
Gaurav Ghosal @gaurav_ghosal
Ph.D. Student @mldcmu | Former Undergraduate Student @berkeley_eecs and Researcher @berkeley_ai | Joined January 2023-
Tweets83
-
Followers248
-
Following183
-
Likes71
📜 Paper on new pretraining paradigm: Synthetic Bootstrapped Pretraining SBP goes beyond next-token supervision in a single document by leveraging inter-document correlations to synthesize new data for training — no teacher needed. Validation: 1T data + 3B model from scratch.🧵

I had the chance to join the TWIML podcast to talk about my group’s ICML 2025 papers! We dug into the surprising limitations of modern pre-training: where it breaks down, why it matters, and what new directions might help us move past these barriers.

I had the chance to join the TWIML podcast to talk about my group’s ICML 2025 papers! We dug into the surprising limitations of modern pre-training: where it breaks down, why it matters, and what new directions might help us move past these barriers.

Since compute grows faster than the web, we think the future of pre-training lies in the algorithms that will best leverage ♾ compute We find simple recipes that improve the asymptote of compute scaling laws to be 5x data efficient, offering better perf w/ sufficient compute

Researchers are working on ways to prevent large language models (LLMs) from simply memorizing information instead of truly learning. They found that removing memorized parts directly can harm the model's ability to learn new things. Their solution, called MemSinks, creates…
I had early sneak peeks into this exciting work on rethinking pretraining—credits to @gaurav_ghosal, my constant buddy through countless late nights at CMU. It’s been a blast building pretraining frameworks and sharing insights. @gaurav_ghosal’s energy is absolutely unmatched!
I had early sneak peeks into this exciting work on rethinking pretraining—credits to @gaurav_ghosal, my constant buddy through countless late nights at CMU. It’s been a blast building pretraining frameworks and sharing insights. @gaurav_ghosal’s energy is absolutely unmatched!
One thing years of memorization research has made clear: unlearning is fundamentally hard. Neurons are polysemantic & concepts are massively distributed. There’s no clean 'delete'. We need architectures that are "unlearnable by design". Introducing, Memorization Sinks 🛁⬇️
One thing years of memorization research has made clear: unlearning is fundamentally hard. Neurons are polysemantic & concepts are massively distributed. There’s no clean 'delete'. We need architectures that are "unlearnable by design". Introducing, Memorization Sinks 🛁⬇️
This was a very fun project and we are really excited to keep working along this direction!
This was a very fun project and we are really excited to keep working along this direction!
There’s been a lot of work on unlearning in LLMs, trying to erase memorization without hurting capabilities — but we haven’t seen much success. ❓What if unlearning is actually doomed from the start? 👇This thread explains why and how *memorization sinks* offer a new way forward.
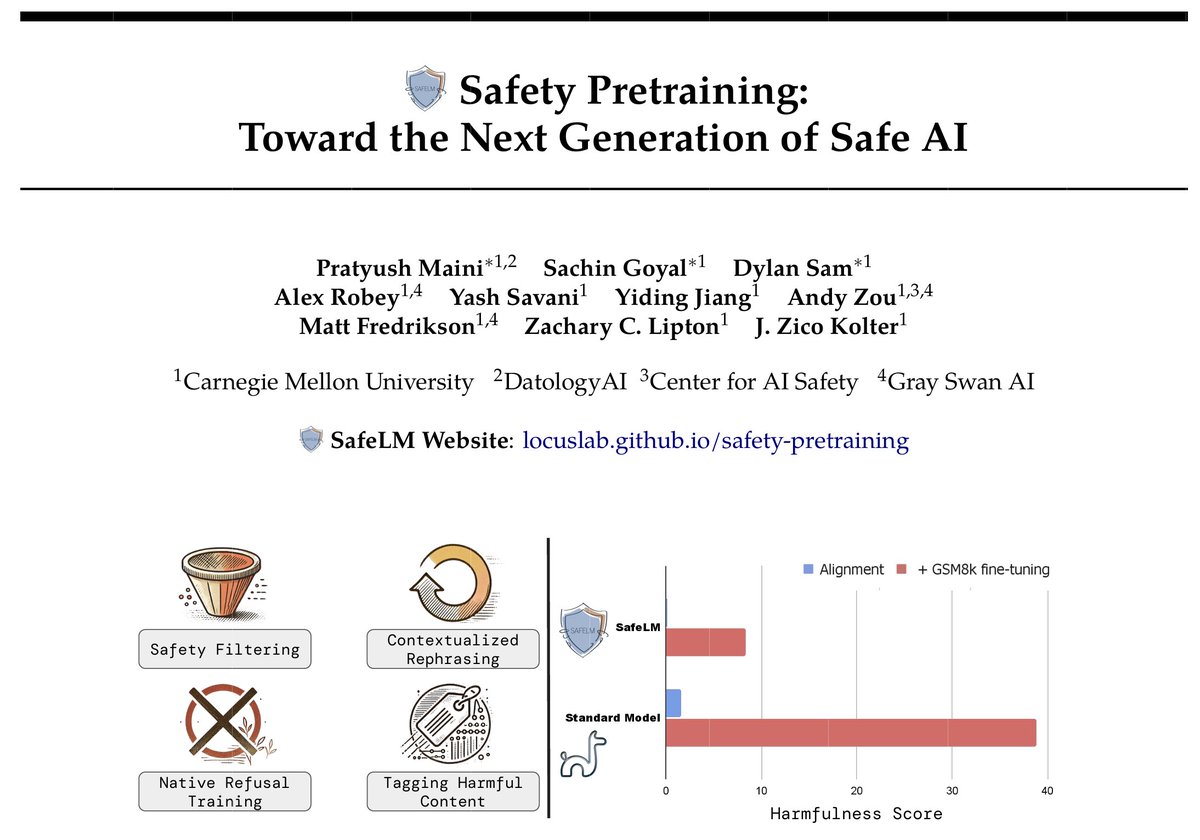
🚨 Super excited to finally share our Safety Pretraining work — along with all the artifacts (safe data, models, code)! In this thread 🧵, I’ll walk through our journey — the key intermediate observations and lessons, and how they helped shape our final pipeline.
🚨 Super excited to finally share our Safety Pretraining work — along with all the artifacts (safe data, models, code)! In this thread 🧵, I’ll walk through our journey — the key intermediate observations and lessons, and how they helped shape our final pipeline.

