
BerkeleyNLP @BerkeleyNLP
We work on natural language processing, machine learning, linguistics, and deep learning. PIs: Dan Klein, @alsuhr, @sewon__min nlp.cs.berkeley.edu Berkeley, California Joined September 2019-
Tweets112
-
Followers6K
-
Following36
-
Likes114
Happy to announce the first workshop on Pragmatic Reasoning in Language Models — PragLM @ COLM 2025! 🧠🎉 How do LLMs engage in pragmatic reasoning, and what core pragmatic capacities remain beyond their reach? 🌐 sites.google.com/berkeley.edu/p… 📅 Submit by June 23rd
Last day of PhD! I pioneered using LLMs to explain dataset&model. It's used by interp at @OpenAI and societal impact @AnthropicAI Tutorial here. It's a great direction & someone should carry the torch :) Thesis available, if you wanna read my acknowledgement section=P

The long-term goal of AI is to build models that can handle arbitrary tasks, not just ones they’ve been trained on. We hope our new *benchmark generator* can help measure progress toward this vision


The long-term goal of AI is to build models that can handle arbitrary tasks, not just ones they’ve been trained on. We hope our new *benchmark generator* can help measure progress toward this vision https://t.co/hFwiQZdlk6

🎮 Excited to announce gg-bench, a fully synthetic benchmark for LLMs consisting of games generated entirely by LLMs!! This benchmark centers around the fact that LLMs are capable of generating complex tasks that they themselves cannot even solve. 📄: arxiv.org/abs/2505.07215
I'm incredibly excited to share that I'll be joining @TTIC_Connect as an assistant professor in Fall 2026! Until then, I'm wrapping up my PhD at Berkeley, and after that I'll be a faculty fellow at @NYUDataScience
Finished my dissertation!!! (scalable oversight,link below) Very fortunate to have @JacobSteinhardt and Dan Klein as my advisors! Words can't describe my gratitude, so I used a pic of Frieren w/ her advisor :) Thanks for developing my research mission, and teaching me magic


🧵Introducing LangProBe: the first benchmark testing where and how composing LLMs into language programs affects cost-quality tradeoffs! We find that, on avg across diverse tasks, smaller models within optimized programs beat calls to larger models at a fraction of the cost.

Induction heads are commonly associated with in-context learning, but are they the primary driver of ICL at scale? We find that recently discovered "function vector" heads, which encode the ICL task, are the actual primary drivers of few-shot ICL. arxiv.org/abs/2502.14010 🧵

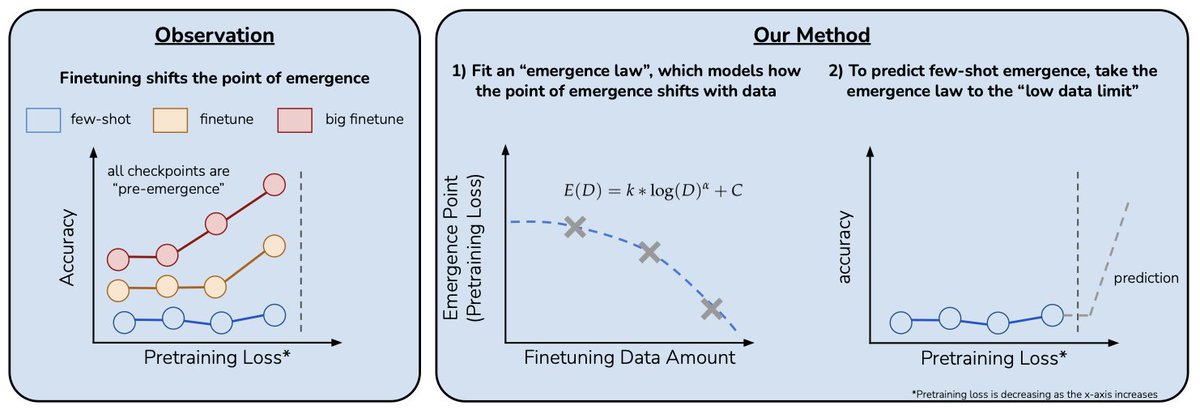
Can we predict emergent capabilities in GPT-N+1🌌 using only GPT-N model checkpoints, which have random performance on the task? We propose a method for doing exactly this in our paper “Predicting Emergent Capabilities by Finetuning”🧵
Cool new dataset for translation ambiguity in 9 language pairs (7 low-resource), and we found LLM-generated descriptions help weaker models resolve ambiguity! @BaruaJosh will be presenting this at the 2-3:30pm poster session today, come talk to us about multilinguality in LLMs!

