
Daily ML Tips @Daily_ML_Tips
Daily ML Tips from a Graduate student to help streamline your learning experience and spread knowledge without borders. Joined July 2019-
Tweets39
-
Followers571
-
Following159
-
Likes27


If you don’t understand this, I am no longer your friend.


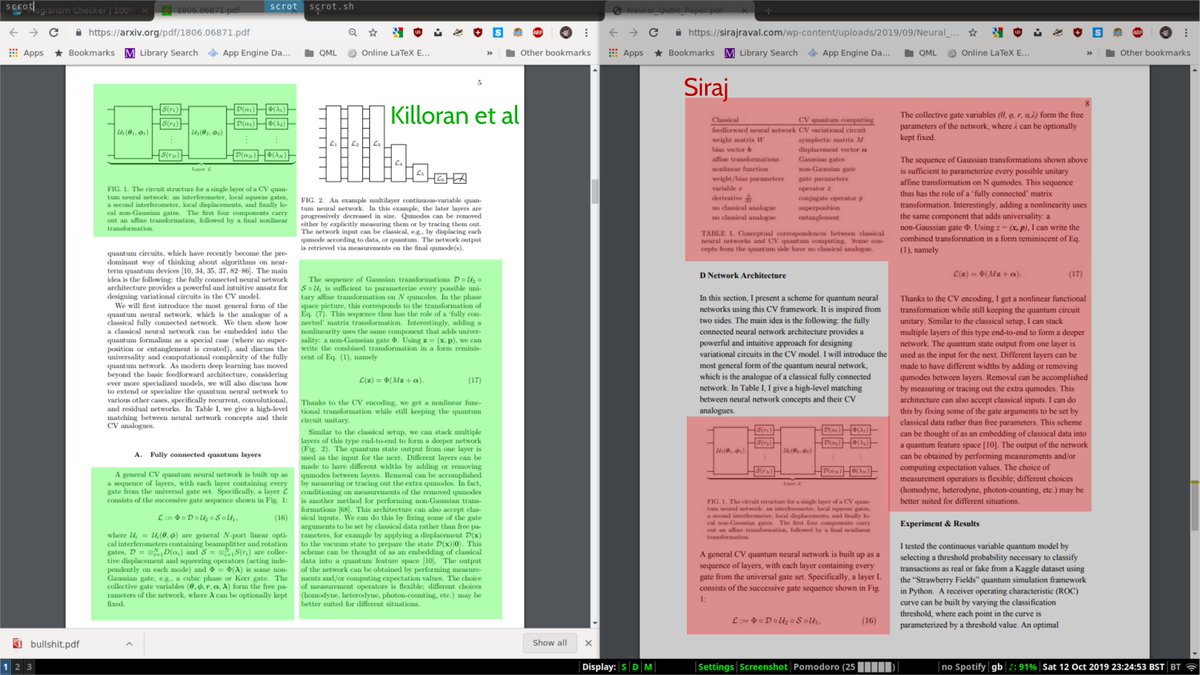
So in @sirajraval's livestream yesterday he mentioned his 'recent neural qubit paper'. I've found that huge chunks of it are plagiarised from a paper by Nathan Killoran, Seth Lloyd, and co-authors. E.g., in the attached images, red is Siraj, green is original

@sirajraval Hey @esa, you're due to have this guy run a workshop soon. You should probably rethink that cosmos.esa.int/web/esac-stats…
Got a large dataset which takes many hours of training. A method I used to quickly get a prototype, is sampling the data and creating a model that over-fits. Then, once ready, i provide the rest of the data. Saves time and money. Thoughts? *take caution with domain
Why would you want to use dimensionality reduction techniques? Dimensionality reduction can allow you to: • Speed up training by reducing the number of features • Reduce memory usage • Identify latent features that impact multiple features
Who's tired of hyper parameter tuning? If you aren't, you're lying! Search methods are the best way to find params without putting in too much of the effort that comes with hyper parameter tuning. RandomSearchCV, GridSearchCV, GeneticSearchCV are some which can help you. :)
Not all tasks need neural networks, its surprising how many current business cases can be solved with other ML techniques as well as GROUPBY statements.
What new with Sci-Kit Learn? They finally have an API for plotting :') exciting times!