The new OpenAI paper “Why Language Models Hallucinate” is more like PR than research. The claim that hallucinations arise because training/evaluation reward guessing over abstaining is decades-old (reject option classifiers, selective prediction).
1/Excited to share the first in a series of my research updates on LLM pretraining🚀. Our new work shows *distilled pretraining*—increasingly used to train deployable models—has trade-offs: ✅ Boosts test-time scaling ⚠️ Weakens in-context learning ✨ Needs tailored data curation

🤖 Some company just released a new set of open-weight LLMs well-suited for your production environment. However, you suspect that the models might be trained with backdoors or other hidden malicious behaviors. Is it still possible to deploy these models worry-free? (1/7)

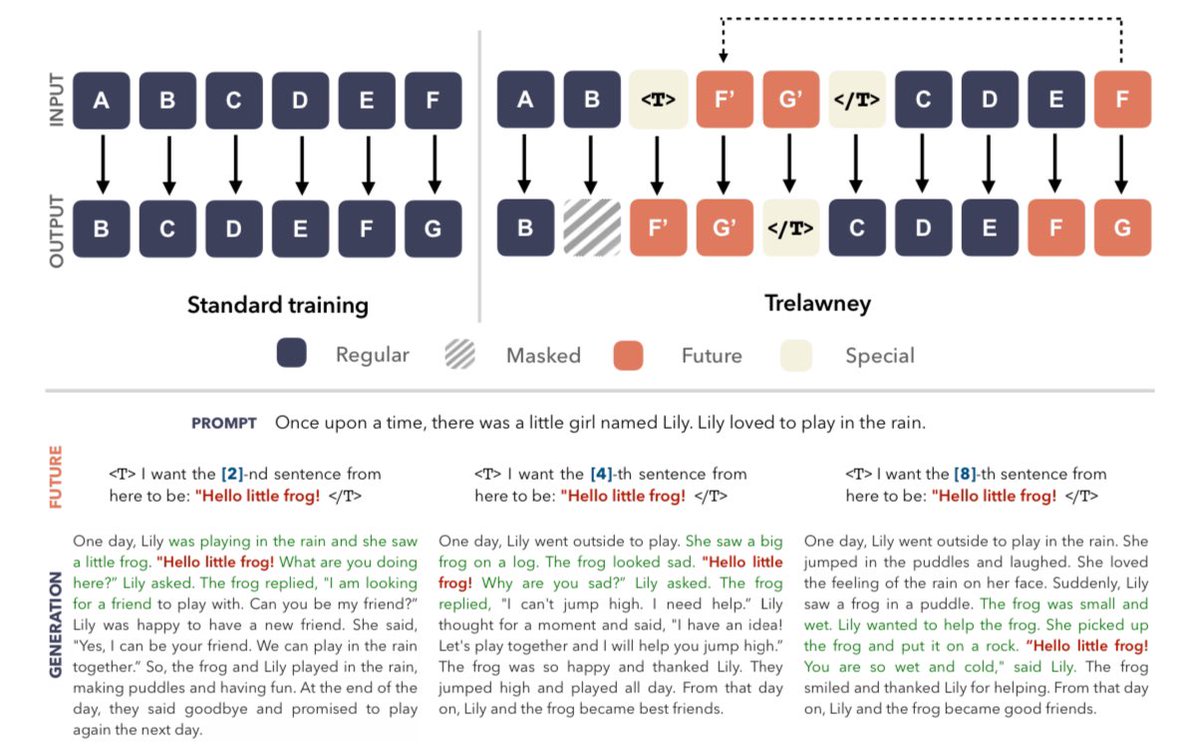
