
Next, I present the intuitions that occur, note that it does not have to be just the one. It could be that all are part of the reason, and some explain more of the improvement we see than others.
1⃣The first intuition is quite undeniable. Many optimizers approximate traits by a rolling average. An average needs a bit of data to be reliable. In extreme averaging 0 batchs, we essentially have SGD. Example: Adam’s momentum approximates average direction by previous steps
2⃣Consider an untrained network (pretrained) to be on the peak of the loss mountain. First updates would be large, fast down the steep mountain. We don’t want to make those too large with our learning rate. Cold
After a few steps we get closer to a plataue. This is the place where large learning rates help the most. A lot of distance to pass, no fine tunings needed. Getting warmer.
Right, but why would that be the case? Well, who knows. Regardless of why, this paper, suggests it is the case. (maybe authors have more intuitions?) @jmgilmer @_ghorbani Ankush Garg @snehaark @bneyshabur @dcardoza @GeorgeEDahl @zacharynado @orf_bnw arxiv.org/abs/2110.04369
3⃣A repeating intuition focuses on the pretrained weights (#NLProc but general #MachineLearning too recently). We worked hard for a good initialization for most layers. But not all, at the end you add a fresh layer, e.g. FC for BERT (unless you use seq2seq like T5).
If you init just the last layer, it needs more tuning then the rest. Supposedly, warmup slowly adapts it to a lot of data (more stable), the top would change but the bottom less so.
While this may be the case, I find it a bit hard to understand why gradual change would change less than non-gradual one. But even so,
If different learning rates across layers is the problem, a better solution would be to do just that (adam has different learning rates, so back to 1). or totally freeze the pretrained models at first. Hey Tweeps do that remove the need for warmup? x.com/ananyaku/statu…

If different learning rates across layers is the problem, a better solution would be to do just that (adam has different learning rates, so back to 1). or totally freeze the pretrained models at first. Hey Tweeps do that remove the need for warmup? x.com/ananyaku/statu…
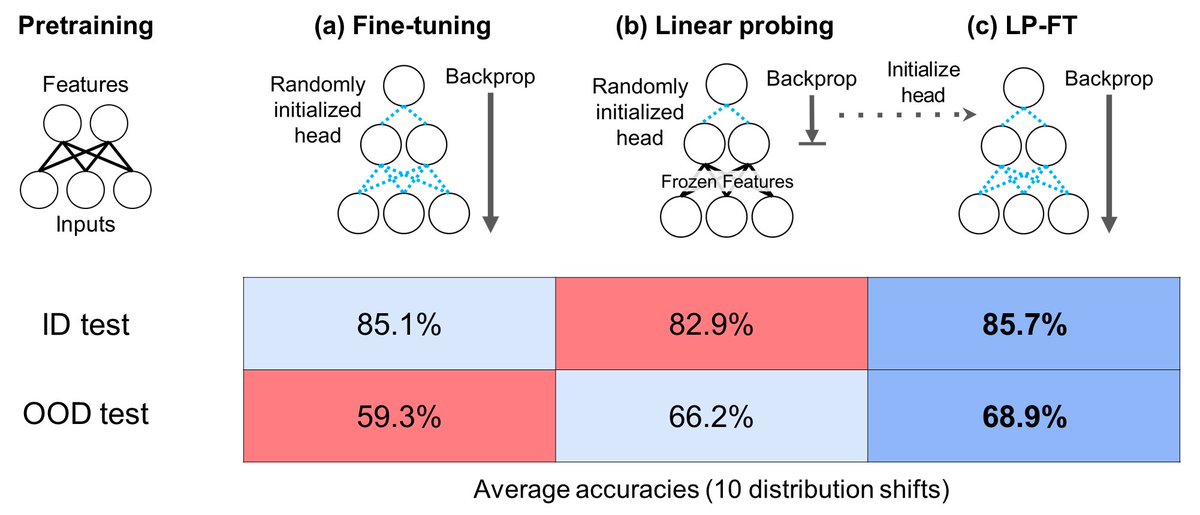

@LChoshen This is sometimes done, it's called layer-wise learning rate decay. For example BeiT and MAE do this.
@LChoshen Sorry, by "this" I mean the gradually smaller lr as we go away from the head.