ / Previously AR-VR and NeurotechTrends for United States
You might like



















