
Jerry Wei @JerryWeiAI
🧐 Improving and aligning large language models 🧠 Research Engineer @GoogleDeepMind ⏰ Past: @Stanford, @Google Brain jerrywei.net Stanford, California Joined June 2015-
Tweets177
-
Followers5K
-
Following252
-
Likes125
Cool piece from the Financial Times comparing hallucinations in LLMs to hallucinations in humans! People often complain about how LLMs frequently hallucinate, but it’s easy to forget that humans hallucinate a lot as well. For example, if you read some article and then later tell…
More exciting news today -- Gemini 1.5 Pro result is out! Gemini 1.5 Pro API-0409-preview now achieves #2 on the leaderboard, surpassing #3 GPT4-0125-preview to almost top-1! Gemini shows even stronger performance on longer prompts, in which it ranks joint #1 with the latest…
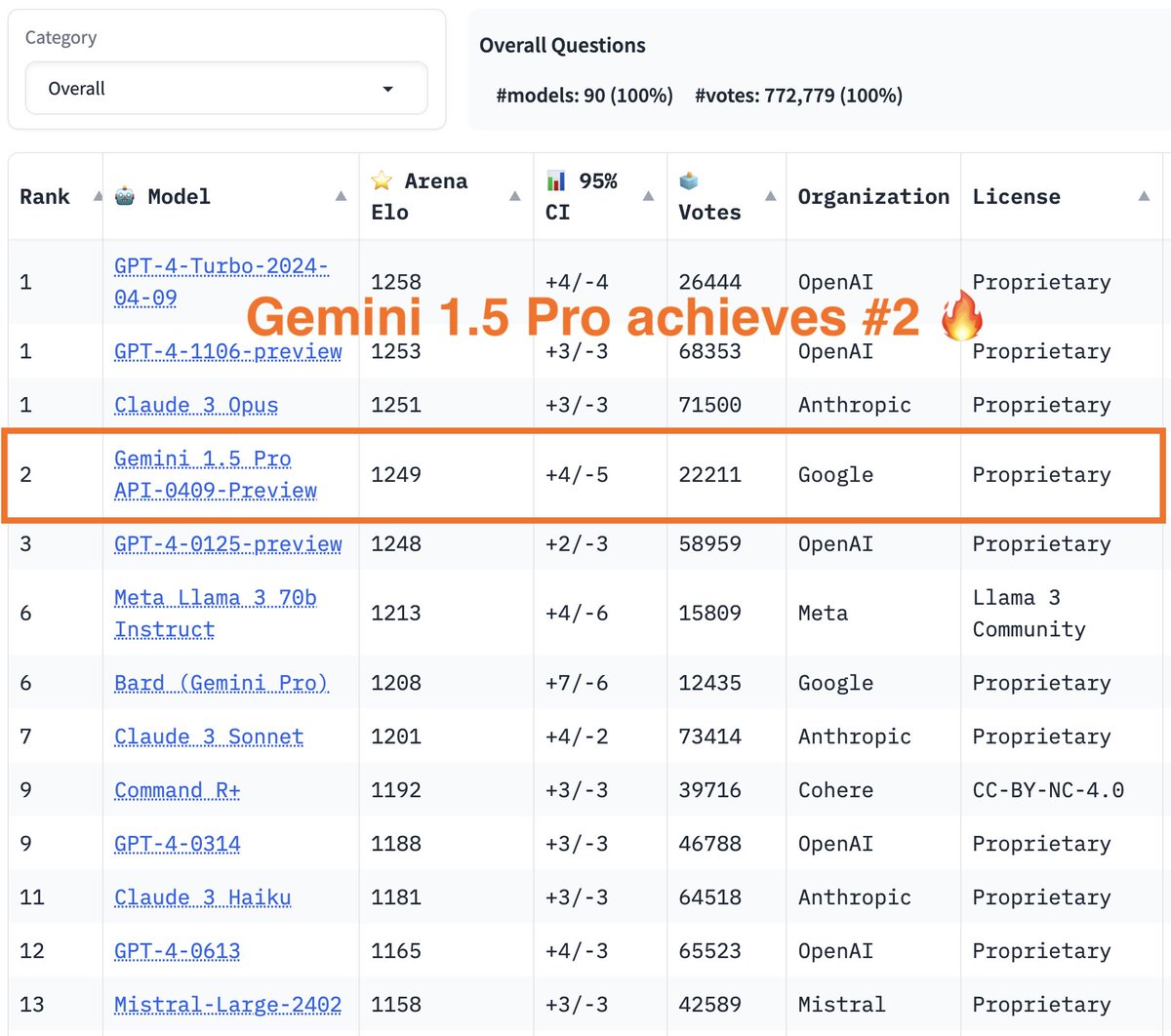
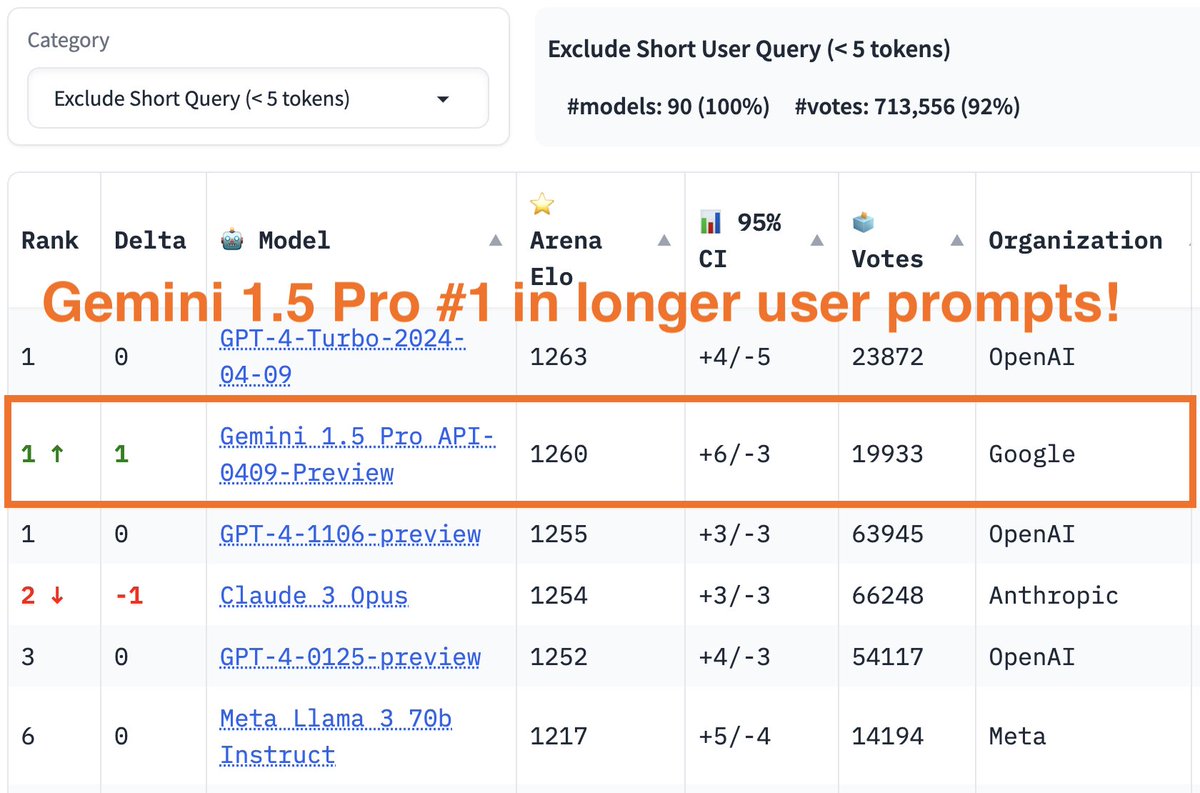
More exciting news today -- Gemini 1.5 Pro result is out! Gemini 1.5 Pro API-0409-preview now achieves #2 on the leaderboard, surpassing #3 GPT4-0125-preview to almost top-1! Gemini shows even stronger performance on longer prompts, in which it ranks joint #1 with the latest… https://t.co/IvrwwMRhkU
Huge congrats to @YiTayML and the rest of the Reka team for this launch! Personally, I'm super impressed with how Reka-Core can match/beat GPT-4-Turbo and Claude-3-Opus on many benchmarks despite Reka being a much smaller team. Also "as for Belebele, we hit our credit threshold…
Huge congrats to @YiTayML and the rest of the Reka team for this launch! Personally, I'm super impressed with how Reka-Core can match/beat GPT-4-Turbo and Claude-3-Opus on many benchmarks despite Reka being a much smaller team. Also "as for Belebele, we hit our credit threshold…