@abitha___ will be presenting our work on training language models to predict further into the future beyond the next token and the benefits this objective brings. x.com/gm8xx8/status/…

@abitha___ will be presenting our work on training language models to predict further into the future beyond the next token and the benefits this objective brings. x.com/gm8xx8/status/…
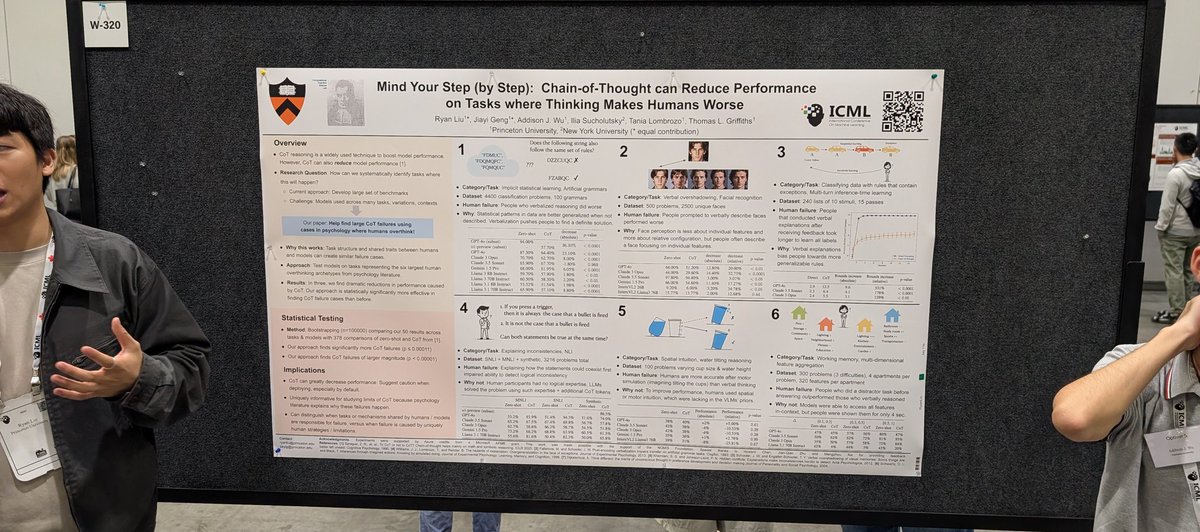
In "Mind Your Step (by Step): Chain‑of‑Thought can Reduce Performance on Tasks where Thinking Makes Humans Worse", we connect human "overthinking" insights to LLM reasoning, offering a new lens on when thinking‑out‑loud backfires. 📄 Read the full paper: arxiv.org/abs/2410.21333…

In "Mind Your Step (by Step): Chain‑of‑Thought can Reduce Performance on Tasks where Thinking Makes Humans Worse", we connect human "overthinking" insights to LLM reasoning, offering a new lens on when thinking‑out‑loud backfires. 📄 Read the full paper: arxiv.org/abs/2410.21333…