Cool new dataset for translation ambiguity in 9 language pairs (7 low-resource), and we found LLM-generated descriptions help weaker models resolve ambiguity! @BaruaJosh will be presenting this at the 2-3:30pm poster session today, come talk to us about multilinguality in LLMs!

Do LLMs encode knowledge of concept variation across languages? Can they use this knowledge to resolve ambiguity in translation? Our #EMNLP2024 paper finds a big performance gap between closed- and open-weight LLMs, but lexical rules can help transfer knowledge across models! 🧵
🚨New dataset + challenge #EMNLP2024🚨 We release ASL STEM Wiki: the first signing dataset of STEM articles! 📰 254 Wikipedia articles 📹 ~300 hours of ASL interpretations 👋 New task: automatic sign suggestion to make STEM education more accessible microsoft.com/en-us/research… 🧵
Given the rapid progress of LLMs, I feel compelled to present this topic (even if it's not the main focus of my Ph.D. work). I will cover concrete ML problems related to "AI deception" -- undesirable behaviors of AI systems that are hard to catch -- and how to study this…
Given the rapid progress of LLMs, I feel compelled to present this topic (even if it's not the main focus of my Ph.D. work). I will cover concrete ML problems related to "AI deception" -- undesirable behaviors of AI systems that are hard to catch -- and how to study this…

Graphical models struggle to explain patterns in text & images 😭 LLM can do this but hallucinates. 👿 It’s time to combine their strengths! We define models with natural language parameters! Unlocking opportunities in science, business, ML, etc

A central concern in alignment is that AI systems will "deceive" humans by doing what looks correct to humans but is actually wrong. While a lot of works are motivated by this assumption, we lack empirical evidence. Our work shows systematic evidence that this concern is real

A central concern in alignment is that AI systems will "deceive" humans by doing what looks correct to humans but is actually wrong. While a lot of works are motivated by this assumption, we lack empirical evidence. Our work shows systematic evidence that this concern is real

large mental model update after working on this project 1. Even when LLM does not know what's correct, it can still learn to assist humans to finish the task 2. sometimes LLMs are even better than humans at distinguishing what is helpful for humans (!)
large mental model update after working on this project 1. Even when LLM does not know what's correct, it can still learn to assist humans to finish the task 2. sometimes LLMs are even better than humans at distinguishing what is helpful for humans (!)

On difficult problems, humans can think longer to improve their decisions. Can we instill a similar capability into LLMs? And can it do well? In our paper, we find that by optimally scaling test-time compute we can outperform *much* larger models in a FLOPs matched evaluation.

New preprint! 📰 Can LMs be improved with AlphaGo-style self-play? The classic answer is that self-play only works in certain types of zero-sum games, but we show that it can be effective in cooperative games too Paper: arxiv.org/abs/2406.18872 Code: github.com/nickatomlin/lm…

Spoken languages exhibit communicative efficiency by minimizing speaker+listener effort. What about signed languages? American Sign Language handshapes reflect efficiency pressures - but only in native signs, not signs borrowed from English! #ACL2024 arxiv.org/abs/2406.04024 🧵


📝Presenting ThoughtSculpt - a general reasoning & search approach for tasks with decomposable outputs. Leveraging Monte Carlo Tree Search, it surpasses existing methods across diverse tasks! (1/N) arxiv: arxiv.org/abs/2404.05966