Our @RekaAILabs Tech Report / Paper is out! 🔥 Tech reports with completely no information are kinda boring so we’re revealing some interesting information on how we train our series of Reka models including tokens, architecture, data & human evaluation workflows. 😃 We tried…

We present a survey of synthetic data approaches for LLMs, highlighting both where it's needed and its potential pitfalls! It'll make a great weekend read. Thanks to: @RuiboLiu @JerryWeiAI @denny_zhou and our other collaborators.

We present a survey of synthetic data approaches for LLMs, highlighting both where it's needed and its potential pitfalls! It'll make a great weekend read. Thanks to: @RuiboLiu @JerryWeiAI @denny_zhou and our other collaborators.

Best Practices and Lessons Learned on Synthetic Data for Language Models Great overview by Google DeepMind on synthetic data research. It covers applications, challenges, and future directions This is an important paper given the significant advancements we are seeing from the…

Fun fact: our paper was put on hold by arxiv for a while because arxiv detected that we used the phrase "time travel," which is a topic that arxiv frequently gets bad submissions for. When we Ctrl-F'd "time travel" in our paper, we had actually just cited a paper called "Time…

Fun fact: our paper was put on hold by arxiv for a while because arxiv detected that we used the phrase "time travel," which is a topic that arxiv frequently gets bad submissions for. When we Ctrl-F'd "time travel" in our paper, we had actually just cited a paper called "Time…


Best Practices and Lessons Learned on Synthetic Data for Language Models The success of AI models relies on the availability of large, diverse, and high-quality datasets, which can be challenging to obtain due to data scarcity, privacy concerns, and high costs.

There has been growing concerns about running out of high-quality training data for LLMs, and naturally many turn towards synthetic data to help remedy this issue. Indeed, synthetic data can be generated at large scales and is thus a valuable resource for training/evaluating…
There has been growing concerns about running out of high-quality training data for LLMs, and naturally many turn towards synthetic data to help remedy this issue. Indeed, synthetic data can be generated at large scales and is thus a valuable resource for training/evaluating…
Google presents Best Practices and Lessons Learned on Synthetic Data for Language Models Provides an overview of synthetic data research, discussing its applications, challenges, and future directions arxiv.org/abs/2404.07503
Thanks for this insightful feedback! Clarified these points in a revision: 1. Replaced "superhuman" with "outperforms crowdsourced human annotators" to not imply beating expert humans 2. Added FAQ sec. discussing this distinction 3. Updated related work/SAFE with prior methods
Thanks for this insightful feedback! Clarified these points in a revision: 1. Replaced "superhuman" with "outperforms crowdsourced human annotators" to not imply beating expert humans 2. Added FAQ sec. discussing this distinction 3. Updated related work/SAFE with prior methods
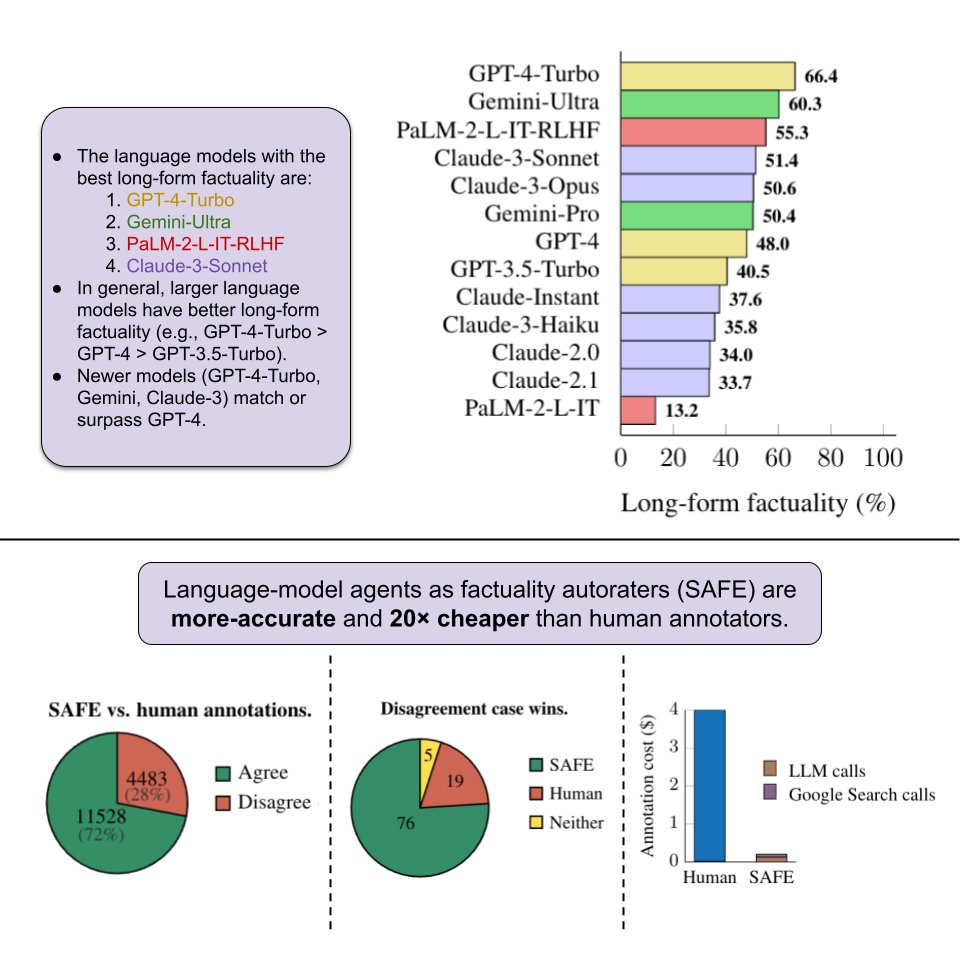
This is one of the core surprising findings of our paper - previous efforts in using LLMs for evaluation primarily seek to achieve high correlation with human annotations. But we took a closer look at the data and noticed that human raters were not super reliable in fact…
This is one of the core surprising findings of our paper - previous efforts in using LLMs for evaluation primarily seek to achieve high correlation with human annotations. But we took a closer look at the data and noticed that human raters were not super reliable in fact…
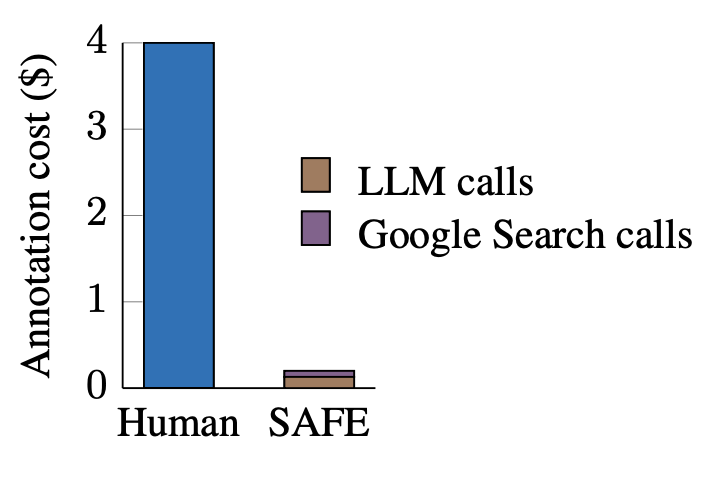
We focus on long-form factuality in open domain, and so we show an entire evaluation pipeline with dataset + autorater + metric. The dataset was generated with LLMs and the autorater is an LLM agent with Google Search, demonstrating LLMs can rate themselves better than humans!
We focus on long-form factuality in open domain, and so we show an entire evaluation pipeline with dataset + autorater + metric. The dataset was generated with LLMs and the autorater is an LLM agent with Google Search, demonstrating LLMs can rate themselves better than humans!