Zixin Wen @Zixin_Wen
488 Followers 654 Following PhD student @mldcmu, working on the theory of deep learning.
FAHMIDA AFRIN @Fahmida_Afrin_
0 Followers 57 Following CSE undergrad | Interested in NLP, LLM safety & security | Aspiring researcher
rebecca yu @reb_yu
125 Followers 208 Following phd @mldcmu | bme/cs ‘21 @johnshopkins | co-founder @jhuwmw
annamaneni sriharsha @harsha0806
215 Followers 5K Following
Teachable Machine @TeachableAI
114 Followers 544 Following All the latest AI research in plain english

combin8 @combin8or
46 Followers 369 Following

Pranav Deshmukh @violetflyweight
22 Followers 1K Following Undergrad at IIT Guwahati || Major in ECE with minors in AI

vita says🐬 @vitsviii
1K Followers 2K Following PhD Philosophy @ IITI | thinking about belief revision | informed by living exp of mental illness| MA Philosophy, JNU; BSc Physics MH, DU|

Varun Yerram @varunyer
743 Followers 1K Following PhD'ing @NYUDataScience | Ex @GoogleDeepMind | IITG
Abhilasha Ravichander @lasha_nlp
4K Followers 2K Following Research in Natural Language Processing (#NLProc) Incoming assistant prof @mpi_sws_ Postdoc @uwnlp | PhD @SCSatCMU @LTIatCMU Accepting PhD students/interns
Gavin Brown @gavinrbrown1
606 Followers 715 Following Assistant Professor at @WisconsinCS. Machine learning, privacy, and memorization. Postdoc @uwcse and PhD at Boston University.
Daniel P Jeong @danielpjeong
158 Followers 417 Following PhD student @mldcmu @SCSatCMU + intern @AbridgeHQ | ML for Healthcare | Previously @MSFTResearch, @columbia, @nasajpl
Ravindra @jaju
833 Followers 978 Following Ultracrepidarian. Generalist specialist. Problem delver, solver, toolsmith, simplicity lover. Did I say, ultracrepidarian?
Raj Krishnan V @raj_krishnan_v
240 Followers 2K Following Clinical AI • Robustness • LLM Eval • KDD’25 @GenAIEval • Building diagnostic trust in agentic models • Embedding To Diagnosis: https://t.co/xqS5Fo9gUN
Mehar Bhatia @bhatia_mehar
1K Followers 2K Following PhD student at @Mila_Quebec @mcgillu 👩🎓|| @McGill_NLP @UBC_NLP || Prev: @UBC_CS Vancouver || Studying societal impacts of AI, alignment and safety

Nikhil Raghuraman @nikraghuraman
265 Followers 1K Following Research @MistralAI | Prev @JaneStreetGroup, @StanfordAILab | DMs open.
johnny samuel @johnnys96666474
45 Followers 714 Following MSc @CMU_Africa/@CMUEngineering | Exploring Vision x Language x Security | Focused on Computer Vision, HealthTech, and Cybersecurity
Robert Scoble @Scobleizer
543K Followers 24K Following The best from ML/AI community | Ex-Microsoft, Rackspace, Fast Company | Wrote eight books about the future | Silicon Valley robots, holodecks, BCIs, & startups.
Akanksha Sachan @sachan1akanksha
175 Followers 690 Following PhD student @CMUPittCompBio | ML for Mol Bio | Cell fate reprogramming enthu | prev ChemEng ‘22 @iitbombay

Ziqian Zhong @fjzzq2002
632 Followers 470 Following AI interp & alignment @CSDatCMU, prev @MIT @pika_labs
kj frost @jkjfrost
0 Followers 4K Following
BM building AI @BMAIengineer
81 Followers 5K Following University student. Trying to build. Networking. Interests in AI Research,startups,software,CS and emerging technologies.
Konstantin Dobler @konstantdobler
152 Followers 282 Following ML Intern @apple, ELLIS PhD student @hpi_de in NLP, prev @instadeepai @sap | Multilingual LLMs, tokenizers, embeddings
cnsodano @cnsodano_
9 Followers 593 Following Currently working on forensic metascience & reproducibility in biomedical research Prev: non-invasive brain stimulation & sleep spindle detection @NeuroStimCtr
Aldo Munaretto @aldomunaretto
127 Followers 399 Following