Akari Asai @AkariAsai
19K Followers 870 Following Incoming Assistant Professor @SCSatCMU & research scientist @allen_ai. akariasai @ 🦋
Sam Bowman @sleepinyourhat
50K Followers 3K Following AI alignment + LLMs at Anthropic. On leave from NYU. Views not employers'. No relation to @s8mb. I think you should join @givingwhatwecan.
Delip Rao e/σ @deliprao
62K Followers 5K Following Busy inventing the shipwreck. @Penn. Past: @johnshopkins, @UCSC, @Amazon, @Twitter ||Art: #NLProc, Vision, Speech, #DeepLearning || Life: 道元, improv, running 🌈
Yoav Artzi @yoavartzi
17K Followers 182 Following Research/prof @cs_cornell + @cornell_tech🚡 / https://t.co/9YnWry7yHs / asso. faculty director @arxiv / building https://t.co/nwrbEuwfaK and @COLM_conf
Danish Pruthi @danish037
11K Followers 706 Following Faculty at the Indian Institute of Science, Bangalore. PhD from @LTIatCMU.
Kayo Yin @kayo_yin
15K Followers 697 Following PhD student @berkeley_ai @berkeleynlp. AI alignment & signed languages. Prev @carnegiemellon @polytechnique, intern @msftresearch @deepmind. 🇫🇷🇯🇵
Bill Yuchen Lin @billyuchenlin
25K Followers 3K Following Grok Code @xAI. Ex: Affiliate Assistant Prof @UW, Research Scientist @allen_ai, Google AI, Meta FAIR.
Shruti Rijhwani @shrutirij
7K Followers 556 Following * Research Scientist @GoogleDeepMind * #NLProc research * PhD from @LTIatCMU * Amateur woodworker, scuba diver, foosball player
Tim Dettmers @Tim_Dettmers
39K Followers 994 Following Creator of bitsandbytes.Research Scientist @allen_ai and incoming professor @CarnegieMellon. I blog about deep learning and PhD life at https://t.co/Y78KDJJFE7.
Sewon Min @sewon__min
14K Followers 819 Following Assistant professor @Berkeley_EECS @berkeley_ai || Research scientist at @allen_ai || PhD from @uwcse @uwnlp
Ofir Press @OfirPress
15K Followers 7K Following I build tough benchmarks for LMs and then I get the LMs to solve them. SWE-bench & SWE-agent. Postdoc @Princeton. PhD @nlpnoah @UW.
Naomi Saphra @nsaphra
10K Followers 1K Following Waiting on a robot body. All opinions are universal and held by both employers and family. Now a dedicated grok hate account. Accepting ML/NLP PhD students.
Christopher Potts @ChrisGPotts
14K Followers 649 Following Stanford Professor of Linguistics and, by courtesy, of Computer Science. Member of technical staff @stanfordnlp and @StanfordAILab. Co-founder @ Bigspin AI.
Sebastian Ruder @ ACL @seb_ruder
93K Followers 1K Following Research Scientist @AIatMeta • Ex @Cohere @GoogleDeepMind
Mike Lewis @ml_perception
8K Followers 242 Following Llama3 pre-training lead. Partially to blame for things like the Cicero Diplomacy bot, BART, RoBERTa, kNN-LM, top-k sampling & Deal Or No Deal.
Shaily @shaily99
7K Followers 2K Following PhD @LTIatCMU. Prev: @allen_ai @GoogleAI @MSFTResearch. #NLProc. Often ranting about research.
Xin Eric Wang @xwang_lk
18K Followers 1K Following Professor @ UCSB (@ucsantabarbara). Head of Research @SimularAI. Director @ucsbcrml. #Multimodal #AgenticAI. AI for Humanity in the long run.
Weijia Shi @WeijiaShi2
9K Followers 1K Following PhD student @uwnlp @allen_ai | Prev @MetaAI @CS_UCLA | 🏠 https://t.co/Q6Mzg8ow2j
Nils Reimers @Nils_Reimers
14K Followers 514 Following VP AI Search @Cohere | ex-huggingface | Creator of SBERT (https://t.co/MKKOMfuQ4C)


FAHMIDA AFRIN @Fahmida_Afrin_
0 Followers 57 Following CSE undergrad | Interested in NLP, LLM safety & security | Aspiring researcher
junggeun @dojunggeun
1 Followers 70 Following

Grace Tran @GraceTran82
3 Followers 111 Following Into the data side of AI. Love working across languages, domains, and data types. Always curious, learning, always open to collaborate on pushing AI forward.

The_Scholar📚🖊�... @Sabiu_Idreees
14 Followers 766 Following
Arc Jax @arcjax7
172 Followers 2K Following
nnnn_cccc @AaakCuuk76318
1 Followers 401 Following
S M Jubaer @sm_jubaer
1 Followers 149 Following
Shuhaib Mehri @ShuhaibMehri
97 Followers 445 Following PhD @siebelschool @ConvAI_UIUC | Previously @IBMResearch @amazon
nelbetancur @nelbetancur_
6K Followers 7K Following art & architectural historian / visual, material & religious culture #nelbetancur
Tsung-Han (Patrick) W... @tsunghan_wu
203 Followers 181 Following CS PhD at @berkeley_ai & @BerkeleySky | Prev: @AIatMeta, @NTU_TW
Nirvana Joshi @nirvana2029
400 Followers 8K Following
云创兽Ai @Auglibof388072
3 Followers 117 Following 💸 dynamic stock investing is my game, dream chaser! thrilled to connect. DM me for options trading! 🎯 #ValueInvesting


Liu He (Helium) @Heliummn
2 Followers 97 Following PhD Applicant (Fall '26) in CSS | Social NLP|SpeechLLM|XAI | MS @StudyatUSTC | B.E @HIT_1920, prev intern. @Baidu_Inc’s ERNIE Bot 🤖🗣️👥