Our new efforts is trying to address an elephant in the room for LLM: Given factuality/hallucination is so critical to the success of LLM, is there a quantitive evaluation to benchmark all existing LLMs in general? Hope our benchmark would be adopted and benchmarked as part of…
Our new efforts is trying to address an elephant in the room for LLM: Given factuality/hallucination is so critical to the success of LLM, is there a quantitive evaluation to benchmark all existing LLMs in general? Hope our benchmark would be adopted and benchmarked as part of…
New factuality research! We use LMs as annotators & search engines for grounding to create a realistic benchmark for evaluating long-form factuality. Simulating your daily queries to LMs about knowledge & truth. 🔍📊 #NLProc #FactChecking Check this out! 👇
New factuality research! We use LMs as annotators & search engines for grounding to create a realistic benchmark for evaluating long-form factuality. Simulating your daily queries to LMs about knowledge & truth. 🔍📊 #NLProc #FactChecking Check this out! 👇

New work on evaluating long form factuality 🎉. Our method SAFE combines google search and LLM queries to extract and verify individual claims in responses. Most excitingly, we show SAFE is cheaper💰 and more reliable ✅ than human annotators.
New work on evaluating long form factuality 🎉. Our method SAFE combines google search and LLM queries to extract and verify individual claims in responses. Most excitingly, we show SAFE is cheaper💰 and more reliable ✅ than human annotators.

JOURNEY OF IDEAS @ONLYWORK0
93 Followers 3K Following
Jayashri @jayashri94
63 Followers 2K Following Likes to read about technology, AI and almost everything. #Python,#React,#Typescript.
Kartik Natarajan @kartiknatarajan
209 Followers 1K Following

kobciye films @KobciyeF13403
41 Followers 170 Following
Zhaowei Wang @ZhaoweiWang4
726 Followers 673 Following PhD student @HKUSTKnowComp | Supervised by @yqsong | Intern @NVlDlAAl | Linguistic Entailment & Abstraction | Causal Inference
HolyDifficult @HolyDifficult
10 Followers 155 Following
Block Chen @GPT327
377 Followers 3K Following @RUCerofChina. Founder&CEO of DeepWond AI. AI Research&Safety. AI game&Metaverse.


