
Preetum Nakkiran @PreetumNakkiran
ML research @Apple. @sh_reya’s fiancé | PhD @Harvard, postdoc @UCSanDiego, EECS @Berkeley_EECS, "AI" @OpenAI, @GoogleAI preetum.nakkiran.org Joined January 2013-
Tweets4K
-
Followers10K
-
Following2K
-
Likes10K

New initiative from @let4all - Office Hours! I (along with @thegautamkamath and Ellen Vitercik) will be holding bi-weekly office hours starting next week. Open to chat about research, navigating academic life, and anything else!

New initiative from @let4all - Office Hours! I (along with @thegautamkamath and Ellen Vitercik) will be holding bi-weekly office hours starting next week. Open to chat about research, navigating academic life, and anything else!


There is nothing wrong with making incremental but steady progress on a hard problem.
“Neurips-experiment proposal” track at Neurips please
currently treading the fine line between “natural abstraction” and “abstract nonsense”

“I’m not able to learn mathematics easily, I have to work. It takes a very long time and I have a terrible memory. I forget things. So I try to work, despite these handicaps, and the way I worked was trying to understand really well the simple things.” newscientist.com/article/242319…
tufte-latex is great because it lets me write footnotes that span the whole length of the page. as Tufte no doubt intended.
Soham & co have been doing a lot of cool stuff in the architecture/optimizer space! Really neat mix of theory & practice.

Soham & co have been doing a lot of cool stuff in the architecture/optimizer space! Really neat mix of theory & practice.

There'd be less brain drain if more schools enabled the sort of fundamental curiosity-driven research that should be academia's strength. If the only viable research style is make-number-go-up, you might as well do that at a company.

There'd be less brain drain if more schools enabled the sort of fundamental curiosity-driven research that should be academia's strength. If the only viable research style is make-number-go-up, you might as well do that at a company.
Q: Anyone know of a good treatment (even just heuristic) of the "numerical stability" of discretized Gaussian diffusion? Eg, a statement of the form "errors in (a) the score estimate, and (b) the discretization don't add up too badly"

Our team at #Apple is looking for interns to work on Large Language Models, especially on efficient continual training. Please email your CV, related papers/code, and your availability for a full-time internship to fartashATappleDOTcom.

Clément Canonne @ccanonne_
31K Followers 927 Following Senior Lecturer @Sydney_Uni. Postdocs @IBMResearch, @Stanford; PhD @Columbia. Converts ☕ into puns: sometimes theorems. He/him. @[email protected]
Gautam Kamath @thegautamkamath
44K Followers 505 Following Assistant Prof of CS @UWaterloo, Faculty @VectorInst, Canada @CIFAR_News AI Chair. Co-EiC @TmlrOrg. I lead @TheSalonML. Privacy, robustness, machine learning.
Rosanne Liu @savvyRL
33K Followers 966 Following Cofounded & running @ml_collective. Host of Deep Learning Classics & Trends. Research at Google DeepMind. DEI/DIA Chair of ICLR & NeurIPS. Writing https://t.co/IbycyGfnDR
Behnam Neyshabur @bneyshabur
18K Followers 689 Following Senior Staff Research Scientist @GoogleDeepMind, Interested in reasoning w. LLMs, traveling & backpacking
Dan Roy @roydanroy
45K Followers 2K Following ML / AI researcher, emphasis on theory. Research Director and Canada CIFAR AI Chair, @VectorInst Professor, @UofT (Statistics/CS)
Jelani Nelson @minilek
22K Followers 184 Following Professor @Berkeley_EECS. Research Scientist (part-time) @GoogleAI. Founder @addiscoder. 🇻🇮🇺🇸🇪🇹
Kyunghyun Cho @kchonyc
61K Followers 2K Following a combination of a mediocre scientist, a mediocre manager, a mediocre advisor & a mediocre PC at @nyuniversity (@CILVRatNYU) & @genentech (@PrescientDesign).
Boaz Barak @boazbaraktcs
17K Followers 418 Following Computer Scientist. See also https://t.co/EXWR5k634w, https://t.co/SEVX6it6z3 ( @[email protected] , boaz.barak in threads ). Opinions my own.
Eric Jang @ericjang11
69K Followers 3K Following physical AGI at 1X. Author of "AI is Good for You" https://t.co/eFg4WXhg0p
Shreya Shankar @sh_reya
39K Followers 589 Following I study ML & AI engineers and try to make their lives a little better. PhD-ing in databases & HCI @Berkeley_EECS @UCBEPIC and MLOps-ing around town. She/they.
Tom Goldstein @tomgoldsteincs
23K Followers 2K Following Professor at UMD. AI security & privacy, algorithmic bias, foundations of ML. Follow me for commentary on state-of-the-art AI.
rohan anil @_arohan_
12K Followers 2K Following Principal Engineer, @GoogleDeepMind Gemini. prev PaLM-2. Tinkering with optimization and distributed systems. opinions are my own.
Jonathan Frankle @jefrankle
16K Followers 685 Following Chief Scientist, Neural Networks @Databricks via MosaicML. PhD @MIT_CSAIL. BS/MS @PrincetonCS. DC area native. Making AI efficient for everyone at @DbrxMosaicAI
Zachary Lipton @zacharylipton
59K Followers 2K Following Professor: CMU/@acmi_lab, CTO / CSO: @AbridgeHQ, Creator: @d2l_ai & https://t.co/QQt98VNLUp, Relapsing 🎷
Eugene Vinitsky @EugeneVinitsky
13K Followers 2K Following Anti-cynic. Artificial narrow intelligence. Autonomous vehicles, multi-agent learning, and transportation. RS at Apple, Asst. Prof at @nyutandon. He/him.

