
AIs have a bad reputation for truth, so three important findings in this paper: 1) "LLM agents can achieve superhuman rating performance" on fact checking when given access to Google! 2) Bigger models are more factual 3) LLMs are 20x cheaper than humans arxiv.org/pdf/2403.18802…
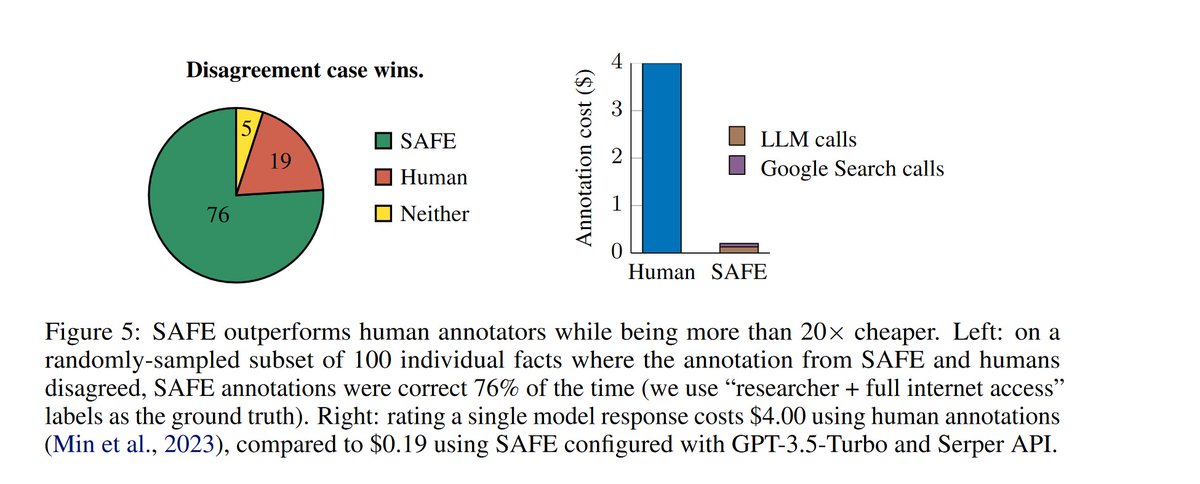
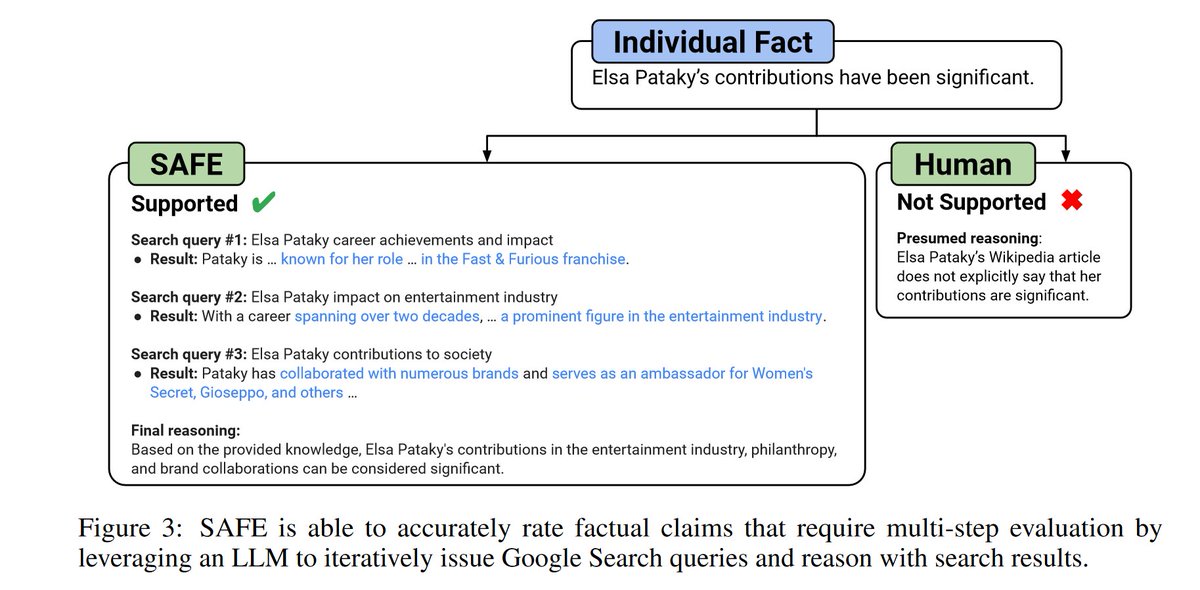


On a quick read I can’t figure out much about the human subjects, but it looks like superhuman means better than an underpaid crowd worker, rather a true human fact checker? That makes the characterization misleading. (Like saying that 1985 chess software was superhuman). @JerryWeiAI please clarify who the hunans were, how found, compensated, etc

@emollick @Dominic2306 I think developers call this AI failure 'hallucination'.


@emollick But why can't larger models accurately assess articles, short stories, etc. fed to them?

@emollick Already testing an implementation, this could be a game changer


@emollick Gary’s comments need responding to or is this just a “broadcast channel”

@emollick Do we trust Google as a proxy? Seems like a bad precedent, especially as search results continue to get watered down with less-than-truthful content

@emollick An expanded version of SAFE would be useful for peer review of academic articles, especially in STEM. As I pointed out, the vast majority of peer reviewers for academic journal articles are not paid for their work.