Yi Su @YiSu37328759
387 Followers 618 Following Researcher @GoogleDeepmind. Phd from @Cornell. Working on contextual bandits, reinforcement learning and their applications in user interactive systems.acidoom @acidoom
93 Followers 964 Following
Rongduan Zhu @RongduanZhu
33 Followers 326 Following
Siva Worajitwanakul @Champiionnii
11 Followers 61 Following
Ittseta @IssEossda
79 Followers 674 Following

simrat hanspal @simsimsandy
84 Followers 454 Following Exploring LLMs | Data scientist with a curious engineering mind

Yichen Gong @YichenGong123
2 Followers 29 Following
waoirk @waoirk
3 Followers 122 Following




Phillip Lindsay @EastLAPinche
61 Followers 421 Following
K @karimedl
0 Followers 402 Following

Nikhil Khandekar @nsk7153
0 Followers 155 Following
Jabez Magomere @jabez_magomere
74 Followers 400 Following PhD @UniofOxford researching on NLP for Automated Fact Checking and Factuality in LLMs. Previously shipped code 🚀@TwigaFoods. Happens to run fast sometimes.🏃
JonnieLewandoski @JonnieL29718
42 Followers 1K Following
soonwoo @JohnSwkwon
1 Followers 40 Following

Nate Boyd @n8boyd
695 Followers 2K Following Invest in and help build deep tech & AI startups ~ dad & partner ~ curious & skeptical
Ansong Ni @AnsongNi
1K Followers 384 Following Final-year PhD student @Yale, #NLProc, LLM for Code. (ex-)intern @GoogleDeepMind, @MetaAI, @MSFTResearch, @allen_ai. MS from @SCSatCMU. Opinions are my own.


Fabian @schimpffabian
74 Followers 708 Following Futures in which AI is the greatest thing ever are possible but not unavoidable.
Shreya Roy @ShreyaR54107751
2 Followers 59 Following I'm a Data Scientist with a degree in Computational Data Science from Indian Institute of Science, Bangalore. I'm passionate about social change, animal welfare


Segmond Yunsai @ysegmond
324 Followers 611 Following Interests:- wrenching old bmws vROOOM, programming vRAAAM
sachosdev @sachoslks
43 Followers 1K Following Trying to be a game developer. sachosdev on Google Play Store. Go check some of my games out!
Cecilia-Z @zzzfffc
1 Followers 72 Following
Saul @Saul31962301
23 Followers 111 Following
carlos daniel @animex400
4 Followers 50 Following
SecrtAgntSquirl @SecrtAgntSquirl
586 Followers 3K Following I don’t really know what to put here. I mostly research AI/technology and spend time with my husband/pets. Pics are 7-8 yrs old, I don’t rly take selfies. Sry.

Note Able @curiousgangsta
372 Followers 3K Following
Corey Lynch @coreylynch
10K Followers 1K Following AI at @figure_robot, previously research scientist at @GoogleDeepMind.
Melody Guan ʕᵔᴥ�.. @MelodyGuan
3K Followers 780 Following


lmsys.org @lmsysorg
38K Followers 172 Following Large Model Systems Organization. We created Vicuna and Chatbot Arena! Compare 30+ LLMs (GPT-4/Claude/Llamas) side-by-side at https://t.co/IDFeIDIOtm
François Chollet @fchollet
470K Followers 769 Following Deep learning @google. Creator of Keras. Author of 'Deep Learning with Python'. Opinions are my own.
Lilian Weng @lilianweng
95K Followers 148 Following Working on AI safety, past on robotics, applied research @OpenAI; Writing ML blogs to help myself & others to learn; Ideas my own.
bilal2vec @bilaltwovec
2K Followers 781 Following ✨ research engineer • prev @googlebrain @cohere @dbrxmosaicai • se @uwaterloo
Dani Yogatama @DaniYogatama
4K Followers 196 Following CEO @RekaAILabs, Associate Professor @CSatUSC
Nat McAleese @__nmca__
3K Followers 306 Following Superalignment by models helping humans help models help humans at OpenAI. Previously @DeepMind. Views my own.
Dan Hendrycks @DanHendrycks
17K Followers 81 Following • Director of the Center for AI Safety (https://t.co/ahs3LYCpqv) • GELU/ImageNet-C/MMLU/safety groundwork • PhD in AI from UC Berkeley https://t.co/rgXHAnYAsQ https://t.co/YtGtDh1aAV
David Krueger @DavidSKrueger
13K Followers 4K Following Cambridge faculty - AI alignment, deep learning, and existential safety. Formerly Mila, FHI, DeepMind, ElementAI, AISI.
Junyang Lin @JustinLin610
5K Followers 1K Following Chief Evangelist Officer of Qwen Team & OpenDevin, building LLM and LMM. Now @Alibaba_Qwen . Previously @PKU1898 LANCO group. ❤️ 🍵 ☕️ 🍷 🥃
Salesforce AI Researc.. @SFResearch
13K Followers 118 Following #SalesforceAI advances state-of-the-art #AI techniques that pave the path for innovative products at Salesforce. Focus areas include #ML, #NLP, #AIforGood
rohan anil @_arohan_
12K Followers 2K Following Principal Engineer, @GoogleDeepMind Gemini. prev PaLM-2. Tinkering with optimization and distributed systems. opinions are my own.