Sara Hooker @sarahookr
39K Followers 7K Following I lead @CohereForAI. Formerly Research @Google Brain @GoogleDeepmind. ML Efficiency at scale, LLMs, @trustworthy_ml. Changing spaces where breakthroughs happen.

Gowthami Somepalli @gowthami_s
6K Followers 976 Following Grad student @UMDCS. Past: @AIatMeta, @AmazonScience, @IITMadras. Currently working on #Diffusion and #Multimodal understanding. GPU poor. She/her.
Ferenc Huszár @fhuszar
40K Followers 1K Following Secular Bayesian. Associate Professor in Machine Learning @Cambridge_CL. Talent aficionado at https://t.co/RbJkoLguey Alum of @Twitter, Magic Pony and @Balderton
Light @LightW3214
123 Followers 1K Following AI | Crypto | Equities - I believe in everything. I believe in you. WAKE UP!
Robonomous @realpolity101
2K Followers 2K Following controls,robotics & UAVs//Algos,CV//usual sh!tposter XD //
Jon Kelley @jonkell
457 Followers 3K Following Technology professional and musician with a love for philosophy, physics and economics.
Robert @bertran_yorro
187 Followers 102 Following Posts about machine learning, physics, blockchain. Currently R&D at @eigenlayer
Ricyves @ricyves6138
34 Followers 2K Following
Laura Cunningham @PaleoLaura
5K Followers 5K Following Biologist trained in the Grinnell field method, UC Berkeley. California Director Western Watersheds Project, B&RW, https://t.co/PgqZC9V2fW
Adrien Laurent 🇫�.. @alaurentg
171 Followers 958 Following



Harry Mayne @HarryMayne5
116 Followers 420 Following Interpretability @oiioxford @uniofoxford. PhD student. Previously @Cambridge_Uni

datapharma 🏳️.. @carolinajacoby
210 Followers 1K Following Pharmacist | Master's student in IT and health management | Future data engineer. 🇧🇷🏳️🌈


Giannis Daras @giannis_daras
4K Followers 399 Following Computer Science Ph.D. student, @UTAustin working with @AlexGDimakis. Research Scientist Intern @nvidia. Ex: @google, @explosion_ai, @ntua