Emma Alpern @emmaalpern
2K Followers 986 Following copyediting, writing, editing To Do // @nymag https://t.co/ZwL1c21Tj9
DPGJiaoTu @DpgTu
43 Followers 813 Following
baybreeze2016 @baybreeze2016
3 Followers 194 Following
Atharva Mehta @atharva20038
0 Followers 26 Following
Cathy Li @CathyLiKernel
1 Followers 36 Following


Nilay Agarwal @NilAga08
43 Followers 130 Following Neuroscience PhD Student @UCBerkeley Passionate about neurons, neural networks and everything in between. Amateur musician. Professional introvert.
Camille @han_zi60291
0 Followers 37 Following
Henry Hong @HenryHong217654
0 Followers 73 Following
TienDat @TienDat011000
3 Followers 269 Following

Sherry Yukinoshita @SherryYuki99299
0 Followers 71 Following まだこの世界は 僕を飼いならして いたいみたいな 望み通りいいだろう? 美しくもがくよ
Justin Palmer @jwp
99 Followers 255 Following
Yorguin J. Mantilla @yjmantilla
127 Followers 2K Following Veneco Squared. Curious. From Venezuela (USB) & Colombia (UdeA).
سجين الحب @sh441995
30 Followers 1K Following
kj frost @jkjfrost
0 Followers 4K Following
Renee Narushoff @reneenarushoff
0 Followers 22 Following
ah @abahloul8
0 Followers 55 Following
Peter Li @peterliiiiiii
1 Followers 46 Following
Srija Anand @srija_anand
179 Followers 1K Following MS Student @ AI4Bharat, IIT Madras Volunteer @MAD Chennai IIITD'21
Brian Zheng @s_zhengbr
8 Followers 17 Following Undergraduate at UW CSE. Interested in Natural Language/Music Processing. https://t.co/axy3O3tvfk
조민우 @minwoo_michael
289 Followers 3K Following
TTIC @TTIC_Connect
2K Followers 415 Following Challenging the Foundation of Computer Science. Bluesky: TTICconnect


Lisa @lisah2u
2 Followers 67 Following

Maya Hola @MayaHola169442
45 Followers 277 Following PhD @SHaPS_UCL Loves cats, linguistics, neuroscience, AI and anything cognitive 🧠 Bumblebee keeper 🌼
Shiwei Liu @Shiwei_Liu66
1K Followers 524 Following Hi, I am a PI at ELLIS Institute Tübingen and MPI-IS. Was RS NIF @UniofOxford, JRF @SomervilleOx, postdoc @UTAustin, and PhD @Data_AI_TUe.
AryaFin @AryaFintech
7K Followers 363 Following AryaFin is an ML/AI FinTech platform that identifies companies for investment. It provides real-time stock and market data along with daily market analysis.
Percy Liang @percyliang
85K Followers 420 Following Associate Professor in computer science @Stanford @StanfordHAI @StanfordCRFM @StanfordAILab @stanfordnlp | cofounder @togethercompute | Pianist
Jacob Andreas @jacobandreas
20K Followers 951 Following Teaching computers to read. Assoc. prof @MITEECS / @MIT_CSAIL / @NLP_MIT (he/him). https://t.co/5kCnXHjtlY https://t.co/2A3qF5vdJw
Kayo Yin @kayo_yin
15K Followers 697 Following PhD student @berkeley_ai @berkeleynlp. AI alignment & signed languages. Prev @carnegiemellon @polytechnique, intern @msftresearch @deepmind. 🇫🇷🇯🇵
Sewon Min @sewon__min
14K Followers 819 Following Assistant professor @Berkeley_EECS @berkeley_ai || Research scientist at @allen_ai || PhD from @uwcse @uwnlp
Stanford NLP Group @stanfordnlp
172K Followers 296 Following Computational Linguists—Natural Language—Machine Learning @chrmanning @jurafsky @percyliang @ChrisGPotts @tatsu_hashimoto @MonicaSLam @Diyi_Yang @StanfordAILab
Prasann Singhal @prasann_singhal
299 Followers 749 Following 1st-year #NLProc PhD at UC Berkeley working with @sewon__min / @JacobSteinhardt , formerly advised by @gregd_nlp
Ryan Yixiang Wang @RyanYixiang
108 Followers 628 Following 4th year undergrad in @nlp_usc working with @robinomial and @swabhz