Machel Reid @machelreid
2K Followers 1K Following Research Scientist @GoogleDeepMind Working on LLMs on the Gemini Team; did gemini 1.5 pro
Jan Leike @janleike
44K Followers 322 Following ML Researcher, co-leading Superalignment @OpenAI. Optimizing for a post-AGI future where humanity flourishes.
Steven Zheng @HuaixiuZheng
172 Followers 60 Following Trained in quantum computing and quantum physics, LLM research in Google DeepMind
Robert Dadashi @robdadashi
2K Followers 388 Following reinforcement learning research @GoogleDeepMind, built RLHF layer of Bard and Gemma
Maarten Sap (he/him) @MaartenSap
5K Followers 645 Following Working on #NLProc for social good. Currently at @LTIatCMU, previously at @UWNLP, @MSFTResearch, and @allen_ai. 🏳🌈
Sharan Narang @sharan0909
2K Followers 254 Following LLMs and AI Research (Llama 2 & 3 lead) @Meta | ex @Google (PaLM lead, T5), ex @Baidu (Deep Speech 2, Sparse Neural Networks), ex @Nvidia

Allen Nie (🇺🇦�.. @Allen_A_N
1K Followers 1K Following Stanford CS PhD working on RL, Education, and NLP. Advised by Emma Brunskill and Chris Piech. Ex @stanfordsymsys. @StanfordAILab 2023 summer @MSFTResearch
Desh Raj @rdesh26
3K Followers 2K Following Research Scientist @Meta (AI Speech) | Previously: @jhuclsp, @IITGuwahati

Marc Andreessen 🇺�.. @pmarca
1.4M Followers 24K Following Techno-optimist. E/acc. Technology brother. Move Fast and Make Things. p(Doom) = 0; p(“1984”) = not 0.

Jarrod Kahn @kahnvex
346 Followers 174 Following Chip hog @GoogleDeepMind. Bard Research Tool Use lead. Prev: TPU hoarder at @YouTube, recommender systems @VEVO. Opinions my own.
Greg Durrett @gregd_nlp
6K Followers 752 Following CS professor at UT Austin. I do NLP most of the time. he/him
trieu @thtrieu_
2K Followers 241 Following thinking about thinking. created alphageometry, darkflow. prev: nyu, google brain/deepmind

Language Technologies.. @LTIatCMU
9K Followers 233 Following The Language Technologies Institute in Carnegie Mellon University's @SCSatCMU
Ben Holfeld @BenHolfeld
89K Followers 32K Following SF AI Studio Lead @Accenture, partnering with @OpenAI @Google @Microsoft. Pianist. German Quantum Physicist. Creator of the Nth Floor. Views are my own. x/acc.

Tri Dao @tri_dao
19K Followers 365 Following Incoming Asst. Prof @PrincetonCS, Chief Scientist @togethercompute. Machine learning & systems.
Yisong Miao @YisongMiao
585 Followers 1K Following 4th Year PhD Student at @wing_nus @nuscomputing. Studying discourse and emojis with a focus on interpretability of LMs . @Charles_Leclerc will win WDC.
Nouha Dziri @nouhadziri
3K Followers 676 Following Research Scientist @allen_ai / @ai2_mosaic, PhD in NLP/Dialogue 🤖 UofA. Ex Visiting researcher @Mila_Quebec Ex Research intern at @GoogleDeepMind @MSFTResearch
Lucas Beyer (bl16) @giffmana
56K Followers 446 Following Researcher (Google DeepMind/Brain in Zürich, ex-RWTH Aachen), Gamer, Hacker, Belgian. Mostly gave up trying mastodon as [email protected]
Arthur Mensch @arthurmensch
40K Followers 874 Following Co-founder and CEO @MistralAI. Apply https://t.co/yHGRZAtjcx
Horace He @cHHillee
24K Followers 449 Following Working at the intersection of ML and Systems @ PyTorch "My learning style is Horace twitter threads" - @typedfemale
Chelsea Finn @chelseabfinn
69K Followers 384 Following Asst Prof of CS & EE @Stanford. PhD from @Berkeley_EECS, EECS BS from @MIT

Yao Fu @Francis_YAO_
14K Followers 2K Following PhD @EdinburghNLP on LLMs and Machine Reasoning. Ex. @Columbia @PKU1898 @MITIBMLab @allen_ai AGI has yet to come, so keep running


Han @hhua_
3K Followers 4K Following Invest @GVteam during 🌞 and hacker at 🌒. Investing in AI, infra, deep tech, fintech/crypto ⚡️🤖🧠. Views are my own.