Want to access all of NumPys functionality without importing it? With Pandas you can. This breaks the norm but is a fun trick ;)

This is amazing.
What projects are you guys working on right now? Trying any new techniques? :)
Unfortunately data sets with vague column names exist and dealing with them can get frustrating without proper documentation. Not anymore. By passing a Dict obj to the DataFrame.rename() function, you can tailor the data set as you like and make analysis fun. :)

Something different. People have DM'd asking for some general python tips too. There is a misconception that to be good at coding you have to know all functions. IMO, you should know how to apply functions no matter the language, use dir() or help() to look up functions.

Ever wanted to quickly analyze data you saw online or somewhere not as accessible. pandas offers the read_clipboard() functions which allows you to make a data frame with ease. From the screenshot you'll see I had data in Excel which I copied (Ctrl + C). :)

Following on from the previous memory management post, Chunks. By passing the argument chunksize we can split our input data into chunks to avoid loading a large file into memory. Note the change in the type() of both our data frames and the shape of our data frames. Enjoy :)



STEPHEN MAINA @STEPHENMAI9792
4 Followers 46 Following


Ishika Bansal @Ishikaban
1 Followers 32 Following
Seauseson @seauseson48329
3 Followers 584 Following The fragrance of rice flowers tells of a good harvest, and the sound of frogs sounds.
MrHobbo221 @hobbo221
20 Followers 1K Following Fly on the wall who likes to listen to people smarter than him.
Saurabh Raghuvanshi @saw_raghu
0 Followers 15 Following

Alif smile @alippcx01
0 Followers 9 Following
Αmr Eℓ Mamlouk🔻 @CODEX400
993 Followers 1K Following Software Engineer | .NET | Muslim 🇵🇸 وللحريةِ الحمراءِ بابٌ...بكل يد مضرجةٍ يُدقُّ

IK @the_karve
43 Followers 442 Following Proud Dad 🧔 | Engineer 🔧 | Biker 🏍 | Global Thinker 🌐 | Music Lover 🎶 | Pun Enthusiast 😄 | ML-AI Pro 🤖 | Naval Vet ⚓️ #TechPassion #ProudIndian


John Hughes @jplhughes
477 Followers 325 Following Independent Alignment Researcher contracting with Anthropic on scalable oversight and adversarial robustness. I also work part-time at Speechmatics.
Ahmed Idrissi @aiyagh
48 Followers 976 Following


The Explorers @TheExplorers__
31 Followers 440 Following Next-gen online metaverse. Explore, play and have fun with your friends🪐

SA @Subha29500077
31 Followers 855 Following
attilanagy234 @attilanagy234
24 Followers 208 Following

Gao @Gao82273693
13 Followers 52 Following
Sheetal Srivastava @9sleepingsheep
66 Followers 687 Following She/her. Data Scientist. Basic lifeform with acidic thoughts.
Riverside @Riversi34149362
5 Followers 145 Following
visarga @visarga
430 Followers 1K Following Intelligence evolves socially, like DNA. It's all just search, all the way down.
Mark Trovinger @MarkTrovinger
43 Followers 341 Following Software Engineer who loves data, machine learning and generally making machines smarter. Forever chasing the 1RM.
Mohd Kashif @MohdKas63651002
5 Followers 47 Following Technische Universität München (Msc. Informatik 2021-current)

Mada @mada_57
8 Followers 351 Following

Jay Zhou @zgjhust
2 Followers 68 Following
Oren Kalinsky @okalinsk
9 Followers 75 Following
vishakha @_vishakha_a
212 Followers 3K Following working on ai x-risk, serial garden starter, building community for friends





Ronak Jain @Ronakk_jain
133 Followers 580 Following Data Scientist || Writer || Applied Researcher || Trader #DataAnalytics #DeepLearning #Tech #Computervision #Startups #Business #AI