Sophronia_ @Sophronia337285
20 Followers 2K Following
William , Engineer, C.. @whe3998
3K Followers 5K Following AI, ML,EV,ELON and MORE. NOT investment Advice.
Rajesh🇺🇸 🇮�.. @rajeshpv
27 Followers 591 Following
Arman Adibi @AdibiArman
488 Followers 2K Following Postdoc @Princeton | Ph.D. from @Penn, @WarrenCntrPenn | Studying machine learning and optimization.
mlecchaslayer156 @mlecchasla37448
97 Followers 3K Following
Harry Schuhmacher @harry_schuh
3K Followers 768 Following Beer and beverage journalist. Just personal stuff here. Beer industry tweets / IG / tiktok: @beerbizdaily BeerNet Radio: https://t.co/QCbdDXo8wP
Tirthbas Mishra @Dev_Explorerr
36 Followers 633 Following Code explorer, problem solver. Sharing insights, tips, and tech humor. Let's build something amazing together! 🚀💻🌟 #CodeLife #TechEnthusiast.
Gagan Jain @gaganjain1582
47 Followers 716 Following Predoc Researcher @GoogleDeepMind | IIT Bombay'22
Tanmay Dokania @DokaniaTanmay
1 Followers 24 Following
Gautam Singh @gautamsi11
135 Followers 624 Following PhD Student @RutgersCS advised by @SungjinAhn_ | Research Intern at NVIDIA. Unsupervised Structure Learning. Past: Amazon, IBM Research, IIT Guwahati.
Joey Zhou @JoeyZhouUT
16 Followers 101 Following CS PhD student at UT Austin. RT, likes and comments are all generated by evil AI.
Darnell Henry🧠 @darnell1henry
44 Followers 229 Following Software engineering, ASM\C++, .NET C#, Go, PHP, IT archaeology, gaming, math, computer science, scientific method #geek 📭
valerie @valstechblog
5 Followers 35 Following
Chris Aitken @chris_f_aitken
412 Followers 3K Following Economics PhD student. Interested in political economy, the media, and the use of ML for causal inference. Trying to do interesting things with interesting data
Yann @jancorazza
341 Followers 619 Following
赫菲斯托斯 @hephaestus93god
4 Followers 213 Following
Pradeep @prads
208 Followers 1K Following
Pensé FFun @inftyCategory
115 Followers 6K Following

Martin Shkreli (e/acc.. @MartinShkreli
166K Followers 3K Following https://t.co/lzin5ByH0t [email protected] https://t.co/oMIiyJcIzk https://t.co/DuU6MMqcgQ
Niket Patel @NiketPatel91154
0 Followers 23 Following
fotis iliopoulos @fotisiliop1438
11 Followers 36 Following
Elisabetta Cornacchia @Elisabetta68885
62 Followers 91 Following Postdoc at MIT in theoretical machine learning
Sahil Arora @SahilAr06512437
23 Followers 153 Following AI + drug discovery | geometric deep learning | generative protein modeling | Ordaos Bio
Mason Minot @MasonMinot
64 Followers 377 Following PhD Student ETH Zurich. Interested in ML and drug development. Previously @Genentech, @Cornell