Chris Olah @ch402
91K Followers 173 Following Reverse engineering neural networks at @AnthropicAI. DMs open! Previously @distillpub, OpenAI Clarity Team, Google Brain. Personal account.
Wenhu Chen @WenhuChen
11K Followers 520 Following AI researcher @UWaterloo @GoogleAI @VectorInst. Interested in natural language processing, diffusion models. I direct TIGER-Lab at UWaterloo.@JerryWeiAI A bit different but I found the inspiration behind this paper interesting: x.com/omarsar0/statu…
Visualization-of-Thought Elicits Spatial Reasoning in LLMs Inspired by a human cognitive capacity to imagine unseen worlds, this new work proposes Visualization-of-Thought (VoT) prompting to elicit spatial reasoning in LLMs. VoT enables LLMs to "visualize" their reasoning…
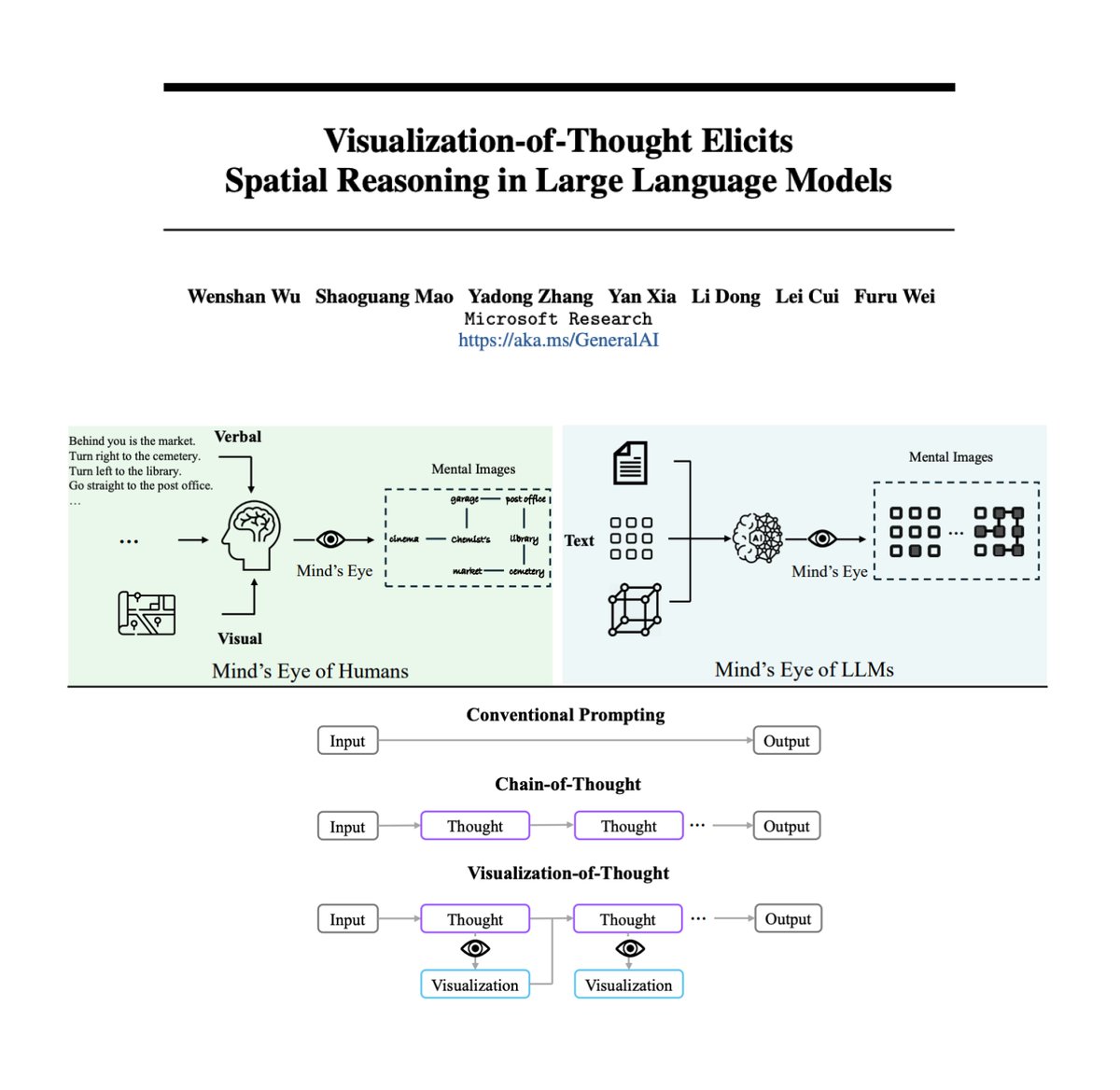
@JerryWeiAI Nice share! A deeper understanding of the two might lead to better ideas to improve LLMs. I have seen several papers (even simple prompting ones) borrowing ideas from cognition. I really enjoy this type of research. And of course, your paper on long-form factuality was quite…
Cool piece from the Financial Times comparing hallucinations in LLMs to hallucinations in humans! People often complain about how LLMs frequently hallucinate, but it’s easy to forget that humans hallucinate a lot as well. For example, if you read some article and then later tell…