Gaotang Li @GaotangLi
81 Followers 177 Following Ph.D. @UofIllinois | Undergrad @UMich. Language Models.
Rahel Jhirad @RahelJhirad
2K Followers 8K Following Founder, Imaginator ai knowledge discovery 2D navigation TS ML DL recsys econ math incentives mech design finance networks bridges boundaries, Time, 3d type
Pulkit Gopalani @GopalaniPulkit
93 Followers 836 Following PhD candidate @UMichCSE | prev. @IITKanpur
Aniket Vashishtha @AniketVashisht8
789 Followers 910 Following Working on Causality and LLMs | MSCS @IllinoisCDS | Prev Research Fellow @MSFTResearch
abderrahim zine @abderrahimzine6
46 Followers 3K Following
Sarath Chandra @tinfw
24 Followers 752 Following
Jeongwhan Choi @jeongwhan_choi
615 Followers 1K Following Postdoc @ KAIST | Ph.D. @ Yonsei University https://t.co/RoadwMfV6R
Eva Louise Marie Gabr... @e681554349
11 Followers 7K Following


Dung Doan @dungdx34
333 Followers 7K Following
Varun Talwar @vt_65
21 Followers 6K Following

Akshit @akshitwt
3K Followers 718 Following assessing ai capabilities. mlmi @cambridge_uni. previously @precogatiiith, @iiit_hyderabad. futurebound.
Satvik Dixit @SatvikDixit9
128 Followers 912 Following MS student @CarnegieMellon | Prev @IITDelhi | Audio understanding and generation


Robin Jia @robinomial
4K Followers 888 Following Assistant Professor @CSatUSC | Previously Visiting Researcher @facebookai | Stanford CS PhD @StanfordNLP
Aditi Raghunathan @AdtRaghunathan
3K Followers 31 Following Assistant professor at CMU @SCSatCMU @CSDatCMU | Machine learning
Aniket Vashishtha @AniketVashisht8
789 Followers 910 Following Working on Causality and LLMs | MSCS @IllinoisCDS | Prev Research Fellow @MSFTResearch
Matthieu Meeus @matthieu_meeus
240 Followers 569 Following PhD student @ImperialCollege Privacy/Safety + AI https://t.co/UBo5kgRqbU
Souradip Chakraborty @SOURADIPCHAKR18
2K Followers 5K Following Student Researcher @GoogleResearch || PhD @umdcs @ml_umd, working on #LLM #Alignment #RLHF #Reasoning Prev : #Google #JPMC #Walmart Labs,

Isadora White @isadorcw
371 Followers 331 Following PhD at @ucsd_cse| Prev Berkeley CS & Math Undergrad | LLM Agent Interactions, Multi-Agent and Multi-Turn RL
Sashrika Pandey @sashrika_
151 Followers 168 Following ai @figma, prev human-ai interaction @berkeley_ai iclr paper ➡️ https://t.co/Y832o3BxBB
Naveen Raman @NaveenJRaman
101 Followers 289 Following Machine Learning PhD @CarnegieMellon | Previously Churchill Scholar @Cambridge_Uni @UofMaryland | AI + Decision Making for social good
Wayne Chi @iamwaynechi
463 Followers 200 Following CS Ph.D. at @SCSatCMU. Funded by @NDSEG Fellowship. Editor at https://t.co/kBygvj9Puy. @MSFTResearch over Summer
Leena Mathur @lmathur_
1K Followers 1K Following PhD student @SCSatCMU, SR @GoogleDeepMind, @NSF fellow. Multimodal AI, social intelligence, & robotics. prev research @RobustAI, @USC, @Caltech, @EPFL

Emmy Liu @_emliu
1K Followers 510 Following PhD student @LTIatCMU, working with @gneubig on NLP || intern @AIatMeta || UofT ‘21 🇨🇦 ||🤖✨🔡

Jason Lee @jasondeanlee
18K Followers 4K Following Associate Professor at UC Berkeley. Former Research Scientist at Google DeepMind. ML/AI Researcher working on foundations of LLMs and deep learning.
Daniel Fried @dan_fried
4K Followers 865 Following Assistant prof. @LTIatCMU @SCSatCMU. Working on NLP: LLM agents, language-to-code, applied pragmatics, grounding.
Jiayi Geng @JiayiiGeng
1K Followers 210 Following PhD @LTIatCMU | MSE @Princeton_nlp @PrincetonPLI @cocosci_lab @PrincetonCS. Working on Multi-agent / Cognitive science & LLMs
Harbani Jaggi @harbanijaggi
220 Followers 167 Following E2E Autonomy @AppliedInt || researcher @berkeley_ai || president @berkeleyml || prev researcher @nasaames