Alane Suhr @alsuhr
2K Followers 649 Following Mostly gone to better places :) I like language, birds, cats, trains, buses, long walks, cities, and other things 🌻 "vulnerable road user" opinions mine
Eve Fleisig @enfleisig
662 Followers 392 Following PhD student @Berkeley_EECS | Princeton ‘21 | NLP, ethical + equitable AI, and sociolinguistics enthusiast
Zineng Tang @ZinengTang
2K Followers 575 Following PhD in @Berkeley_ai and @BerkeleyNLP. Previously @UNCNLP and @MSFTResearch.
Jiayi Pan @jiayi_pirate
13K Followers 2K Following 🧑🍳 Reasoning Agents @xAI | PhD on Leave @Berkeley_AI | Views Are My Own
Alexander Wan @alexwan55
704 Followers 1K Following Studying CS at Berkeley; doing research on evals & public policy at Stanford CRFM; @BerkeleyML @BerkeleyNLP; https://t.co/YqhKUqpSBW
Sanjay Subramanian @sanjayssub
903 Followers 575 Following Building/analyzing NLP and vision models. PhD student @berkeley_ai. Formerly: @allen_ai, @penn
Arnav Gudibande @arnavg_
603 Followers 322 Following Research Engineer @perplexity_ai | prev MS @berkeley_ai @berkeleyNLP

Charlie Snell @sea_snell
8K Followers 6K Following PhD student @berkeley_ai; research @cursor_ai; prev @GoogleDeepMind. My friend told me to tweet more. I stare at my computer a lot and make things

Jessy Lin @realJessyLin
3K Followers 887 Following PhD @Berkeley_AI, visiting researcher @AIatMeta. Interactive language agents 🤖 💬
Jane Wakefield @janewakefield
8K Followers 1K Following I write about tech and have done for two decades. I also make pods, speak at conferences, and offer media training and consultancy under my 🍌🦔 brand.
Kevin Yang @kevinyang41
489 Followers 187 Following Research scientist at @scaledcognition, previously PhD at @BerkeleyNLP, interested in better control and factuality for LLM outputs especially for long context.
Kevin Lin 林冠言 @nlpkevinl
483 Followers 307 Following research @Letta_AI @berkeleynlp @ucbrise @ai2_allennlp

Daniel Fried @dan_fried
4K Followers 866 Following Assistant prof. @LTIatCMU @SCSatCMU. Working on NLP: LLM agents, language-to-code, applied pragmatics, grounding.
Jonathan K. Kummerfel... @jkkummerfeld
2K Followers 396 Following NLP faculty - University of Sydney he/him (this account is for professional topics only)
David Hall @dlwh
3K Followers 1K Following Research Engineering Lead at @StanfordCRFM. Previously co-founder at Semantic Machines ⟶ MSFT. Lead developer of Levanter and Marin @[email protected]
Ruiqi Zhong @ZhongRuiqi
6K Followers 739 Following Member of Technical Staff at Thinking Machines. Human+AI collaboration. Scalable Oversight. Explainability. Prev @AnthropicAI PhD UC Berkeley'25; Columbia'19
Rodolfo (Rudy) Corona @_rodolfocorona_
298 Followers 499 Following PhD student at @berkeley_ai and @BerkeleyNLP| Interested in language, embodiment, abstraction, and compositionality | 🇲🇽
Berkeley AI Research @berkeley_ai
228K Followers 378 Following We're graduate students, postdocs, faculty and scientists at the cutting edge of artificial intelligence research.
Lucy Li @lucy3_li
5K Followers 2K Following Postdoc @uwnlp. Incoming assistant prof @WisconsinCS. Prev @UCBerkeley, @allen_ai, @MSFTResearch, @stanfordnlp. More silly at https://t.co/rtSSUhWQnL.
Taylor Berg-Kirkpatri... @BergKirkpatrick
648 Followers 253 Following
Mohit Bansal @mohitban47
11K Followers 722 Following Parker Distinguished Prof @UNC. PECASE/AAAI Fellow. Director https://t.co/5qlPVgnrlN (@unc_ai_group). Past @Berkeley_AI @TTIC_Connect @IITKanpur #NLP #CV #AI
Greg Durrett @gregd_nlp
8K Followers 893 Following Associate professor at NYU (Courant CS + Center for Data Science) | advisor for @bespokelabsai | large language models and NLP | he/him
Jason Eisner @adveisner
8K Followers 558 Following Professor of CS at Johns Hopkins University, ACL Fellow. My tweets speak only for me.
Nicholas Tomlin @NickATomlin
1K Followers 772 Following Incoming assistant professor at TTIC, current faculty fellow at NYU CDS, and previous PhD student at Berkeley. Natural language processing. He/him.
Trends for United States
You might like