nothing gets my heart rate up like waiting for eval results on new models to come in
@hyhieu226 Thanks Hieu. Whenever GPUs died we took out stashes of paper and did backprop by hand. Works very well!
Huge congrats to @YiTayML and the rest of the Reka team for this launch! Personally, I'm super impressed with how Reka-Core can match/beat GPT-4-Turbo and Claude-3-Opus on many benchmarks despite Reka being a much smaller team. Also "as for Belebele, we hit our credit threshold…
Our @RekaAILabs Tech Report / Paper is out! 🔥 Tech reports with completely no information are kinda boring so we’re revealing some interesting information on how we train our series of Reka models including tokens, architecture, data & human evaluation workflows. 😃 We tried…
Our @RekaAILabs Tech Report / Paper is out! 🔥 Tech reports with completely no information are kinda boring so we’re revealing some interesting information on how we train our series of Reka models including tokens, architecture, data & human evaluation workflows. 😃 We tried…
We present a survey of synthetic data approaches for LLMs, highlighting both where it's needed and its potential pitfalls! It'll make a great weekend read. Thanks to: @RuiboLiu @JerryWeiAI @denny_zhou and our other collaborators.
Thanks Aran for sharing our work! This is a survey paper I’ve been thinking about for a long time, as we have seen an increasing need for synthetic data. As we will probably run out of fresh tokens soon, the audience of this paper should be everyone who cares about AI progress.
@JerryWeiAI Style nit: def should_put_on_hold(paper: str) -> bool: return 'time travel' in paper
This is true haha. So for anyone who has an ArXiv submission "on-hold" for unclear reasons: Please double check whether you have keywords such as "time travel" in your text. This is another lesson we have learned. 😆😆😆
Fun fact: our paper was put on hold by arxiv for a while because arxiv detected that we used the phrase "time travel," which is a topic that arxiv frequently gets bad submissions for. When we Ctrl-F'd "time travel" in our paper, we had actually just cited a paper called "Time…
Fun fact: our paper was put on hold by arxiv for a while because arxiv detected that we used the phrase "time travel," which is a topic that arxiv frequently gets bad submissions for. When we Ctrl-F'd "time travel" in our paper, we had actually just cited a paper called "Time…
Google presents Best Practices and Lessons Learned on Synthetic Data for Language Models Provides an overview of synthetic data research, discussing its applications, challenges, and future directions arxiv.org/abs/2404.07503
Best Practices and Lessons Learned on Synthetic Data for Language Models Great overview by Google DeepMind on synthetic data research. It covers applications, challenges, and future directions This is an important paper given the significant advancements we are seeing from the…
There has been growing concerns about running out of high-quality training data for LLMs, and naturally many turn towards synthetic data to help remedy this issue. Indeed, synthetic data can be generated at large scales and is thus a valuable resource for training/evaluating…
Thanks Aran for sharing our work! This is a survey paper I’ve been thinking about for a long time, as we have seen an increasing need for synthetic data. As we will probably run out of fresh tokens soon, the audience of this paper should be everyone who cares about AI progress.
Best Practices and Lessons Learned on Synthetic Data for Language Models The success of AI models relies on the availability of large, diverse, and high-quality datasets, which can be challenging to obtain due to data scarcity, privacy concerns, and high costs.
Thanks Aran for sharing our work! This is a survey paper I’ve been thinking about for a long time, as we have seen an increasing need for synthetic data. As we will probably run out of fresh tokens soon, the audience of this paper should be everyone who cares about AI progress.
Google presents Best Practices and Lessons Learned on Synthetic Data for Language Models Provides an overview of synthetic data research, discussing its applications, challenges, and future directions arxiv.org/abs/2404.07503
Google presents Best Practices and Lessons Learned on Synthetic Data for Language Models Provides an overview of synthetic data research, discussing its applications, challenges, and future directions arxiv.org/abs/2404.07503
Flan2 paper is now on JMLR, 1.5 years after the initial arXiv release. It already feels quite dated, reflecting how fast the field is moving. That said Flan-T5 series is still going strong, with an astonishing 52M cumulative downloads 🤯 How are people using these models?
Thanks for this insightful feedback! Clarified these points in a revision: 1. Replaced "superhuman" with "outperforms crowdsourced human annotators" to not imply beating expert humans 2. Added FAQ sec. discussing this distinction 3. Updated related work/SAFE with prior methods
This is a cool method, but "superhuman" is an overclaim based on the data shown. There are better datasets than FActScore for evaluating this: ExpertQA arxiv.org/abs/2309.07852 by @cmalaviya11 +al Factcheck-GPT arxiv.org/abs/2311.09000 by Yuxia Wang +al (+ same methodology) 🧵
Trends for United States
You might like