Shuyan Zhou @shuyanzhxyc
3K Followers 826 Following assistant professor @dukecompsci | past: research lead @AIatMeta computer use agent, phd @LTIatCMU
Vidhi Jain @viddivj
4K Followers 3K Following Researcher at @OpenAI. Previously PhD at @CMU_Robotics, @GoogleDeepMind Robotics. @MetaAI, @IndiaMSR.
Anjali Kantharuban @anjali_ruban
568 Followers 134 Following PhD in Language Technology @ CMU, working on NLP for Dialects | Formerly @ Cambridge & UC Berkeley

Jing Yu Koh @kohjingyu
6K Followers 366 Following Computer use agents lead @ Meta Superintelligence Labs; on leave from ML PhD @CarnegieMellon. Prev: multimodal research @GoogleAI. Opinions my own. 🇸🇬
Yutong (Kelly) He @electronickale
930 Followers 408 Following PhD student @mldcmu, I’m so delusional that doing generative modeling is my job
Chris Cundy @ChrisCundy
2K Followers 224 Following Research Scientist at FAR AI. PhD from Stanford University. Hopefully making AI benefit humanity. Views are my own.

Zhili Feng @zhilifeng
622 Followers 919 Following Research @OpenAI | prev: ML PhD @mldcmu | Research intern: @MSRNE, @Amazon, @BoschGlobal
Bogdan Ionut Cirstea @BogdanIonutCir2
2K Followers 3K Following Automated/strongly-augmented AI safety research. Past: AI safety independent research and field-building - ML4Good, AGISF; ML academia (PhD, postdoc).
CLS @ChengleiSi
5K Followers 4K Following PhDing @stanfordnlp & Chilling @FutureHouseSF | teaching language models to do research

Anikait Singh @Anikait_Singh_
566 Followers 815 Following PhD'ing @StanfordAILab @stanfordnlp. Previously @MSFTResearch @ToyotaResearch @GoogleDeepMind @Berkeley_AI https://t.co/Qz5IOlI3fN
Fan Zhou @FaZhou_998
1K Followers 837 Following Qwen Coding @Alibaba_Qwen. Prev: Core member @XLangNLP, Intern @MSFTResearch.

Xuhui Zhou @nlpxuhui
1K Followers 678 Following PhD student @LTIatCMU. SWEing Socially-aware SWE agents @allhands_ai. Previously, @allen_ai, @UWNLP, @Apple, @UCBerkeley; Social Intelligence in language +X.

Chen Wu @ChenHenryWu
621 Followers 598 Following phd student @cmu_robotics | prev. undergrad @tsinghua_uni
Sumukh Aithal @sumukhaithal6
224 Followers 1K Following AI Scientist at Mistral AI | Past: MSML @ CMU
Sukjun (June) Hwang @sukjun_hwang
3K Followers 308 Following ML PhD student @mldcmu advised by @_albertgu
Mathieu @miniapeur
34K Followers 2K Following Non-member of the technical staff in a non-frontier lab. Gradient surfer by day, Möbius stripper by night. PhD @ai_ucl.

Ao Zhang @zhanga6
675 Followers 175 Following Ph.D student @NUSingapore. Core contributors of GR00T N1, MiniCPM-V, NExT-Chat. Research on MLLMs.
Pradeep Ravikumar @RavikumarPrad
415 Followers 121 Following Professor, Machine Learning @ CMU; co-Editor-in-Chief, Journal of Machine Learning Research (JMLR); Third-wave AI

Paul Liang @pliang279
8K Followers 710 Following Assistant Professor MIT @medialab @MITEECS @nlp_mit || PhD from CMU @mldcmu @LTIatCMU || Foundations of multisensory AI to enhance the human experience.
Ben Eysenbach @ben_eysenbach
5K Followers 0 Following Prof @ Princeton CS working on AI/ML/RL. 🦋@ https://t.co/hz4KZsv5iOTrends for United States
You might like