Raphaël Millière @raphaelmilliere
10K Followers 2K Following Philosopher of Artificial Intelligence & Cog Science @Macquarie_Uni Past @Columbia @UniofOxford Also on other platforms Blog: https://t.co/2hJjfSid4Z
Ruidong Wu @RuidongWu
57 Followers 280 Following Researcher at @HelixonBio. Prev: @UofIllinois @MIT_CSAIL @Tsinghua_Uni.
utile_melassa @UMelassa
7 Followers 593 Following
JJ @yololulu_
7 Followers 106 Following
Yong-Hyun Park @hagsaeng_bag
119 Followers 500 Following Love to utilize geometric insights to deepen our understanding of neural networks. Currently a Master's student @SNU and a research intern @official_naver
Clément Canonne @ccanonne_
31K Followers 927 Following Senior Lecturer @Sydney_Uni. Postdocs @IBMResearch, @Stanford; PhD @Columbia. Converts ☕ into puns: sometimes theorems. He/him. @[email protected]
Gautam Kamath @thegautamkamath
44K Followers 505 Following Assistant Prof of CS @UWaterloo, Faculty @VectorInst, Canada @CIFAR_News AI Chair. Co-EiC @TmlrOrg. I lead @TheSalonML. Privacy, robustness, machine learning.
Lucas Beyer (bl16) @giffmana
56K Followers 444 Following Researcher (Google DeepMind/Brain in Zürich, ex-RWTH Aachen), Gamer, Hacker, Belgian. Mostly gave up trying mastodon as [email protected]
Rosanne Liu @savvyRL
33K Followers 966 Following Cofounded & running @ml_collective. Host of Deep Learning Classics & Trends. Research at Google DeepMind. DEI/DIA Chair of ICLR & NeurIPS. Writing https://t.co/IbycyGfnDR
Behnam Neyshabur @bneyshabur
18K Followers 689 Following Senior Staff Research Scientist @GoogleDeepMind, Interested in reasoning w. LLMs, traveling & backpacking
Dan Roy @roydanroy
45K Followers 2K Following ML / AI researcher, emphasis on theory. Research Director and Canada CIFAR AI Chair, @VectorInst Professor, @UofT (Statistics/CS)
Jelani Nelson @minilek
22K Followers 184 Following Professor @Berkeley_EECS. Research Scientist (part-time) @GoogleAI. Founder @addiscoder. 🇻🇮🇺🇸🇪🇹
Percy Liang @percyliang
49K Followers 408 Following Associate Professor in computer science @Stanford @StanfordHAI @StanfordCRFM @StanfordAILab @stanfordnlp | cofounder @togethercompute | Pianist
Kevin Patrick Murphy @sirbayes
42K Followers 334 Following Research Scientist at Google Brain / Deepmind. Interested in Bayesian Machine Learning.
Kyunghyun Cho @kchonyc
61K Followers 2K Following a combination of a mediocre scientist, a mediocre manager, a mediocre advisor & a mediocre PC at @nyuniversity (@CILVRatNYU) & @genentech (@PrescientDesign).
Boaz Barak @boazbaraktcs
17K Followers 418 Following Computer Scientist. See also https://t.co/EXWR5k634w, https://t.co/SEVX6it6z3 ( @[email protected] , boaz.barak in threads ). Opinions my own.
Eric Jang @ericjang11
69K Followers 3K Following physical AGI at 1X. Author of "AI is Good for You" https://t.co/eFg4WXhg0p
Shreya Shankar @sh_reya
39K Followers 589 Following I study ML & AI engineers and try to make their lives a little better. PhD-ing in databases & HCI @Berkeley_EECS @UCBEPIC and MLOps-ing around town. She/they.
Tom Goldstein @tomgoldsteincs
23K Followers 2K Following Professor at UMD. AI security & privacy, algorithmic bias, foundations of ML. Follow me for commentary on state-of-the-art AI.
rohan anil @_arohan_
12K Followers 2K Following Principal Engineer, @GoogleDeepMind Gemini. prev PaLM-2. Tinkering with optimization and distributed systems. opinions are my own.
Jia-Bin Huang @jbhuang0604
51K Followers 285 Following Associate Professor @umdcs; Part-time Research Scientist @Meta. I like pixels.
Jonathan Frankle @jefrankle
16K Followers 685 Following Chief Scientist, Neural Networks @Databricks via MosaicML. PhD @MIT_CSAIL. BS/MS @PrincetonCS. DC area native. Making AI efficient for everyone at @DbrxMosaicAI
Ben Recht @beenwrekt
26K Followers 363 Following optimization. machine learning. uc berkeley. I blog at https://t.co/fkJujOPsJb The world won't end.
NeurIPS Conference @NeurIPSConf
111K Followers 35 Following New Orleans, Dec 10-16, 23. https://t.co/ga8aOw615g Tweets to this account are not monitored. Please send feedback to [email protected].
Zachary Lipton @zacharylipton
59K Followers 2K Following Professor: CMU/@acmi_lab, CTO / CSO: @AbridgeHQ, Creator: @d2l_ai & https://t.co/QQt98VNLUp, Relapsing 🎷
Laura Cunningham @PaleoLaura
5K Followers 5K Following Biologist trained in the Grinnell field method, UC Berkeley. California Director Western Watersheds Project, B&RW, https://t.co/PgqZC9V2fW
Heatloss @heatloss1986
5K Followers 288 Following Cold War Air Power and other related topics | Heatloss on most other platforms | @heatloser

