
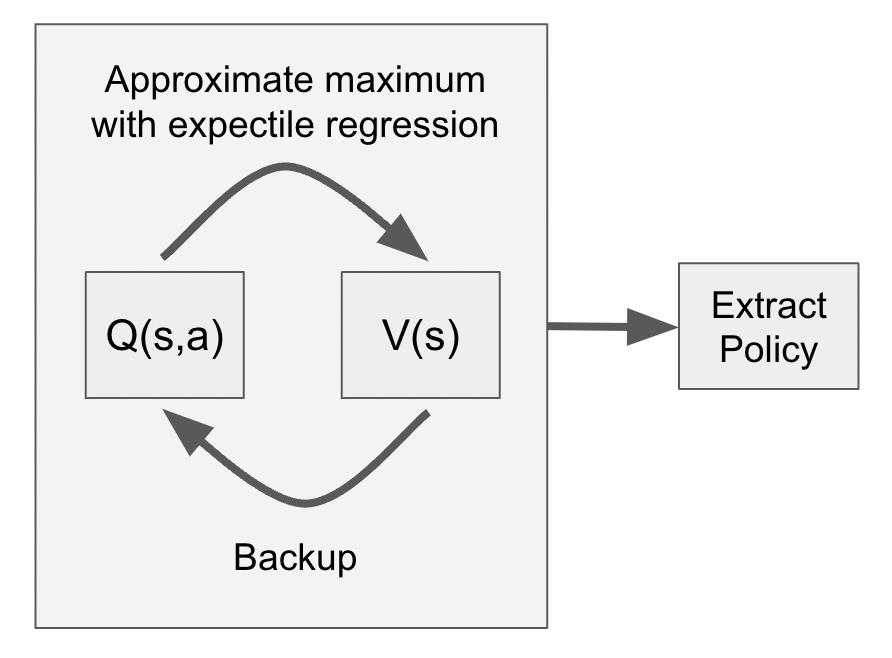
Excited to present our work with @ashvinair and @svlevine, Offline RL with Implicit Q-Learning (IQL), a simple method that achieves SOTA performance on D4RL arxiv.org/abs/2110.06169 and works 4x faster than prior SOTA github.com/ikostrikov/imp… Thread below

@ikostrikov @ashvinair @svlevine Congrats, looks really simple to implement and effective! Any plans to benchmark it on RLUnplugged? Would love to see a comparison to offline MuZero (arxiv.org/abs/2104.06294)
@ankesh_anand @ashvinair @svlevine Is there a simple D4RL-style wrapper for the datasets? I can try.
@ikostrikov @ashvinair @svlevine Not the same API, but there seems to be a wrapper (github.com/deepmind/deepm…). @caglarml would know best!

@ikostrikov @ankesh_anand @ashvinair @svlevine The CQL codebase had support for Atari experiments too (based on Dopamine though): github.com/aviralkumar290…