Anudeep @AnudeepVanjavak
299 Followers 1K Following Passionate about AI, analytics, and finding hidden patterns in data 🌌 | Let's connect and collaborate!
youssefzidan @youssefzidan
19 Followers 87 Following In heaven, all the interesting people are missing.
xuiqzy @xuiqzy
14 Followers 878 Following
Fikrie 。フィク�... @iamfikrie
1K Followers 557 Following Always have faith in Him. Tak pernah sempurna. Life, politics, movies & sports
Andrej Karpathy @karpathy
1.4M Followers 1K Following Building @EurekaLabsAI. Previously Director of AI @ Tesla, founding team @ OpenAI, CS231n/PhD @ Stanford. I like to train large deep neural nets.
François Chollet @fchollet
576K Followers 818 Following Co-founder @ndea. Co-founder @arcprize. Creator of Keras and ARC-AGI. Author of 'Deep Learning with Python'.
Yann LeCun @ylecun
956K Followers 765 Following Professor at NYU. Chief AI Scientist at Meta. Researcher in AI, Machine Learning, Robotics, etc. ACM Turing Award Laureate.

Google DeepMind @GoogleDeepMind
1.2M Followers 279 Following We’re a team of scientists, engineers, ethicists and more, committed to solving intelligence, to advance science and benefit humanity.
Grant Sanderson @3blue1brown
414K Followers 362 Following Pi creature caretaker. Contact/faq: https://t.co/brZwdQfdif
Soumith Chintala @soumithchintala
253K Followers 1K Following Cofounded and lead @PyTorch at Meta. Also dabble in robotics at NYU. AI is delicious when it is accessible and open-source.
PyTorch @PyTorch
454K Followers 77 Following Tensors and neural networks in Python with strong hardware acceleration. PyTorch is an open source project at the Linux Foundation. #PyTorchFoundation
nixCraft 🐧 @nixcraft
386K Followers 624 Following Love Linux/Unix, open source, and programming? Into Sysadmin & DevOps? Follow us! Boost your IT career with daily new tools, apps, and humor ⤵️
Andrew Ng @AndrewYNg
1.3M Followers 1K Following Co-Founder of Coursera; Stanford CS adjunct faculty. Former head of Baidu AI Group/Google Brain. #ai #machinelearning, #deeplearning #MOOCs
AI at Meta @AIatMeta
717K Followers 288 Following Together with the AI community, we are pushing the boundaries of what’s possible through open science to create a more connected world.
Harrison Kinsley @Sentdex
95K Followers 301 Following gpus and tractors Neural networks from Scratch book: https://t.co/hyMkWyUP7R https://t.co/8WGZRkUGsn

Sander Dieleman @sedielem
64K Followers 2K Following Research Scientist at Google DeepMind (WaveNet, Imagen, Veo). I tweet about deep learning (research + software), music, generative models (personal account).
Stefan Denner @stefan_denner
108 Followers 242 Following @ELLISforEurope PhD Student @DKFZ, @UniHeidelberg and @Cambridge_Uni. Working on dataset curation and limitations in medical imaging.
Matt☂️ @Matt__Kachow
610 Followers 1K Following
Comet @Cometml
15K Followers 884 Following Comet provides an end-to-end model evaluation platform for AI developers, with best in class LLM evaluations, experiment tracking, and production monitoring

稚菜 @xiyenanase94
2K Followers 800 Following
Berkeley AI Research @berkeley_ai
228K Followers 379 Following We're graduate students, postdocs, faculty and scientists at the cutting edge of artificial intelligence research.

Ali Bakhtiari @arbakhtiari
4 Followers 89 Following
lol @Fengoku
67 Followers 104 Following
Albert Folch @AlbertFolchG
43 Followers 652 Following
Baptiste Robert @fs0c131y
256K Followers 5K Following CEO @PredictaLabOff | French Security Researcher, Ethical Hacking, OSINT
Eklavya @Eklavya_FCB
401 Followers 603 Following Sic Parvis Magna. Blocked by both @cesc4official and @JohnTerry26.