kelsey mckinney @mckinneykelsey
95K Followers 2K Following co-owner @defectormedia, author of GOD SPARE THE GIRLS. host of NORMAL GOSSIP.
Maya Benowitz 🌱 @cosmicfibretion
17K Followers 1K Following mathematical physicist lost in a liminal space of events to take humanity toward the singularity of knowledge. aspiring tardis engineer and time lord.
Daniel Kane @aladkeenin
9 Followers 15 Following
Ben Edelman @EdelmanBen
112 Followers 20 Following Final-year PhD candidate at Harvard CS trying to understand AI scientifically. New to the platform formerly known as Twitter.
Gustaf Ahdritz @gahdritz
598 Followers 128 Following ML Foundations Group @hseas. Previously @MoAlQuraishi's lab @Columbia.
Simo Ryu @cloneofsimo
3K Followers 383 Following #KAIST RAI Lab (ML engineering #Naver) Interested in robotics, RL, math (but you might know me for t2i diffusion) [email protected]

Tor Erlend Fjelde @torfjelde
406 Followers 146 Following PhD student in machine learning @CambridgeMLG @Cambridge_Uni. Contributor to @TuringLang. Mastodon: @[email protected]
Andrew Sanchez @avincentsanchez
311 Followers 142 Following COO and Co-Founder at @udiomusic | Oxford DPhil | Harvard
Yaroslav Ganin @yaroslav_ganin
4K Followers 230 Following Co-Founder @udiomusic. Research Scientist. Previously: @DeepMindAI, Mila (Montréal, Canada), Skoltech (Moscow, Russia). Views are my own.
DavidDing @DavidDing
50 Followers 0 Following


udio @udiomusic
28K Followers 0 Following
Michal Feldman @MichalFeldman9
2K Followers 239 Following Professor of Computer Science, @TelAvivUni | @AcmSIGecom Chair | Research areas: Econ&CS, Algorithmic Game Theory, Market Design
Martin Shkreli (e/acc.. @MartinShkreli
166K Followers 3K Following https://t.co/lzin5ByH0t [email protected] https://t.co/oMIiyJcIzk https://t.co/DuU6MMqcgQ
Michael Albergo @msalbergo
2K Followers 1K Following Incoming junior fellow at the Society of Fellows at @Harvard and @iaifi_news fellow at MIT, recently PhD'd from @NYUniversity (he/him)

Jess Sorrell @JessSorrell
205 Followers 396 Following CS postdoc at Penn. Interested in theory of ML and responsible computing. All cat pictures are my own and do not represent the cats of my employer.
Jaana Dogan ヤナ �.. @rakyll
114K Followers 1K Following Distinguished Engineer at GitHub, working on Copilot. Previously Google, AWS, and several small companies. Personal opinions.
Simon Pepin Lehalleur @plain_simon
3K Followers 5K Following Mathematician (algebraic geometry, motives & friends, singularity theory and ML). 'Geometry is successful magic' (R. Thom) University of Amsterdam. He/Him
Alex Schwing @alexschwing
990 Followers 178 Following Associate Professor @ECEILLINOIS @IllinoisCS, working on Computer Vision and Machine Learning
Jalaj Upadhyay @jalajupadhyay
631 Followers 353 Following Assistant Professor @Rutgers. Previously, privacy researcher @Apple, postdoc at @JohnsHopkins, @PennState, and a PhD student @UWaterloo
Zhengyang Geng @ZhengyangGeng
617 Followers 590 Following PhD student @SCSatCMU with @zicokolter / Prev. Intern @Meta / Curiosity&Love / Dynamics to ASI
Michael Ashcroft @m_ashcroft
16K Followers 1K Following clear intentions, lightly held ᐧ awareness whisperer ᐧ I teach Alexander Technique, which helps you get out of your own way, at https://t.co/e0qcOYJBfG
Karthik Elamvazhuthi .. @Karthikvaz
74 Followers 36 Following Postdoctoral scholar at University of California, Riverside Preacher of probability density control for everything, from tossing pancakes to conjuring Pikachus
Anand Gopalakrishnan @agopal42
232 Followers 470 Following PhD student at The Swiss AI Lab (IDSIA) with @SchmidhuberAI
The Iditarod @The_Iditarod
11K Followers 107 Following Official Iditarod account. A sled dog race, running from Anchorage to Nome Alaska, covering 1000 miles of the roughest, most beautiful terrain. #IditarodNation
HIDEO_KOJIMA @HIDEO_KOJIMA_EN
3.8M Followers 246 Following Game Creator: 70% of my body is made of movies.

Damien Teney @DamienTeney
1K Followers 431 Following Research Scientist @ Idiap Research Institute. @Idiap_ch Adjunct lecturer @ Australian Institute for ML. @TheAIML Occasionally cycling across continents.
Andrey Gromov @Andr3yGR
122 Followers 124 Following Meta FAIR Research Scientist & physics professor at University of Maryland, College Park
Tim Duignan @TimothyDuignan
946 Followers 2K Following Modelling and simulation of electrolyte solutions using quantum chemistry, stat mech and neural nets. #compchem #theochem
sarah guo // convicti.. @saranormous
91K Followers 3K Following startup investor and builder, founder @w_conviction. accelerating AI adoption, interested in progress. tech podcast: @nopriorspod
VeryBritishProblems @SoVeryBritish
3.9M Followers 1 Following For everything VBP, including books, clothes, mugs, cards, calendars & contact: https://t.co/51E7az46a4 Written by @RobTemple101
Ruiqi Zhang @RuiqiZhang0614
231 Followers 621 Following
Arnaud Pannatier @ArnaudPannatier
412 Followers 235 Following PhD Student @francoisfleuret 's Machine Learning Group Idiap Research Institute - @Idiap_ch EDIC EPFL - @EPFL_en
Xavier Bresson @xbresson
13K Followers 857 Following Prof @NUSingapore Distinguished Researcher @DiscoverElement #NRF Fellow, #GraphNNs #LLMs #DeepLearningTheory #MolecularMaterialScience #Teaching Opinions my own
Kairo @Kairo_Anatomika
26K Followers 128 Following I ❤ anatomy, pathology, teratology and I have so many goddamn questions
Yen-Huan Li @yenhuan_li
2K Followers 534 Following Associate professor in CS @ National Taiwan University. PhD in CS from EPFL. Learning, optimization, statistics, and some quantum information.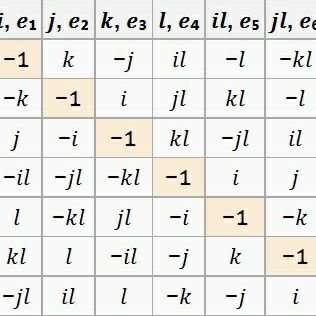
Ben Schulz @schulzb589
1K Followers 5K Following 3D Geospatial Analyst at Maxar Space Operations. Opinions expressed on this site are my own and do not necessarily represent the views of Maxar Technologies.
Qing Qu @Qing_Qu_1006
724 Followers 417 Following Assistant Professor at Umich ECE. Research interest: machine learning, optimization, data science. A runner 🏃 in spare time.
Nikolay Savinov 🇺�.. @SavinovNikolay
1K Followers 0 Following Research Scientist at @GoogleDeepMind Work on LLM pre-training in Gemini ♊ 10M context length in Gemini 1.5 Pro 📈


Martin Shkreli (e/acc.. @wagieeacc
99K Followers 8K Following despite all my ragie I'm still just a wagie in a cagie working on DL Software: https://t.co/FVn3NRNrLe https://t.co/CgaoMfhUHd
Tyler Zhu @tyleryzhu
847 Followers 731 Following PhD student @Princeton @VisualAILab, prev @berkeley_ai @BerkeleyML. @Accel scholar and @SFGiants @warriors fan. food fanatic, coffee connoisseur.
If the idea is good, one paper isn’t enough. People don’t pick up on new ideas right away. They don’t see the future you see. You need to teach the future. If you have a new idea, you will have to show people why it’s also a good idea. You teach the future by demonstration. 7/10

day 4096 of not really understanding what explainable and interpretable means

I feel like one thing to keep in mind when { writing critiques of / expressing skepticism about / ... } developments in { ML, AI, ... } is whether you think that learning from data is possible even in principle (as is - rightly or wrongly - common in statistics).