Benjamin Isaacoff @bpisaacoff
230 Followers 478 Following scientist | policy wonk | space enthusiast/ASHO | podcaster | journal editor | underseas and over mountains | he/him
Roy Leibov @royleibov
1 Followers 51 Following
Yee Whye Teh @yeewhye
25K Followers 1K Following Find me @[email protected] Professor at @OxCSML, @oxfordstats and Research Director at @GoogleDeepMind. All opinions are my own.
Ronit Jorvekar @RJorvekar
36 Followers 571 Following I like developing softwares that scale. Student AI Researcher @ USC ICT
Andreas Werner @Timur27931
7 Followers 245 Following
Andrew Vincent @andrewvincent7
159 Followers 621 Following

TEDxMaastricht @TEDxMaastricht
3K Followers 3K Following The official account of TEDxMaastricht. Watch our latest videos on https://t.co/VO4AQv1vUo
Abi Aryan @GoAbiAryan
7K Followers 3K Following 🛠️ Founder @AbideAI 👐 ML Engineer 👩💻☕ 📚 Book Author: LLMOps (2025), ✍️ GPU Engg for AI Systems (2026) 💬🐦 Talk to me about LLMs, MLSys & GPU Training
Nidal @imleslahdin
2K Followers 2K Following What's the Kolmogorov Complexity / Minimum Description Length of a Reasoning Language Model? LLMs, AI/ML, Data Science. PhD student. 🇹🇳➡️🇺🇸


ℝafał G @Ivegot99introns
178 Followers 2K Following 'There are days that define your story beyond your life... like the day they arrived'
Oscar Loureiro @loureiroo
210 Followers 2K Following At the intersection of Data, Education, Equity as a goal, and family
Devi Parikh @deviparikh
26K Followers 211 Following Co-CEO @yutori_ai. Join the waitlist at https://t.co/zD3StYi8db.
Kaggle @kaggle
306K Followers 284 Following Kaggle is the largest global AI community of developers, researchers, and enthusiasts who compete, collaborate, and benchmark what's next in AI.
DeepAI @DeepAI
54K Followers 2K Following Pioneers in generative AI. chat/image/video/music. you own outputs. $4.99/mo for DeepAI Pro cool research at @arxiv_daily For support email [email protected]

Surya Dantuluri @sdand
13K Followers 1K Following teaching computers to use computers, prev. #1 chatgpt plugin, #1 on polymarket
Aman Rusia @_amanrusia_
19 Followers 127 Following Machine Learning, Natural Language Processing, Scientific Computing @kombaico
arXiv Daily @Arxiv_Daily
49K Followers 2K Following Daily feed of this week's top research articles published to https://t.co/ULrW4yLt6n. AI Research Papers, Curated by @DeepAI
ilya alexander s. @ialexs
1K Followers 792 Following Obey gravity, it's the law. I twit about: Geo. Run. Linux. CLI. Ikkyo. + I DO NOT maintain my LinkedIn.
Zachary Lipton @zacharylipton
64K Followers 2K Following Cofounder & CTO: @AbridgeHQ, Professor: CMU/@acmi_lab, Creator: @d2l_ai & https://t.co/QQt98VNLUp, Relapsing 🎷
Maruan Al-Shedivat @alshedivat
1K Followers 417 Following ML @ Genesis Therapeutics | Ex-@OpenAI, Ex-@GoogleAI | PhD in ML from @CarnegieMellon (@mldcmu)
Ben Haines @bhainesva
59 Followers 197 Following I am a Shark. I have Shark playing cards. I have juggling clubs. I don't have juggling sharks. I know more about Canada than I need to. You'll never feel happy.
w @wlrdmlk
506 Followers 3K Following
Alex Federation @afederation
546 Followers 408 Following Co-founder, CEO of Talus Bio illuminating the regulome | controlling the genome | drugging the 'undruggable' #proteomics, #teammassspec, #chembio
Zitrone @ZitroneSimo
49 Followers 830 Following
Ben Lengerich @ben_lengerich
1K Followers 803 Following Asst Prof @UWMadison Stats, CS, Biomedicine. Research group: @AdaptInferLab. Founder: @IntelligibleAI Personal: Christian, husband, father.
Abhishek Naik @anaik96
512 Followers 217 Following PhD graduate in reinforcement learning from the University of Alberta. Now, RL research in space! 🚀🛰️Trends for United States
You might like