I’m super, super grateful to Janine, Justin, Zoe, and Jack, the colleagues and students who nominated me! This is truly a dream come true ❤️

Hearty congratulations to @rampure_suraj, Lecturer at HDSI UC San Diego, for winning the 2024 Barbara & Paul Saltman Distinguished Teaching Award! 🏆 His stellar teaching methods light the way in data science education. Read here - ow.ly/4r5250RlHpR #HDSI #UCSD #DataScience

~unrelated, but for the stats course which I teach, the lecture materials which I inherited include an early discussion on the passage from "inference" (in the logical sense) to "statistical inference", which I liked. working in statistics, I can forget where the word comes from.

I will never get over how AI/ML people use the word “inference”

This work was one of the last works that was done by my team when I was working at Apple. A lot of credit to @sacmehtauw whose dedication was the key to this project. Main point behind here is to show as a contributor to the AI community we play our role to be fully open.

Apple presents OpenELM An Efficient Language Model Family with Open-source Training and Inference Framework The reproducibility and transparency of large language models are crucial for advancing open research, ensuring the trustworthiness of results, and


In a new preprint with Jarek Blasiok, @rares_buhai, David Steurer, we show a surprisingly simple greedy algorithm that can list decode planted cliques in the semirandom model at k~sqrt n log^2 n --essentially optimal up to log^2 n. This ~resolves @JacobSteinhardt's open question.
I've some exciting news! Like much of my recent work, also inspired by Uri Feige's conjectures. With Rares Buhai & David Steurer (during a beautiful Zurich summer), we found new algos for semirandom planted clique at thresholds approaching "usual" PC. arxiv.org/abs/2212.05619


Some responses to comments: Q: Why is publishing lots of papers a problem? A: Nobody has time to read them. It's a waste of everyone's time to generate endless numbers of papers. If you really feel like you need to share biweekly updates, consider a blog.

Me: remove that sentence, it doesn't make any sense. Student: The sentence...that you wrote? 🤦

charlesfrye.github.io/stats/2017/11/…


I know lots of various central limit theorems, maxent arguments, convolving arguments, etc. but it’s still so bizarre to me just how universal Gaussian distributions are. Does anyone have intuition for why or interesting constraints that end up being equivalent to the Normal?

GPU gods, grant me the serenity to hard-code the functions deep nets can not learn, the courage to let them learn the ones they can, and the wisdom to know the difference.

Nice!


Our computer vision textbook is released! Foundations of Computer Vision with Antonio Torralba and Bill Freeman mitpress.mit.edu/9780262048972/… It’s been in the works for >10 years. Covers everything from linear filters and camera optics to diffusion models and radiance fields. 1/4

Our computer vision textbook is released! Foundations of Computer Vision with Antonio Torralba and Bill Freeman mitpress.mit.edu/9780262048972/… It’s been in the works for >10 years. Covers everything from linear filters and camera optics to diffusion models and radiance fields. 1/4

Spent my birthday out in the woods working communications support for the Olympus Rally.

hard launching a new HCI paper on LLM evals tomorrow 🚀 (tldr: coming up with custom evals you can trust is _really_ hard, and our paper shares a number of reasons for why)

Working on a little doc to help grad students set quarterly and yearly goals. Are there good examples of this out there already so I don't reinvent the wheel?

Guess who's about to become Rhode Island's #1 Rustacean and #2 document engineer (behind Andy van Dam, ofc). Catch me as an assistant prof at Brown CS in 2025!

There's so much sage wisdom in Terence Tao's blogposts and I love this in particular a lot. terrytao.wordpress.com/career-advice/…


I sometimes worry that I am not paying enough attention to all the exciting things going on with LLM development, but I always conclude that there are plenty of smart people already working on them, and other things are still deserving of effort.

Llama 3 has been my focus since joining the Llama team last summer. Together, we've been tackling challenges across pre-training and human data, pre-training scaling, long context, post-training, and evaluations. It's been a rigorous yet thrilling journey: 🔹Our largest models…


Trends for United States
You might like











